 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecantnlp@DravidianLangTech 2026: organic domain adaptation improves multi-class hope speech detection in Tulu
May 10, 2026This paper presents our systems and results for the Hope Speech Detection in Code-Mixed Tulu Language shared task at the Sixth Workshop on Speech, Vision, and Language Technologies for Dravidian Languages (DravidianLangTech-2026). We trained an XLM-RoBERTa-based text classification system for detecting hope speech in code-mixed Tulu social media comments. We compared this organically adapted hope speech detection model with our baseline model. On the development set, the organically adapted model outperformed the baseline system. While our submitted systems performed more modestly on the official test set, these results suggest that further adapting XLM-RoBERTa on organically collected Tulu social media text containing code-mixed and mixed-script variation can improve hope speech detection in code-mixed Tulu.
How Well Can General Vision-Language Models Learn Medicine By Watching Public Educational Videos?
Apr 19, 2025Publicly available biomedical videos, such as those on YouTube, serve as valuable educational resources for medical students. Unlike standard machine learning datasets, these videos are designed for human learners, often mixing medical imagery with narration, explanatory diagrams, and contextual framing. In this work, we investigate whether such pedagogically rich, yet non-standardized and heterogeneous videos can effectively teach general-domain vision-language models biomedical knowledge. To this end, we introduce OpenBiomedVi, a biomedical video instruction tuning dataset comprising 1031 hours of video-caption and Q/A pairs, curated through a multi-step human-in-the-loop pipeline. Diverse biomedical video datasets are rare, and OpenBiomedVid fills an important gap by providing instruction-style supervision grounded in real-world educational content. Surprisingly, despite the informal and heterogeneous nature of these videos, the fine-tuned Qwen-2-VL models exhibit substantial performance improvements across most benchmarks. The 2B model achieves gains of 98.7% on video tasks, 71.2% on image tasks, and 0.2% on text tasks. The 7B model shows improvements of 37.09% on video and 11.2% on image tasks, with a slight degradation of 2.7% on text tasks compared to their respective base models. To address the lack of standardized biomedical video evaluation datasets, we also introduce two new expert curated benchmarks, MIMICEchoQA and SurgeryVideoQA. On these benchmarks, the 2B model achieves gains of 99.1% and 98.1%, while the 7B model shows gains of 22.5% and 52.1%, respectively, demonstrating the models' ability to generalize and perform biomedical video understanding on cleaner and more standardized datasets than those seen during training. These results suggest that educational videos created for human learning offer a surprisingly effective training signal for biomedical VLMs.
cantnlp@DravidianLangTech-2025: A Bag-of-Sounds Approach to Multimodal Hate Speech Detection
Mar 10, 2025



This paper presents the systems and results for the Multimodal Social Media Data Analysis in Dravidian Languages (MSMDA-DL) shared task at the Fifth Workshop on Speech, Vision, and Language Technologies for Dravidian Languages (DravidianLangTech-2025). We took a `bag-of-sounds' approach by training our hate speech detection system on the speech (audio) data using transformed Mel spectrogram measures. While our candidate model performed poorly on the test set, our approach offered promising results during training and development for Malayalam and Tamil. With sufficient and well-balanced training data, our results show that it is feasible to use both text and speech (audio) data in the development of multimodal hate speech detection systems.
SMIR: Efficient Synthetic Data Pipeline To Improve Multi-Image Reasoning
Jan 07, 2025Vision-Language Models (VLMs) have shown strong performance in understanding single images, aided by numerous high-quality instruction datasets. However, multi-image reasoning tasks are still under-explored in the open-source community due to two main challenges: (1) scaling datasets with multiple correlated images and complex reasoning instructions is resource-intensive and maintaining quality is difficult, and (2) there is a lack of robust evaluation benchmarks for multi-image tasks. To address these issues, we introduce SMIR, an efficient synthetic data-generation pipeline for multi-image reasoning, and a high-quality dataset generated using this pipeline. Our pipeline efficiently extracts highly correlated images using multimodal embeddings, combining visual and descriptive information and leverages open-source LLMs to generate quality instructions. Using this pipeline, we generated 160K synthetic training samples, offering a cost-effective alternative to expensive closed-source solutions. Additionally, we present SMIR-BENCH, a novel multi-image reasoning evaluation benchmark comprising 200 diverse examples across 7 complex multi-image reasoning tasks. SMIR-BENCH is multi-turn and utilizes a VLM judge to evaluate free-form responses, providing a comprehensive assessment of model expressiveness and reasoning capability across modalities. We demonstrate the effectiveness of SMIR dataset by fine-tuning several open-source VLMs and evaluating their performance on SMIR-BENCH. Our results show that models trained on our dataset outperform baseline models in multi-image reasoning tasks up to 8% with a much more scalable data pipeline.
EmbedLLM: Learning Compact Representations of Large Language Models
Oct 03, 2024



With hundreds of thousands of language models available on Huggingface today, efficiently evaluating and utilizing these models across various downstream, tasks has become increasingly critical. Many existing methods repeatedly learn task-specific representations of Large Language Models (LLMs), which leads to inefficiencies in both time and computational resources. To address this, we propose EmbedLLM, a framework designed to learn compact vector representations, of LLMs that facilitate downstream applications involving many models, such as model routing. We introduce an encoder-decoder approach for learning such embeddings, along with a systematic framework to evaluate their effectiveness. Empirical results show that EmbedLLM outperforms prior methods in model routing both in accuracy and latency. Additionally, we demonstrate that our method can forecast a model's performance on multiple benchmarks, without incurring additional inference cost. Extensive probing experiments validate that the learned embeddings capture key model characteristics, e.g. whether the model is specialized for coding tasks, even without being explicitly trained on them. We open source our dataset, code and embedder to facilitate further research and application.
Incremental Comprehension of Garden-Path Sentences by Large Language Models: Semantic Interpretation, Syntactic Re-Analysis, and Attention
May 25, 2024



When reading temporarily ambiguous garden-path sentences, misinterpretations sometimes linger past the point of disambiguation. This phenomenon has traditionally been studied in psycholinguistic experiments using online measures such as reading times and offline measures such as comprehension questions. Here, we investigate the processing of garden-path sentences and the fate of lingering misinterpretations using four large language models (LLMs): GPT-2, LLaMA-2, Flan-T5, and RoBERTa. The overall goal is to evaluate whether humans and LLMs are aligned in their processing of garden-path sentences and in the lingering misinterpretations past the point of disambiguation, especially when extra-syntactic information (e.g., a comma delimiting a clause boundary) is present to guide processing. We address this goal using 24 garden-path sentences that have optional transitive and reflexive verbs leading to temporary ambiguities. For each sentence, there are a pair of comprehension questions corresponding to the misinterpretation and the correct interpretation. In three experiments, we (1) measure the dynamic semantic interpretations of LLMs using the question-answering task; (2) track whether these models shift their implicit parse tree at the point of disambiguation (or by the end of the sentence); and (3) visualize the model components that attend to disambiguating information when processing the question probes. These experiments show promising alignment between humans and LLMs in the processing of garden-path sentences, especially when extra-syntactic information is available to guide processing.
Deep Few-view High-resolution Photon-counting Extremity CT at Halved Dose for a Clinical Trial
Mar 19, 2024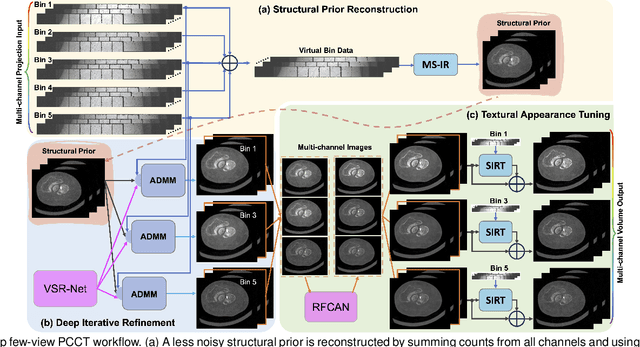
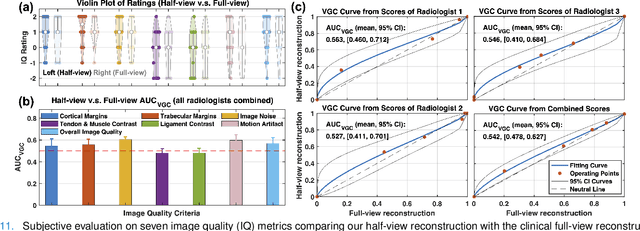
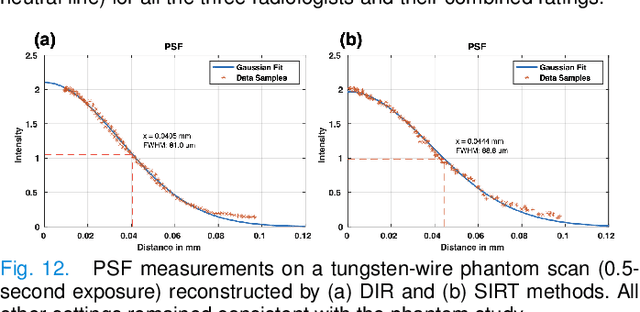
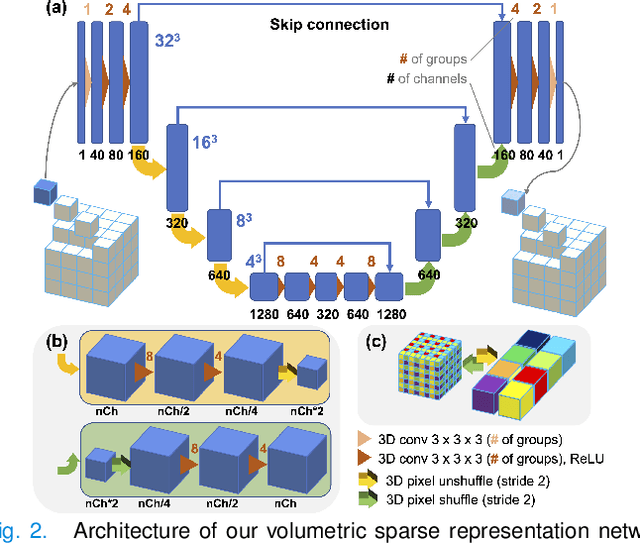
The latest X-ray photon-counting computed tomography (PCCT) for extremity allows multi-energy high-resolution (HR) imaging for tissue characterization and material decomposition. However, both radiation dose and imaging speed need improvement for contrast-enhanced and other studies. Despite the success of deep learning methods for 2D few-view reconstruction, applying them to HR volumetric reconstruction of extremity scans for clinical diagnosis has been limited due to GPU memory constraints, training data scarcity, and domain gap issues. In this paper, we propose a deep learning-based approach for PCCT image reconstruction at halved dose and doubled speed in a New Zealand clinical trial. Particularly, we present a patch-based volumetric refinement network to alleviate the GPU memory limitation, train network with synthetic data, and use model-based iterative refinement to bridge the gap between synthetic and real-world data. The simulation and phantom experiments demonstrate consistently improved results under different acquisition conditions on both in- and off-domain structures using a fixed network. The image quality of 8 patients from the clinical trial are evaluated by three radiologists in comparison with the standard image reconstruction with a full-view dataset. It is shown that our proposed approach is essentially identical to or better than the clinical benchmark in terms of diagnostic image quality scores. Our approach has a great potential to improve the safety and efficiency of PCCT without compromising image quality.
Short-lived High-volume Multi-A/B Testing
Dec 23, 2023Modern platforms leverage randomized experiments to make informed decisions from a given set of items (``treatments''). As a particularly challenging scenario, these items may (i) arrive in high volume, with thousands of new items being released per hour, and (ii) have short lifetime, say, due to the item's transient nature or underlying non-stationarity that impels the platform to perceive the same item as distinct copies over time. Thus motivated, we study a Bayesian multiple-play bandit problem that encapsulates the key features of the multivariate testing (or ``multi-A/B testing'') problem with a high volume of short-lived arms. In each round, a set of $k$ arms arrive, each available for $w$ rounds. Without knowing the mean reward for each arm, the learner selects a multiset of $n$ arms and immediately observes their realized rewards. We aim to minimize the loss due to not knowing the mean rewards, averaged over instances generated from a given prior distribution. We show that when $k = O(n^\rho)$ for some constant $\rho>0$, our proposed policy has $\tilde O(n^{-\min \{\rho, \frac 12 (1+\frac 1w)^{-1}\}})$ loss on a sufficiently large class of prior distributions. We complement this result by showing that every policy suffers $\Omega (n^{-\min \{\rho, \frac 12\}})$ loss on the same class of distributions. We further validate the effectiveness of our policy through a large-scale field experiment on {\em Glance}, a content-card-serving platform that faces exactly the above challenge. A simple variant of our policy outperforms the platform's current recommender by 4.32\% in total duration and 7.48\% in total number of click-throughs.
Markdown Pricing Under an Unknown Parametric Demand Model
Dec 23, 2023Consider a single-product revenue-maximization problem where the seller monotonically decreases the price in $n$ rounds with an unknown demand model coming from a given family. Without monotonicity, the minimax regret is $\tilde O(n^{2/3})$ for the Lipschitz demand family and $\tilde O(n^{1/2})$ for a general class of parametric demand models. With monotonicity, the minimax regret is $\tilde O(n^{3/4})$ if the revenue function is Lipschitz and unimodal. However, the minimax regret for parametric families remained open. In this work, we provide a complete settlement for this fundamental problem. We introduce the crossing number to measure the complexity of a family of demand functions. In particular, the family of degree-$k$ polynomials has a crossing number $k$. Based on conservatism under uncertainty, we present (i) a policy with an optimal $\Theta(\log^2 n)$ regret for families with crossing number $k=0$, and (ii) another policy with an optimal $\tilde \Theta(n^{k/(k+1)})$ regret when $k\ge 1$. These bounds are asymptotically higher than the $\tilde O(\log n)$ and $\tilde \Theta(\sqrt n)$ minimax regret for the same families without the monotonicity constraint.
FLIQS: One-Shot Mixed-Precision Floating-Point and Integer Quantization Search
Aug 07, 2023


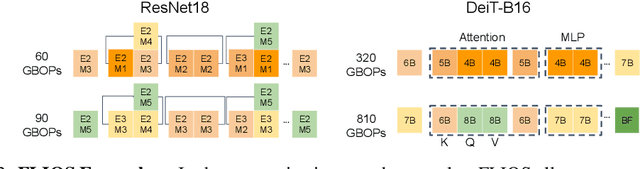
Quantization has become a mainstream compression technique for reducing model size, computational requirements, and energy consumption for modern deep neural networks (DNNs). With the improved numerical support in recent hardware, including multiple variants of integer and floating point, mixed-precision quantization has become necessary to achieve high-quality results with low model cost. Prior mixed-precision quantization methods have performed a post-training quantization search, which compromises on accuracy, or a differentiable quantization search, which leads to high memory usage from branching. Therefore, we propose the first one-shot mixed-precision quantization search that eliminates the need for retraining in both integer and low-precision floating point models. We evaluate our floating-point and integer quantization search (FLIQS) on multiple convolutional networks and vision transformer models to discover Pareto-optimal models. Our approach discovers models that improve upon uniform precision, manual mixed-precision, and recent integer quantization search methods. With the proposed integer quantization search, we increase the accuracy of ResNet-18 on ImageNet by 1.31% points and ResNet-50 by 0.90% points with equivalent model cost over previous methods. Additionally, for the first time, we explore a novel mixed-precision floating-point search and improve MobileNetV2 by up to 0.98% points compared to prior state-of-the-art FP8 models. Finally, we extend FLIQS to simultaneously search a joint quantization and neural architecture space and improve the ImageNet accuracy by 2.69% points with similar model cost on a MobileNetV2 search space.