 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidating and Exploring Large Geographic Corpora
Paper and Code

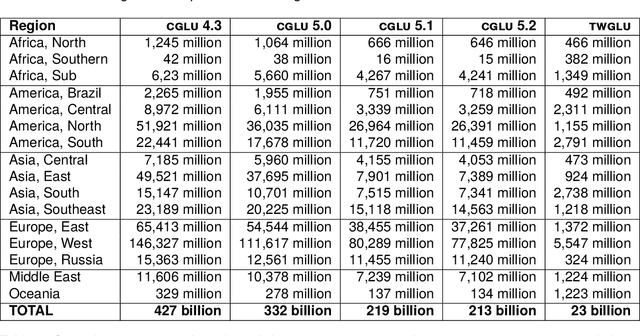
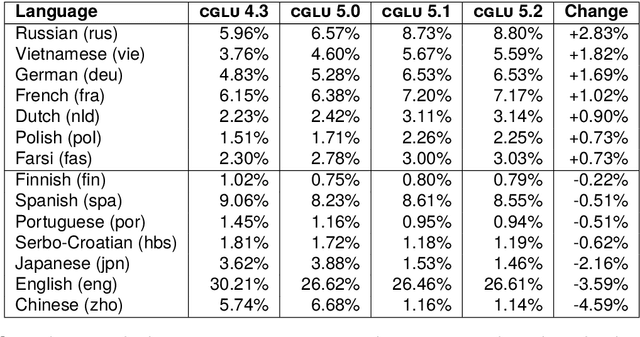
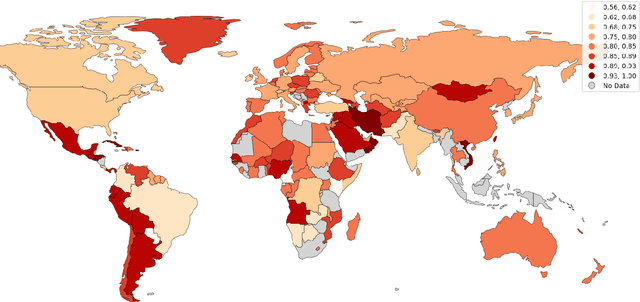
This paper investigates the impact of corpus creation decisions on large multi-lingual geographic web corpora. Beginning with a 427 billion word corpus derived from the Common Crawl, three methods are used to improve the quality of sub-corpora representing specific language-country pairs like New Zealand English: (i) the agreement of independent language identification systems, (ii) hash-based deduplication, and (iii) location-specific outlier detection. The impact of each of these steps is then evaluated at the language level and the country level by using corpus similarity measures to compare each resulting corpus with baseline data sets. The goal is to understand the impact of upstream data cleaning decisions on downstream corpora with a specific focus on under-represented languages and populations. The evaluation shows that the validity of sub-corpora is improved with each stage of cleaning but that this improvement is unevenly distributed across languages and populations. This result shows how standard corpus creation techniques can accidentally exclude under-represented populations.