 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger Together: Unleashing the Social Impact of Hate Speech Research
May 19, 2025The advent of the internet has been both a blessing and a curse for once marginalised communities. When used well, the internet can be used to connect and establish communities crossing different intersections; however, it can also be used as a tool to alienate people and communities as well as perpetuate hate, misinformation, and disinformation especially on social media platforms. We propose steering hate speech research and researchers away from pre-existing computational solutions and consider social methods to inform social solutions to address this social problem. In a similar way linguistics research can inform language planning policy, linguists should apply what we know about language and society to mitigate some of the emergent risks and dangers of anti-social behaviour in digital spaces. We argue linguists and NLP researchers can play a principle role in unleashing the social impact potential of linguistics research working alongside communities, advocates, activists, and policymakers to enable equitable digital inclusion and to close the digital divide.
cantnlp@DravidianLangTech-2025: A Bag-of-Sounds Approach to Multimodal Hate Speech Detection
Mar 10, 2025



This paper presents the systems and results for the Multimodal Social Media Data Analysis in Dravidian Languages (MSMDA-DL) shared task at the Fifth Workshop on Speech, Vision, and Language Technologies for Dravidian Languages (DravidianLangTech-2025). We took a `bag-of-sounds' approach by training our hate speech detection system on the speech (audio) data using transformed Mel spectrogram measures. While our candidate model performed poorly on the test set, our approach offered promising results during training and development for Malayalam and Tamil. With sufficient and well-balanced training data, our results show that it is feasible to use both text and speech (audio) data in the development of multimodal hate speech detection systems.
Detecting Linguistic Diversity on Social Media
Feb 28, 2025
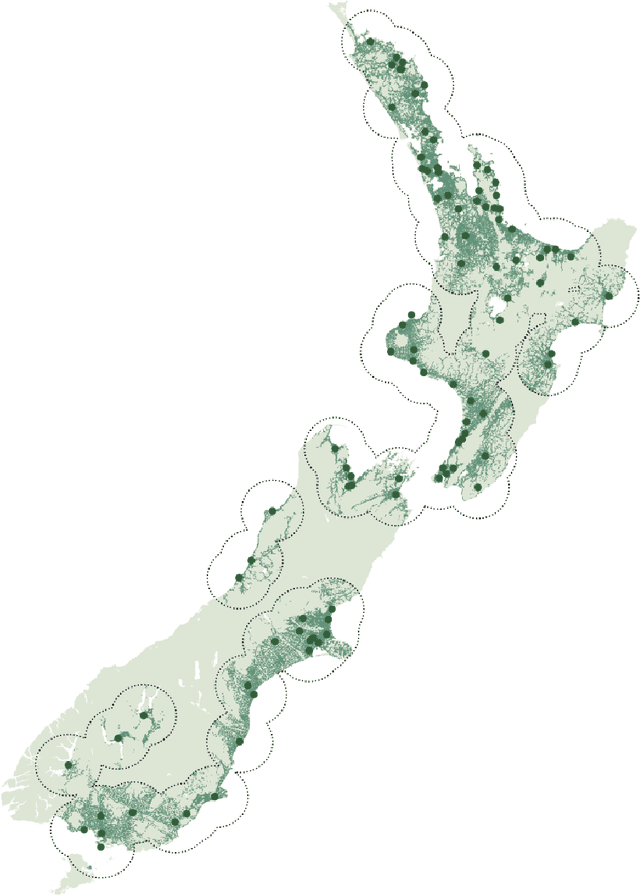
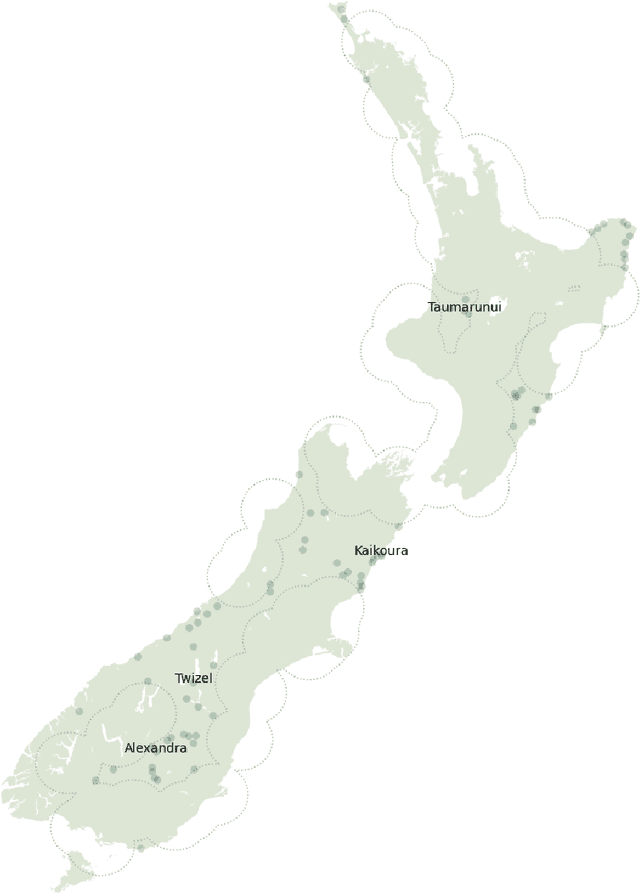
This chapter explores the efficacy of using social media data to examine changing linguistic behaviour of a place. We focus our investigation on Aotearoa New Zealand where official statistics from the census is the only source of language use data. We use published census data as the ground truth and the social media sub-corpus from the Corpus of Global Language Use as our alternative data source. We use place as the common denominator between the two data sources. We identify the language conditions of each tweet in the social media data set and validated our results with two language identification models. We then compare levels of linguistic diversity at national, regional, and local geographies. The results suggest that social media language data has the possibility to provide a rich source of spatial and temporal insights on the linguistic profile of a place. We show that social media is sensitive to demographic and sociopolitical changes within a language and at low-level regional and local geographies.
Stability of Syntactic Dialect Classification Over Space and Time
Sep 11, 2022
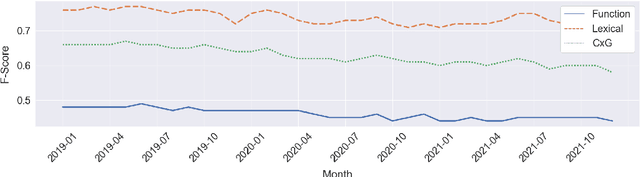

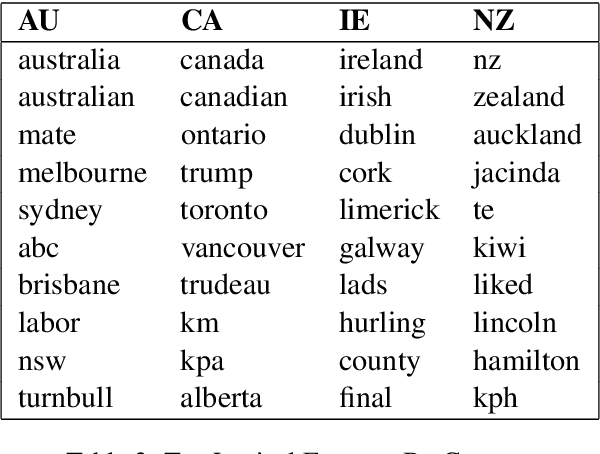
This paper analyses the degree to which dialect classifiers based on syntactic representations remain stable over space and time. While previous work has shown that the combination of grammar induction and geospatial text classification produces robust dialect models, we do not know what influence both changing grammars and changing populations have on dialect models. This paper constructs a test set for 12 dialects of English that spans three years at monthly intervals with a fixed spatial distribution across 1,120 cities. Syntactic representations are formulated within the usage-based Construction Grammar paradigm (CxG). The decay rate of classification performance for each dialect over time allows us to identify regions undergoing syntactic change. And the distribution of classification accuracy within dialect regions allows us to identify the degree to which the grammar of a dialect is internally heterogeneous. The main contribution of this paper is to show that a rigorous evaluation of dialect classification models can be used to find both variation over space and change over time.