 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Linguistic Diversity on Social Media
Feb 28, 2025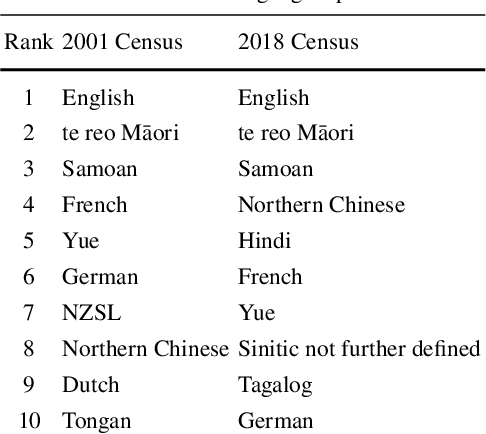
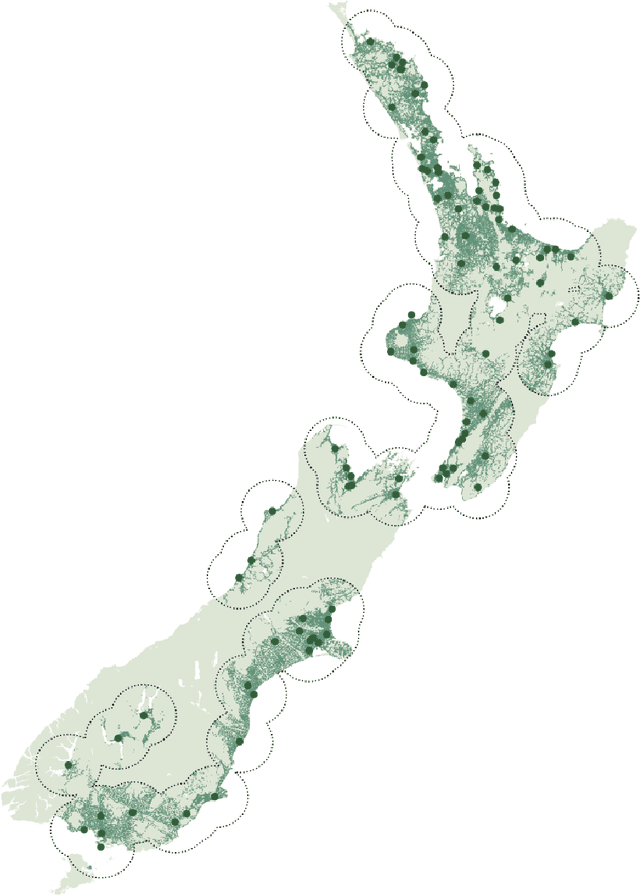
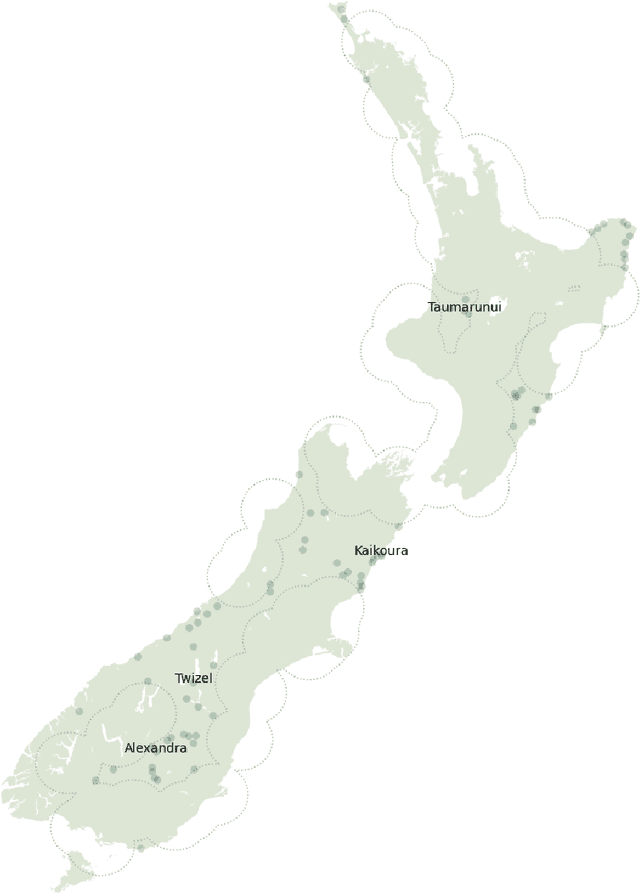
This chapter explores the efficacy of using social media data to examine changing linguistic behaviour of a place. We focus our investigation on Aotearoa New Zealand where official statistics from the census is the only source of language use data. We use published census data as the ground truth and the social media sub-corpus from the Corpus of Global Language Use as our alternative data source. We use place as the common denominator between the two data sources. We identify the language conditions of each tweet in the social media data set and validated our results with two language identification models. We then compare levels of linguistic diversity at national, regional, and local geographies. The results suggest that social media language data has the possibility to provide a rich source of spatial and temporal insights on the linguistic profile of a place. We show that social media is sensitive to demographic and sociopolitical changes within a language and at low-level regional and local geographies.
Pre-Trained Language Models Represent Some Geographic Populations Better Than Others
Mar 16, 2024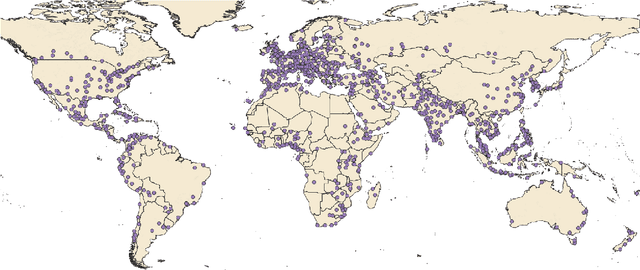


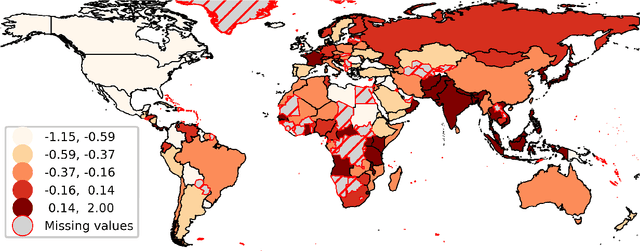
This paper measures the skew in how well two families of LLMs represent diverse geographic populations. A spatial probing task is used with geo-referenced corpora to measure the degree to which pre-trained language models from the OPT and BLOOM series represent diverse populations around the world. Results show that these models perform much better for some populations than others. In particular, populations across the US and the UK are represented quite well while those in South and Southeast Asia are poorly represented. Analysis shows that both families of models largely share the same skew across populations. At the same time, this skew cannot be fully explained by sociolinguistic factors, economic factors, or geographic factors. The basic conclusion from this analysis is that pre-trained models do not equally represent the world's population: there is a strong skew towards specific geographic populations. This finding challenges the idea that a single model can be used for all populations.
Geographically-Informed Language Identification
Mar 14, 2024This paper develops an approach to language identification in which the set of languages considered by the model depends on the geographic origin of the text in question. Given that many digital corpora can be geo-referenced at the country level, this paper formulates 16 region-specific models, each of which contains the languages expected to appear in countries within that region. These regional models also each include 31 widely-spoken international languages in order to ensure coverage of these linguae francae regardless of location. An upstream evaluation using traditional language identification testing data shows an improvement in f-score ranging from 1.7 points (Southeast Asia) to as much as 10.4 points (North Africa). A downstream evaluation on social media data shows that this improved performance has a significant impact on the language labels which are applied to large real-world corpora. The result is a highly-accurate model that covers 916 languages at a sample size of 50 characters, the performance improved by incorporating geographic information into the model.
Validating and Exploring Large Geographic Corpora
Mar 13, 2024
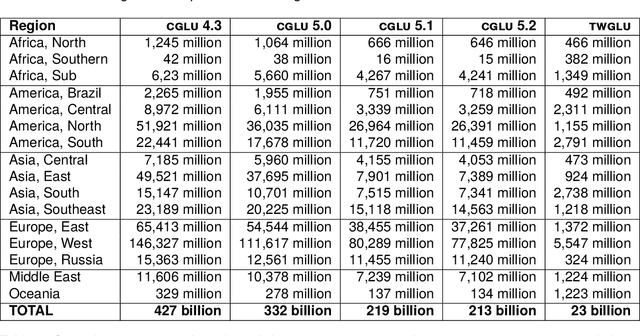
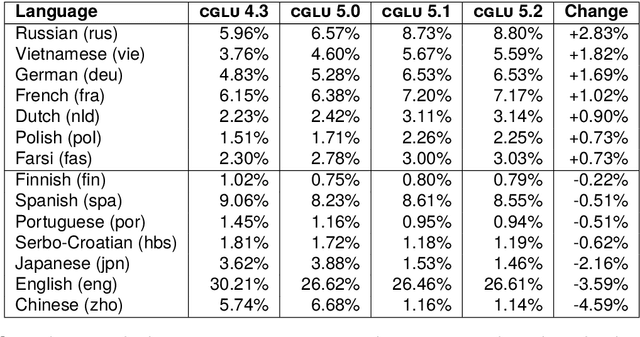
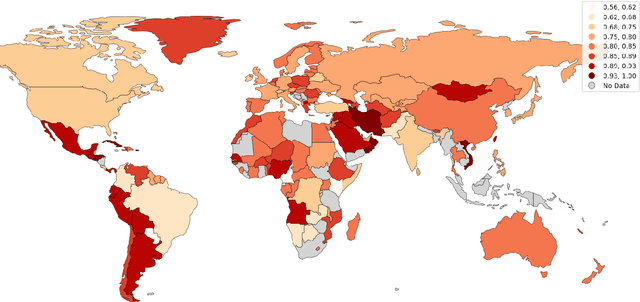
This paper investigates the impact of corpus creation decisions on large multi-lingual geographic web corpora. Beginning with a 427 billion word corpus derived from the Common Crawl, three methods are used to improve the quality of sub-corpora representing specific language-country pairs like New Zealand English: (i) the agreement of independent language identification systems, (ii) hash-based deduplication, and (iii) location-specific outlier detection. The impact of each of these steps is then evaluated at the language level and the country level by using corpus similarity measures to compare each resulting corpus with baseline data sets. The goal is to understand the impact of upstream data cleaning decisions on downstream corpora with a specific focus on under-represented languages and populations. The evaluation shows that the validity of sub-corpora is improved with each stage of cleaning but that this improvement is unevenly distributed across languages and populations. This result shows how standard corpus creation techniques can accidentally exclude under-represented populations.
Syntactic Variation Across the Grammar: Modelling a Complex Adaptive System
Sep 21, 2023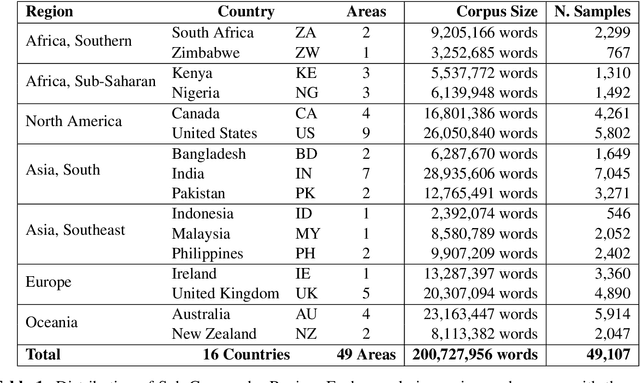
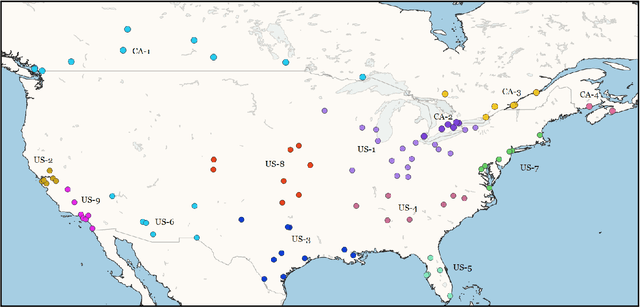
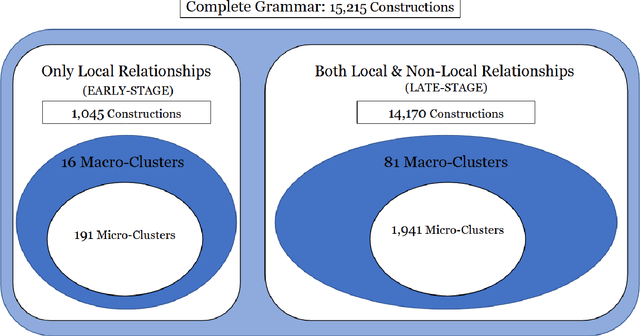
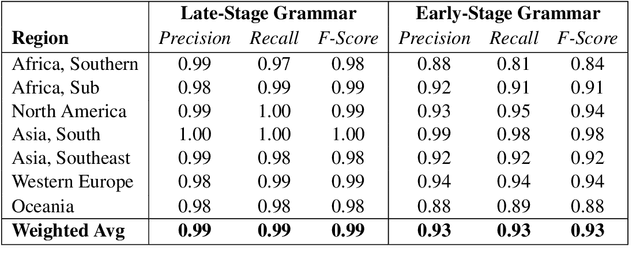
While language is a complex adaptive system, most work on syntactic variation observes a few individual constructions in isolation from the rest of the grammar. This means that the grammar, a network which connects thousands of structures at different levels of abstraction, is reduced to a few disconnected variables. This paper quantifies the impact of such reductions by systematically modelling dialectal variation across 49 local populations of English speakers in 16 countries. We perform dialect classification with both an entire grammar as well as with isolated nodes within the grammar in order to characterize the syntactic differences between these dialects. The results show, first, that many individual nodes within the grammar are subject to variation but, in isolation, none perform as well as the grammar as a whole. This indicates that an important part of syntactic variation consists of interactions between different parts of the grammar. Second, the results show that the similarity between dialects depends heavily on the sub-set of the grammar being observed: for example, New Zealand English could be more similar to Australian English in phrasal verbs but at the same time more similar to UK English in dative phrases.
cantnlp@LT-EDI-2023: Homophobia/Transphobia Detection in Social Media Comments using Spatio-Temporally Retrained Language Models
Aug 25, 2023



This paper describes our multiclass classification system developed as part of the LTEDI@RANLP-2023 shared task. We used a BERT-based language model to detect homophobic and transphobic content in social media comments across five language conditions: English, Spanish, Hindi, Malayalam, and Tamil. We retrained a transformer-based crosslanguage pretrained language model, XLMRoBERTa, with spatially and temporally relevant social media language data. We also retrained a subset of models with simulated script-mixed social media language data with varied performance. We developed the best performing seven-label classification system for Malayalam based on weighted macro averaged F1 score (ranked first out of six) with variable performance for other language and class-label conditions. We found the inclusion of this spatio-temporal data improved the classification performance for all language and task conditions when compared with the baseline. The results suggests that transformer-based language classification systems are sensitive to register-specific and language-specific retraining.
Comparing Measures of Linguistic Diversity Across Social Media Language Data and Census Data at Subnational Geographic Areas
Aug 21, 2023



This paper describes a preliminary study on the comparative linguistic ecology of online spaces (i.e., social media language data) and real-world spaces in Aotearoa New Zealand (i.e., subnational administrative areas). We compare measures of linguistic diversity between these different spaces and discuss how social media users align with real-world populations. The results from the current study suggests that there is potential to use online social media language data to observe spatial and temporal changes in linguistic diversity at subnational geographic areas; however, further work is required to understand how well social media represents real-world behaviour.
Variation and Instability in Dialect-Based Embedding Spaces
Mar 27, 2023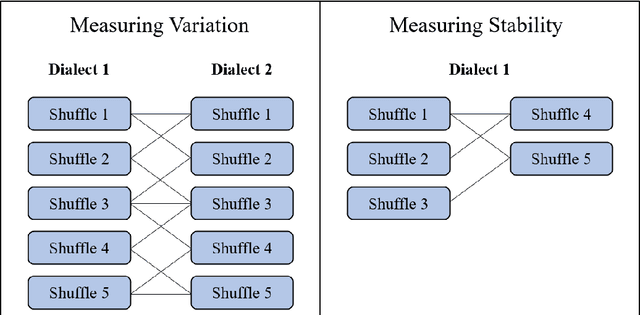
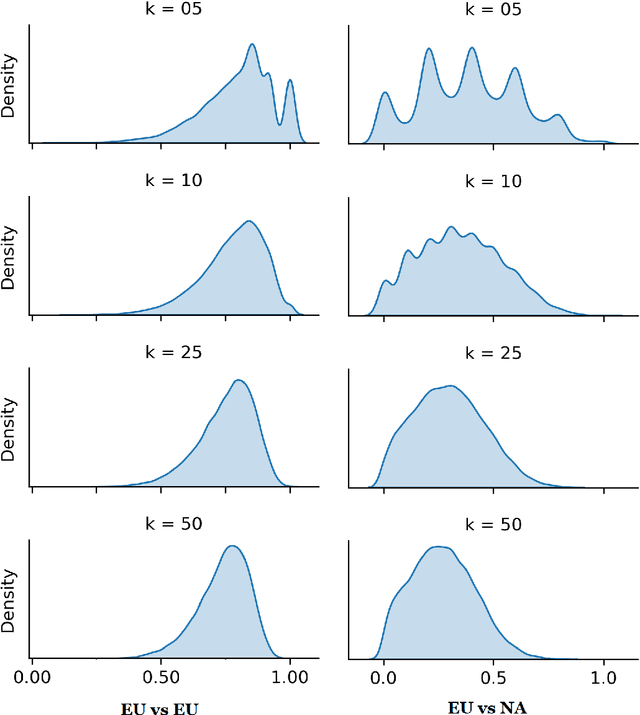
This paper measures variation in embedding spaces which have been trained on different regional varieties of English while controlling for instability in the embeddings. While previous work has shown that it is possible to distinguish between similar varieties of a language, this paper experiments with two follow-up questions: First, does the variety represented in the training data systematically influence the resulting embedding space after training? This paper shows that differences in embeddings across varieties are significantly higher than baseline instability. Second, is such dialect-based variation spread equally throughout the lexicon? This paper shows that specific parts of the lexicon are particularly subject to variation. Taken together, these experiments confirm that embedding spaces are significantly influenced by the dialect represented in the training data. This finding implies that there is semantic variation across dialects, in addition to previously-studied lexical and syntactic variation.
Exploring the Constructicon: Linguistic Analysis of a Computational CxG
Jan 30, 2023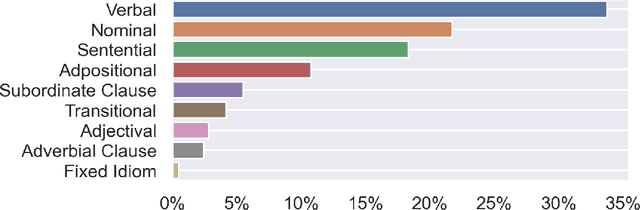
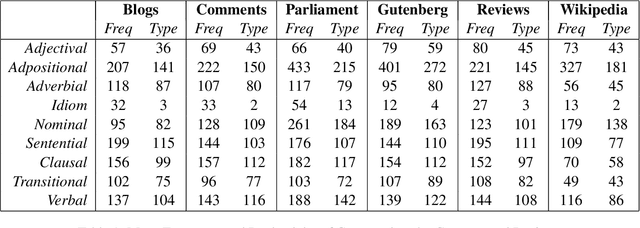
Recent work has formulated the task for computational construction grammar as producing a constructicon given a corpus of usage. Previous work has evaluated these unsupervised grammars using both internal metrics (for example, Minimum Description Length) and external metrics (for example, performance on a dialectology task). This paper instead takes a linguistic approach to evaluation, first learning a constructicon and then analyzing its contents from a linguistic perspective. This analysis shows that a learned constructicon can be divided into nine major types of constructions, of which Verbal and Nominal are the most common. The paper also shows that both the token and type frequency of constructions can be used to model variation across registers and dialects.
Exposure and Emergence in Usage-Based Grammar: Computational Experiments in 35 Languages
Nov 25, 2022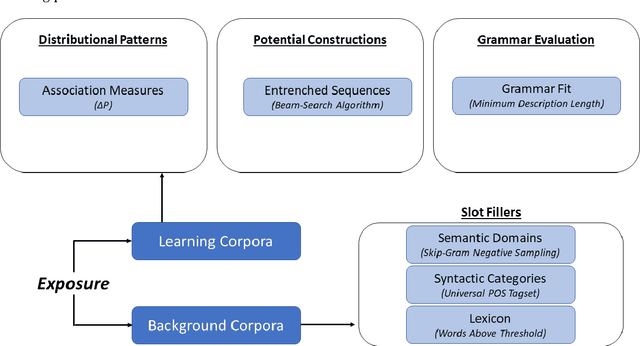
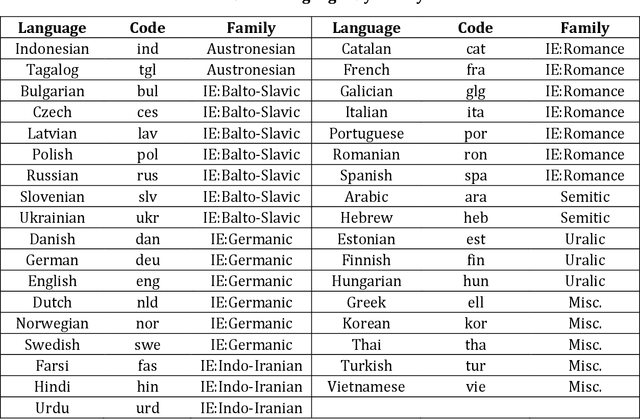
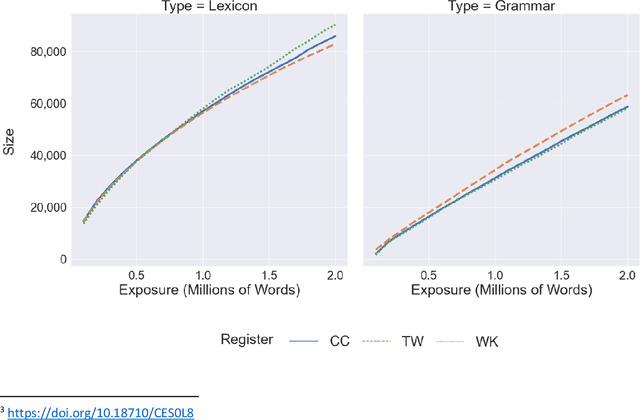
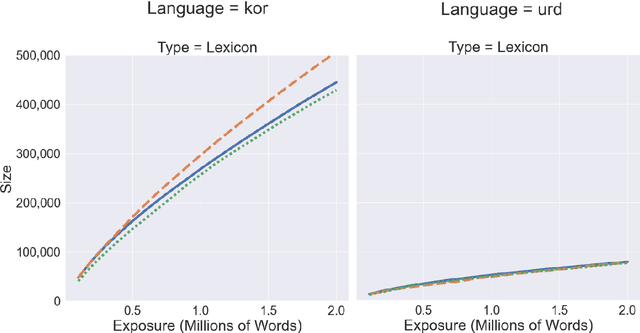
This paper uses computational experiments to explore the role of exposure in the emergence of construction grammars. While usage-based grammars are hypothesized to depend on a learner's exposure to actual language use, the mechanisms of such exposure have only been studied in a few constructions in isolation. This paper experiments with (i) the growth rate of the constructicon, (ii) the convergence rate of grammars exposed to independent registers, and (iii) the rate at which constructions are forgotten when they have not been recently observed. These experiments show that the lexicon grows more quickly than the grammar and that the growth rate of the grammar is not dependent on the growth rate of the lexicon. At the same time, register-specific grammars converge onto more similar constructions as the amount of exposure increases. This means that the influence of specific registers becomes less important as exposure increases. Finally, the rate at which constructions are forgotten when they have not been recently observed mirrors the growth rate of the constructicon. This paper thus presents a computational model of usage-based grammar that includes both the emergence and the unentrenchment of constructions.