 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Driven Graph Attention for Hierarchical Relational Object Navigation
Jun 23, 2023

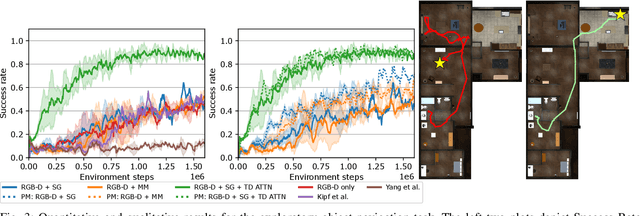

Embodied AI agents in large scenes often need to navigate to find objects. In this work, we study a naturally emerging variant of the object navigation task, hierarchical relational object navigation (HRON), where the goal is to find objects specified by logical predicates organized in a hierarchical structure - objects related to furniture and then to rooms - such as finding an apple on top of a table in the kitchen. Solving such a task requires an efficient representation to reason about object relations and correlate the relations in the environment and in the task goal. HRON in large scenes (e.g. homes) is particularly challenging due to its partial observability and long horizon, which invites solutions that can compactly store the past information while effectively exploring the scene. We demonstrate experimentally that scene graphs are the best-suited representation compared to conventional representations such as images or 2D maps. We propose a solution that uses scene graphs as part of its input and integrates graph neural networks as its backbone, with an integrated task-driven attention mechanism, and demonstrate its better scalability and learning efficiency than state-of-the-art baselines.
Modeling Dynamic Environments with Scene Graph Memory
Jun 12, 2023Embodied AI agents that search for objects in large environments such as households often need to make efficient decisions by predicting object locations based on partial information. We pose this as a new type of link prediction problem: link prediction on partially observable dynamic graphs. Our graph is a representation of a scene in which rooms and objects are nodes, and their relationships are encoded in the edges; only parts of the changing graph are known to the agent at each timestep. This partial observability poses a challenge to existing link prediction approaches, which we address. We propose a novel state representation -- Scene Graph Memory (SGM) -- with captures the agent's accumulated set of observations, as well as a neural net architecture called a Node Edge Predictor (NEP) that extracts information from the SGM to search efficiently. We evaluate our method in the Dynamic House Simulator, a new benchmark that creates diverse dynamic graphs following the semantic patterns typically seen at homes, and show that NEP can be trained to predict the locations of objects in a variety of environments with diverse object movement dynamics, outperforming baselines both in terms of new scene adaptability and overall accuracy. The codebase and more can be found at https://www.scenegraphmemory.com.
Saved You A Click: Automatically Answering Clickbait Titles
Dec 15, 2022Often clickbait articles have a title that is phrased as a question or vague teaser that entices the user to click on the link and read the article to find the explanation. We developed a system that will automatically find the answer or explanation of the clickbait hook from the website text so that the user does not need to read through the text themselves. We fine-tune an extractive question and answering model (RoBERTa) and an abstractive one (T5), using data scraped from the 'StopClickbait' Facebook pages and Reddit's 'SavedYouAClick' subforum. We find that both extractive and abstractive models improve significantly after finetuning. We find that the extractive model performs slightly better according to ROUGE scores, while the abstractive one has a slight edge in terms of BERTscores.
Error-Aware Imitation Learning from Teleoperation Data for Mobile Manipulation
Dec 09, 2021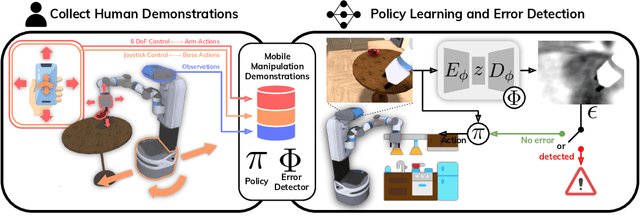
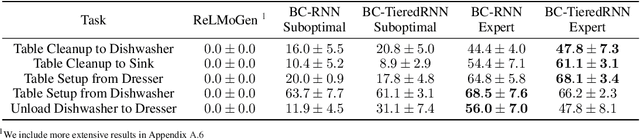

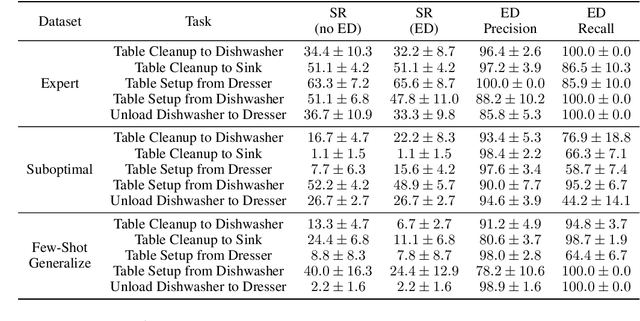
In mobile manipulation (MM), robots can both navigate within and interact with their environment and are thus able to complete many more tasks than robots only capable of navigation or manipulation. In this work, we explore how to apply imitation learning (IL) to learn continuous visuo-motor policies for MM tasks. Much prior work has shown that IL can train visuo-motor policies for either manipulation or navigation domains, but few works have applied IL to the MM domain. Doing this is challenging for two reasons: on the data side, current interfaces make collecting high-quality human demonstrations difficult, and on the learning side, policies trained on limited data can suffer from covariate shift when deployed. To address these problems, we first propose Mobile Manipulation RoboTurk (MoMaRT), a novel teleoperation framework allowing simultaneous navigation and manipulation of mobile manipulators, and collect a first-of-its-kind large scale dataset in a realistic simulated kitchen setting. We then propose a learned error detection system to address the covariate shift by detecting when an agent is in a potential failure state. We train performant IL policies and error detectors from this data, and achieve over 45% task success rate and 85% error detection success rate across multiple multi-stage tasks when trained on expert data. Codebase, datasets, visualization, and more available at https://sites.google.com/view/il-for-mm/home.
iGibson 2.0: Object-Centric Simulation for Robot Learning of Everyday Household Tasks
Aug 10, 2021



Recent research in embodied AI has been boosted by the use of simulation environments to develop and train robot learning approaches. However, the use of simulation has skewed the attention to tasks that only require what robotics simulators can simulate: motion and physical contact. We present iGibson 2.0, an open-source simulation environment that supports the simulation of a more diverse set of household tasks through three key innovations. First, iGibson 2.0 supports object states, including temperature, wetness level, cleanliness level, and toggled and sliced states, necessary to cover a wider range of tasks. Second, iGibson 2.0 implements a set of predicate logic functions that map the simulator states to logic states like Cooked or Soaked. Additionally, given a logic state, iGibson 2.0 can sample valid physical states that satisfy it. This functionality can generate potentially infinite instances of tasks with minimal effort from the users. The sampling mechanism allows our scenes to be more densely populated with small objects in semantically meaningful locations. Third, iGibson 2.0 includes a virtual reality (VR) interface to immerse humans in its scenes to collect demonstrations. As a result, we can collect demonstrations from humans on these new types of tasks, and use them for imitation learning. We evaluate the new capabilities of iGibson 2.0 to enable robot learning of novel tasks, in the hope of demonstrating the potential of this new simulator to support new research in embodied AI. iGibson 2.0 and its new dataset will be publicly available at http://svl.stanford.edu/igibson/.
Semantic and Geometric Modeling with Neural Message Passing in 3D Scene Graphs for Hierarchical Mechanical Search
Dec 07, 2020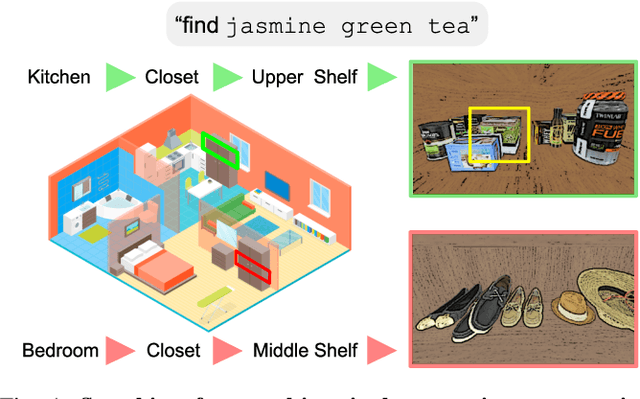
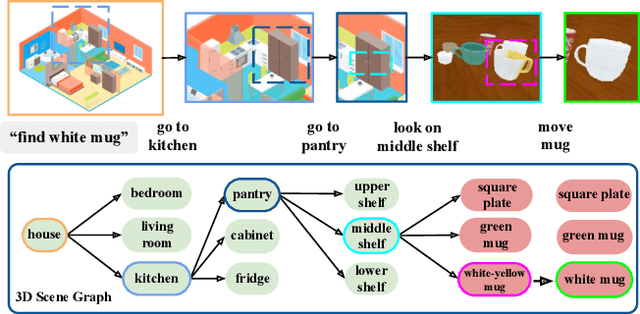
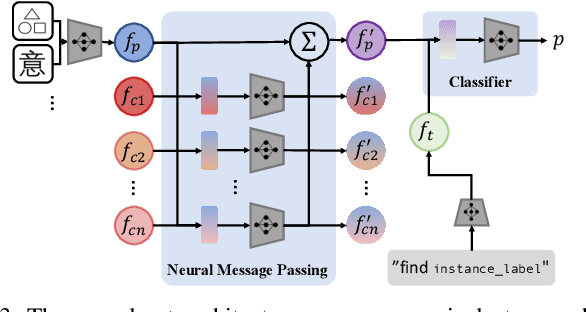
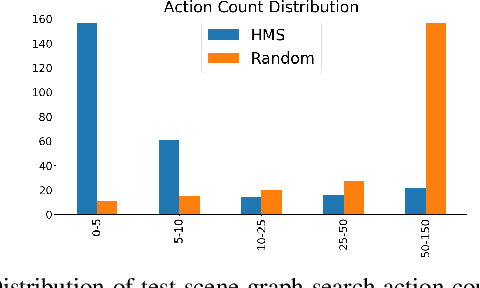
Searching for objects in indoor organized environments such as homes or offices is part of our everyday activities. When looking for a target object, we jointly reason about the rooms and containers the object is likely to be in; the same type of container will have a different probability of having the target depending on the room it is in. We also combine geometric and semantic information to infer what container is best to search, or what other objects are best to move, if the target object is hidden from view. We propose to use a 3D scene graph representation to capture the hierarchical, semantic, and geometric aspects of this problem. To exploit this representation in a search process, we introduce Hierarchical Mechanical Search (HMS), a method that guides an agent's actions towards finding a target object specified with a natural language description. HMS is based on a novel neural network architecture that uses neural message passing of vectors with visual, geometric, and linguistic information to allow HMS to reason across layers of the graph while combining semantic and geometric cues. HMS is evaluated on a novel dataset of 500 3D scene graphs with dense placements of semantically related objects in storage locations, and is shown to be significantly better than several baselines at finding objects and close to the oracle policy in terms of the median number of actions required. Additional qualitative results can be found at https://ai.stanford.edu/mech-search/hms.
Visuomotor Mechanical Search: Learning to Retrieve Target Objects in Clutter
Aug 13, 2020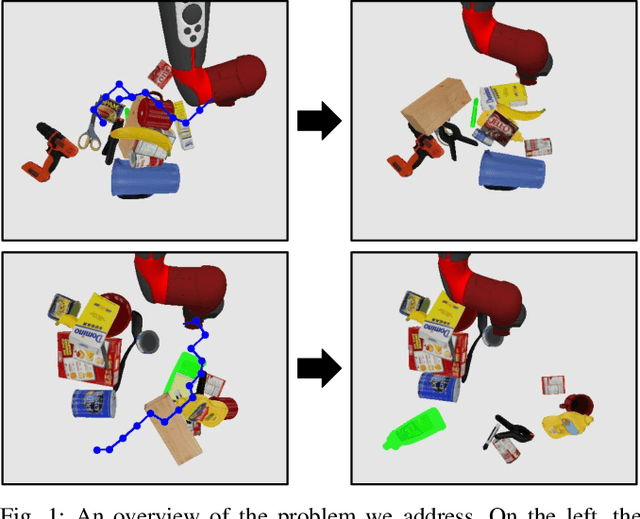
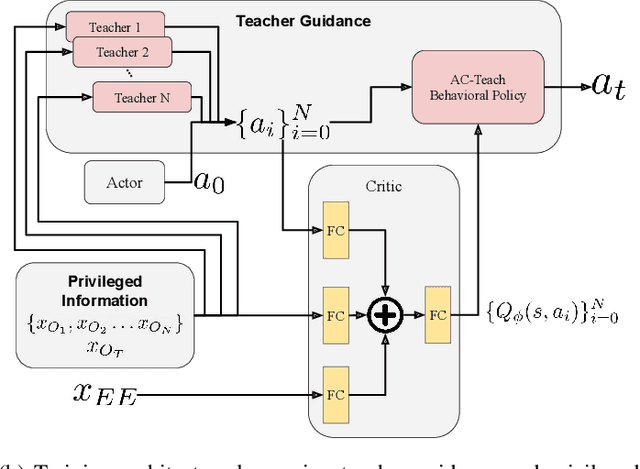
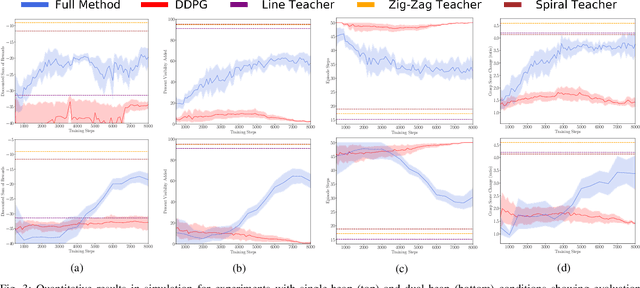
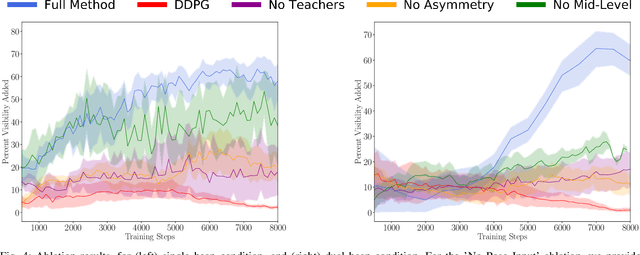
When searching for objects in cluttered environments, it is often necessary to perform complex interactions in order to move occluding objects out of the way and fully reveal the object of interest and make it graspable. Due to the complexity of the physics involved and the lack of accurate models of the clutter, planning and controlling precise predefined interactions with accurate outcome is extremely hard, when not impossible. In problems where accurate (forward) models are lacking, Deep Reinforcement Learning (RL) has shown to be a viable solution to map observations (e.g. images) to good interactions in the form of close-loop visuomotor policies. However, Deep RL is sample inefficient and fails when applied directly to the problem of unoccluding objects based on images. In this work we present a novel Deep RL procedure that combines i) teacher-aided exploration, ii) a critic with privileged information, and iii) mid-level representations, resulting in sample efficient and effective learning for the problem of uncovering a target object occluded by a heap of unknown objects. Our experiments show that our approach trains faster and converges to more efficient uncovering solutions than baselines and ablations, and that our uncovering policies lead to an average improvement in the graspability of the target object, facilitating downstream retrieval applications.
AC-Teach: A Bayesian Actor-Critic Method for Policy Learning with an Ensemble of Suboptimal Teachers
Sep 12, 2019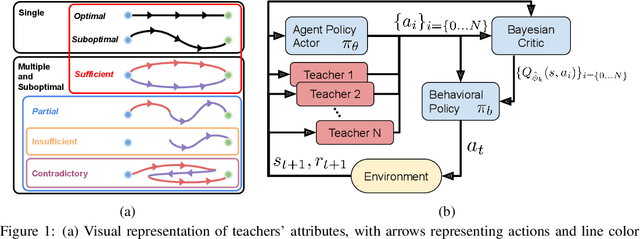

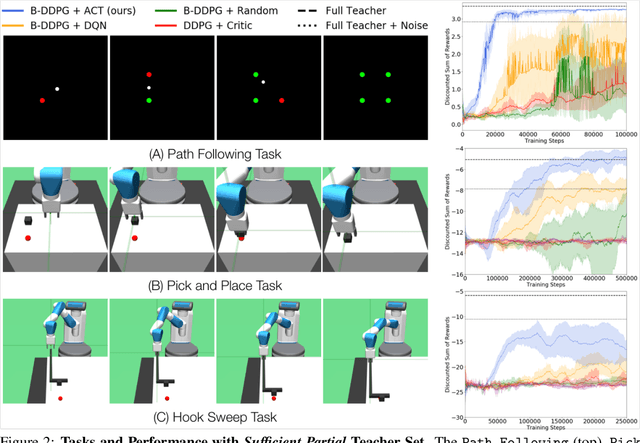
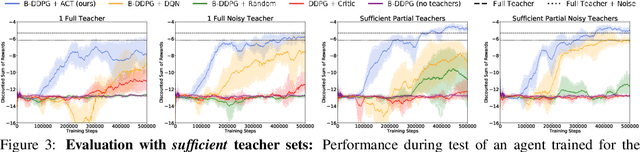
The exploration mechanism used by a Deep Reinforcement Learning (RL) agent plays a key role in determining its sample efficiency. Thus, improving over random exploration is crucial to solve long-horizon tasks with sparse rewards. We propose to leverage an ensemble of partial solutions as teachers that guide the agent's exploration with action suggestions throughout training. While the setup of learning with teachers has been previously studied, our proposed approach - Actor-Critic with Teacher Ensembles (AC-Teach) - is the first to work with an ensemble of suboptimal teachers that may solve only part of the problem or contradict other each other, forming a unified algorithmic solution that is compatible with a broad range of teacher ensembles. AC-Teach leverages a probabilistic representation of the expected outcome of the teachers' and student's actions to direct exploration, reduce dithering, and adapt to the dynamically changing quality of the learner. We evaluate a variant of AC-Teach that guides the learning of a Bayesian DDPG agent on three tasks - path following, robotic pick and place, and robotic cube sweeping using a hook - and show that it improves largely on sampling efficiency over a set of baselines, both for our target scenario of unconstrained suboptimal teachers and for easier setups with optimal or single teachers. Additional results and videos at https://sites.google.com/view/acteach/home.
Mechanical Search: Multi-Step Retrieval of a Target Object Occluded by Clutter
Mar 04, 2019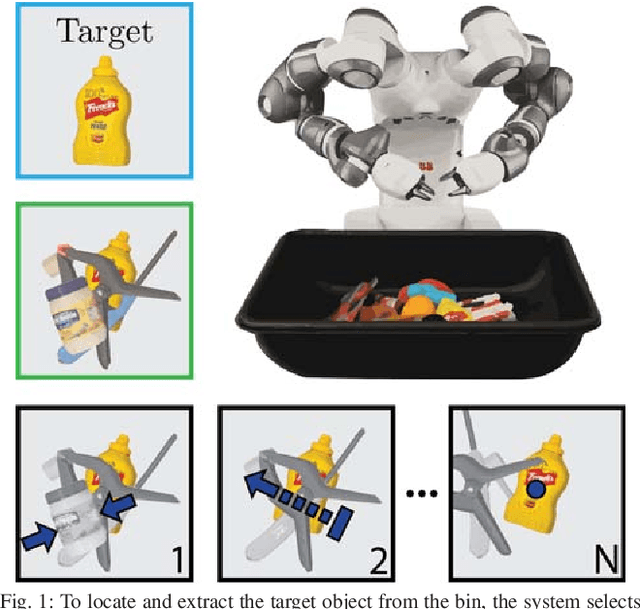
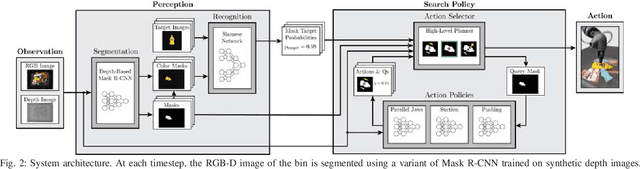
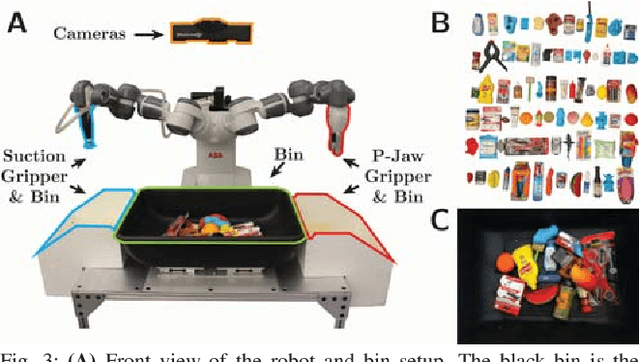
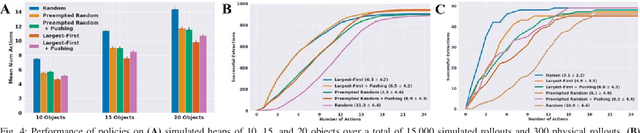
When operating in unstructured environments such as warehouses, homes, and retail centers, robots are frequently required to interactively search for and retrieve specific objects from cluttered bins, shelves, or tables. Mechanical Search describes the class of tasks where the goal is to locate and extract a known target object. In this paper, we formalize Mechanical Search and study a version where distractor objects are heaped over the target object in a bin. The robot uses an RGBD perception system and control policies to iteratively select, parameterize, and perform one of 3 actions -- push, suction, grasp -- until the target object is extracted, or either a time limit is exceeded, or no high confidence push or grasp is available. We present a study of 5 algorithmic policies for mechanical search, with 15,000 simulated trials and 300 physical trials for heaps ranging from 10 to 20 objects. Results suggest that success can be achieved in this long-horizon task with algorithmic policies in over 95% of instances and that the number of actions required scales approximately linearly with the size of the heap. Code and supplementary material can be found at http://ai.stanford.edu/mech-search .
Learning Task-Oriented Grasping for Tool Manipulation from Simulated Self-Supervision
Jun 25, 2018



Tool manipulation is vital for facilitating robots to complete challenging task goals. It requires reasoning about the desired effect of the task and thus properly grasping and manipulating the tool to achieve the task. Task-agnostic grasping optimizes for grasp robustness while ignoring crucial task-specific constraints. In this paper, we propose the Task-Oriented Grasping Network (TOG-Net) to jointly optimize both task-oriented grasping of a tool and the manipulation policy for that tool. The training process of the model is based on large-scale simulated self-supervision with procedurally generated tool objects. We perform both simulated and real-world experiments on two tool-based manipulation tasks: sweeping and hammering. Our model achieves overall 71.1% task success rate for sweeping and 80.0% task success rate for hammering. Supplementary material is available at: bit.ly/task-oriented-grasp