 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanical Search: Multi-Step Retrieval of a Target Object Occluded by Clutter
Mar 04, 2019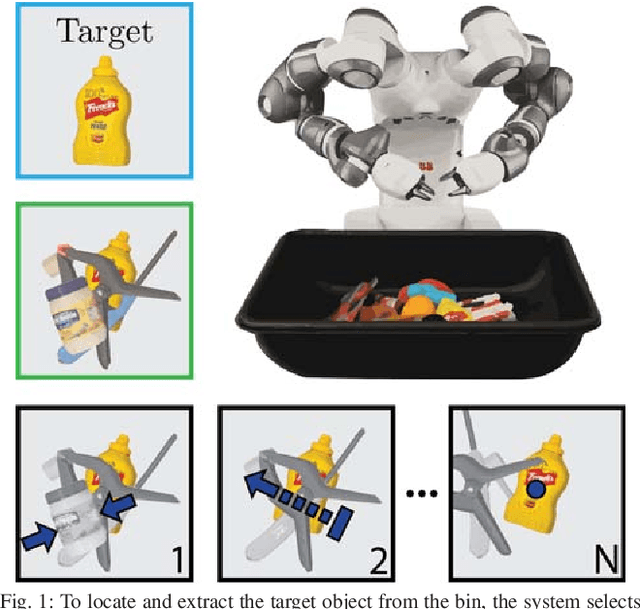
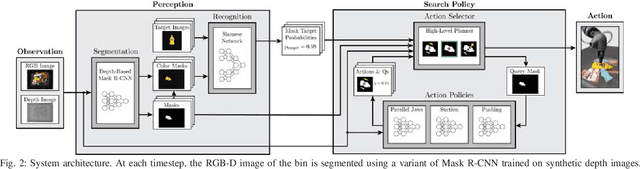
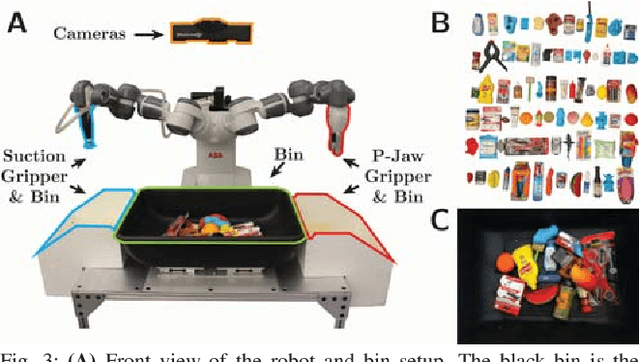
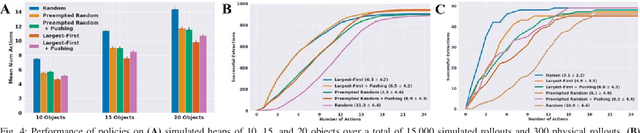
When operating in unstructured environments such as warehouses, homes, and retail centers, robots are frequently required to interactively search for and retrieve specific objects from cluttered bins, shelves, or tables. Mechanical Search describes the class of tasks where the goal is to locate and extract a known target object. In this paper, we formalize Mechanical Search and study a version where distractor objects are heaped over the target object in a bin. The robot uses an RGBD perception system and control policies to iteratively select, parameterize, and perform one of 3 actions -- push, suction, grasp -- until the target object is extracted, or either a time limit is exceeded, or no high confidence push or grasp is available. We present a study of 5 algorithmic policies for mechanical search, with 15,000 simulated trials and 300 physical trials for heaps ranging from 10 to 20 objects. Results suggest that success can be achieved in this long-horizon task with algorithmic policies in over 95% of instances and that the number of actions required scales approximately linearly with the size of the heap. Code and supplementary material can be found at http://ai.stanford.edu/mech-search .
Segmenting Unknown 3D Objects from Real Depth Images using Mask R-CNN Trained on Synthetic Data
Mar 03, 2019



The ability to segment unknown objects in depth images has potential to enhance robot skills in grasping and object tracking. Recent computer vision research has demonstrated that Mask R-CNN can be trained to segment specific categories of objects in RGB images when massive hand-labeled datasets are available. As generating these datasets is time consuming, we instead train with synthetic depth images. Many robots now use depth sensors, and recent results suggest training on synthetic depth data can transfer successfully to the real world. We present a method for automated dataset generation and rapidly generate a synthetic training dataset of 50,000 depth images and 320,000 object masks using simulated heaps of 3D CAD models. We train a variant of Mask R-CNN with domain randomization on the generated dataset to perform category-agnostic instance segmentation without any hand-labeled data and we evaluate the trained network, which we refer to as Synthetic Depth (SD) Mask R-CNN, on a set of real, high-resolution depth images of challenging, densely-cluttered bins containing objects with highly-varied geometry. SD Mask R-CNN outperforms point cloud clustering baselines by an absolute 15% in Average Precision and 20% in Average Recall on COCO benchmarks, and achieves performance levels similar to a Mask R-CNN trained on a massive, hand-labeled RGB dataset and fine-tuned on real images from the experimental setup. We deploy the model in an instance-specific grasping pipeline to demonstrate its usefulness in a robotics application. Code, the synthetic training dataset, and supplementary material are available at https://bit.ly/2letCuE.
Dex-Net 3.0: Computing Robust Robot Vacuum Suction Grasp Targets in Point Clouds using a New Analytic Model and Deep Learning
Apr 13, 2018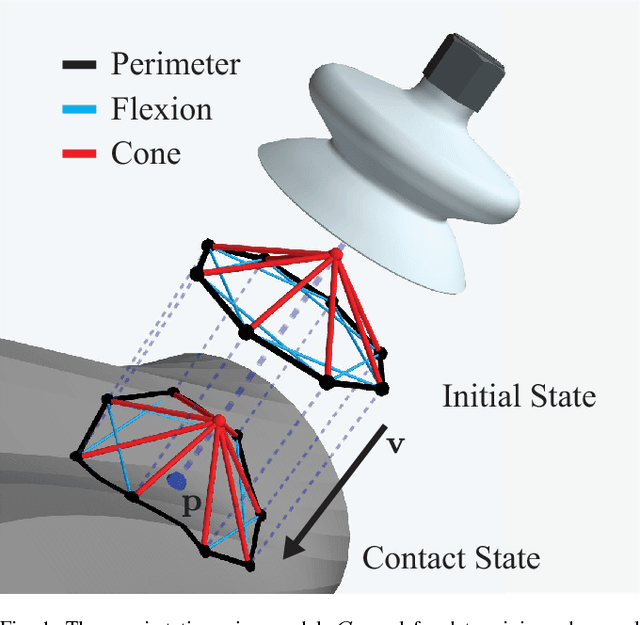
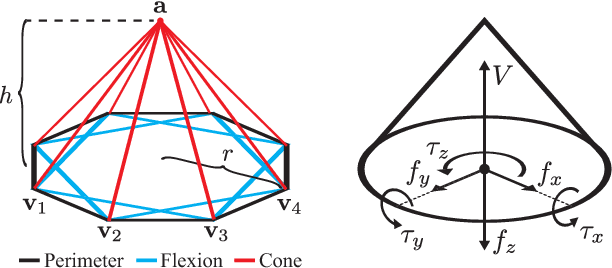
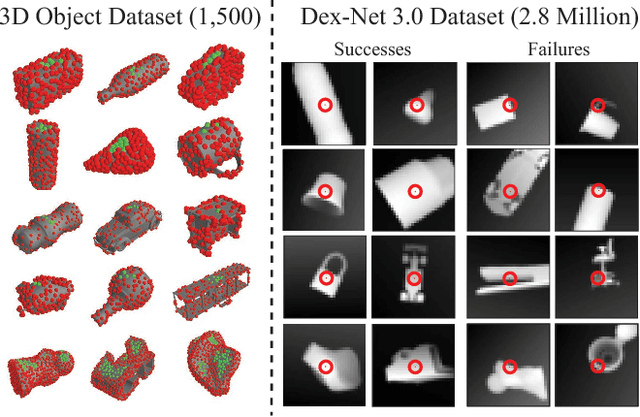

Vacuum-based end effectors are widely used in industry and are often preferred over parallel-jaw and multifinger grippers due to their ability to lift objects with a single point of contact. Suction grasp planners often target planar surfaces on point clouds near the estimated centroid of an object. In this paper, we propose a compliant suction contact model that computes the quality of the seal between the suction cup and local target surface and a measure of the ability of the suction grasp to resist an external gravity wrench. To characterize grasps, we estimate robustness to perturbations in end-effector and object pose, material properties, and external wrenches. We analyze grasps across 1,500 3D object models to generate Dex-Net 3.0, a dataset of 2.8 million point clouds, suction grasps, and grasp robustness labels. We use Dex-Net 3.0 to train a Grasp Quality Convolutional Neural Network (GQ-CNN) to classify robust suction targets in point clouds containing a single object. We evaluate the resulting system in 350 physical trials on an ABB YuMi fitted with a pneumatic suction gripper. When evaluated on novel objects that we categorize as Basic (prismatic or cylindrical), Typical (more complex geometry), and Adversarial (with few available suction-grasp points) Dex-Net 3.0 achieves success rates of 98$\%$, 82$\%$, and 58$\%$ respectively, improving to 81$\%$ in the latter case when the training set includes only adversarial objects. Code, datasets, and supplemental material can be found at http://berkeleyautomation.github.io/dex-net .