 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilled Circuits: A Mechanistic Study of Internal Restructuring in Knowledge Distillation
May 16, 2025



Knowledge distillation compresses a larger neural model (teacher) into smaller, faster student models by training them to match teacher outputs. However, the internal computational transformations that occur during this process remain poorly understood. We apply techniques from mechanistic interpretability to analyze how internal circuits, representations, and activation patterns differ between teacher and student. Focusing on GPT2-small and its distilled counterpart DistilGPT2, we find that student models reorganize, compress, and discard teacher components, often resulting in stronger reliance on fewer individual components. To quantify functional alignment beyond output similarity, we introduce an alignment metric based on influence-weighted component similarity, validated across multiple tasks. Our findings reveal that while knowledge distillation preserves broad functional behaviors, it also causes significant shifts in internal computation, with important implications for the robustness and generalization capacity of distilled models.
Detecting Linguistic Diversity on Social Media
Feb 28, 2025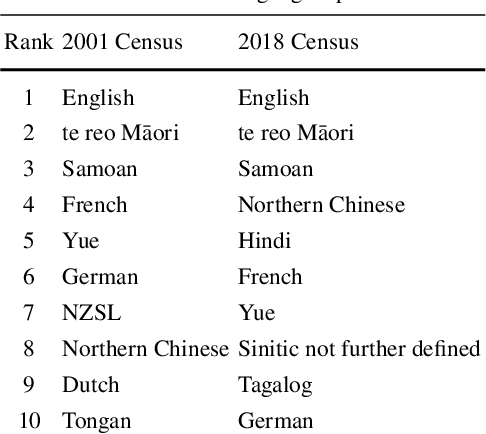
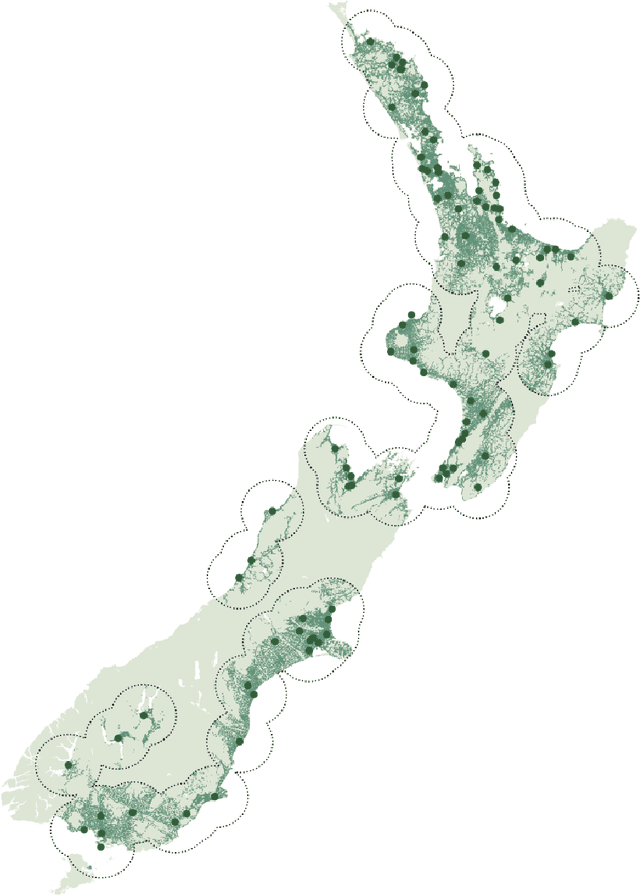
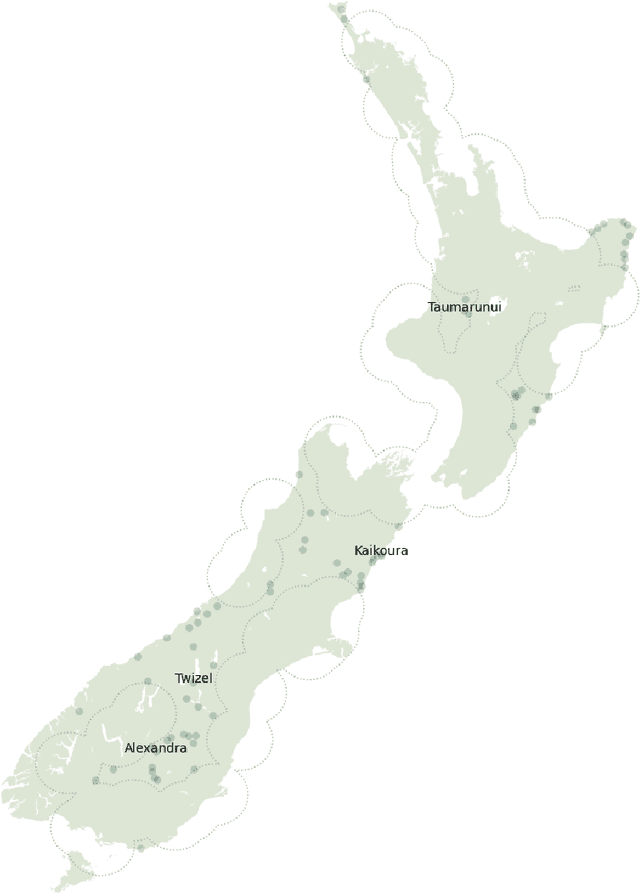
This chapter explores the efficacy of using social media data to examine changing linguistic behaviour of a place. We focus our investigation on Aotearoa New Zealand where official statistics from the census is the only source of language use data. We use published census data as the ground truth and the social media sub-corpus from the Corpus of Global Language Use as our alternative data source. We use place as the common denominator between the two data sources. We identify the language conditions of each tweet in the social media data set and validated our results with two language identification models. We then compare levels of linguistic diversity at national, regional, and local geographies. The results suggest that social media language data has the possibility to provide a rich source of spatial and temporal insights on the linguistic profile of a place. We show that social media is sensitive to demographic and sociopolitical changes within a language and at low-level regional and local geographies.
Pre-Trained Language Models Represent Some Geographic Populations Better Than Others
Mar 16, 2024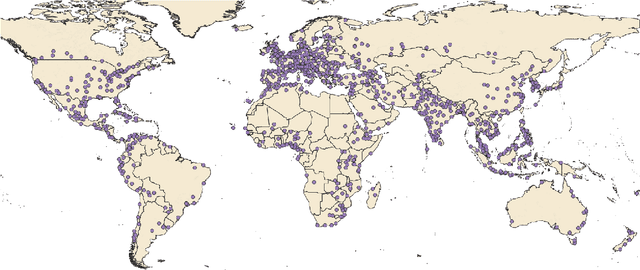


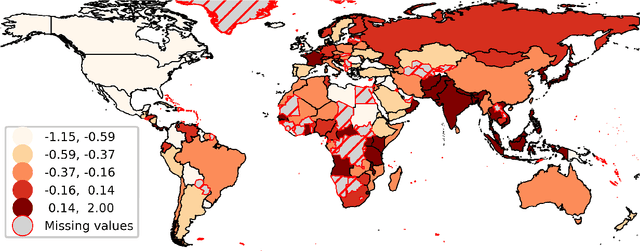
This paper measures the skew in how well two families of LLMs represent diverse geographic populations. A spatial probing task is used with geo-referenced corpora to measure the degree to which pre-trained language models from the OPT and BLOOM series represent diverse populations around the world. Results show that these models perform much better for some populations than others. In particular, populations across the US and the UK are represented quite well while those in South and Southeast Asia are poorly represented. Analysis shows that both families of models largely share the same skew across populations. At the same time, this skew cannot be fully explained by sociolinguistic factors, economic factors, or geographic factors. The basic conclusion from this analysis is that pre-trained models do not equally represent the world's population: there is a strong skew towards specific geographic populations. This finding challenges the idea that a single model can be used for all populations.
cantnlp@LT-EDI-2023: Homophobia/Transphobia Detection in Social Media Comments using Spatio-Temporally Retrained Language Models
Aug 25, 2023



This paper describes our multiclass classification system developed as part of the LTEDI@RANLP-2023 shared task. We used a BERT-based language model to detect homophobic and transphobic content in social media comments across five language conditions: English, Spanish, Hindi, Malayalam, and Tamil. We retrained a transformer-based crosslanguage pretrained language model, XLMRoBERTa, with spatially and temporally relevant social media language data. We also retrained a subset of models with simulated script-mixed social media language data with varied performance. We developed the best performing seven-label classification system for Malayalam based on weighted macro averaged F1 score (ranked first out of six) with variable performance for other language and class-label conditions. We found the inclusion of this spatio-temporal data improved the classification performance for all language and task conditions when compared with the baseline. The results suggests that transformer-based language classification systems are sensitive to register-specific and language-specific retraining.
Comparing Measures of Linguistic Diversity Across Social Media Language Data and Census Data at Subnational Geographic Areas
Aug 21, 2023



This paper describes a preliminary study on the comparative linguistic ecology of online spaces (i.e., social media language data) and real-world spaces in Aotearoa New Zealand (i.e., subnational administrative areas). We compare measures of linguistic diversity between these different spaces and discuss how social media users align with real-world populations. The results from the current study suggests that there is potential to use online social media language data to observe spatial and temporal changes in linguistic diversity at subnational geographic areas; however, further work is required to understand how well social media represents real-world behaviour.
Quoka Atlas of Scholarly Knowledge Production: An Interactive Sensemaking Tool for Exploring the Outputs of Research Institutions
Sep 16, 2021
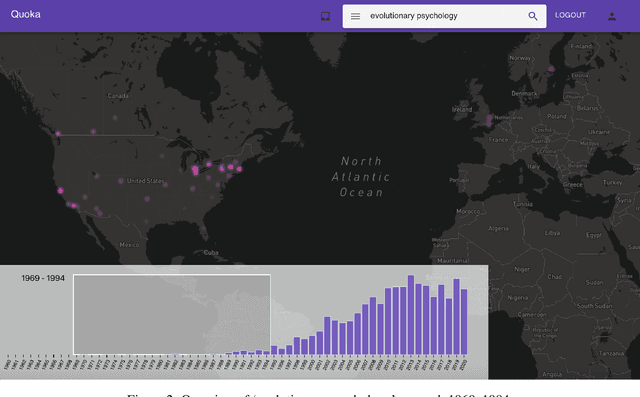
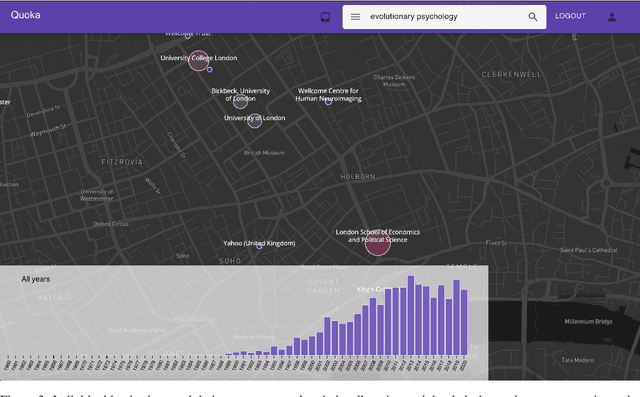
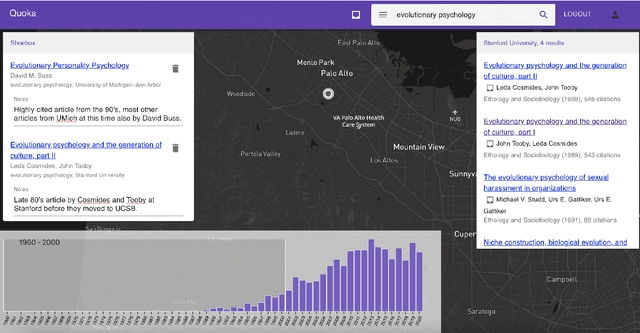
The vast amount of research produced at institutions world-wide is extremely diverse, and coarse-grained quantitative measures of impact often obscure the individual contributions of these institutions to specific research fields and topics. We show that by applying an information retrieval model to index research articles which are faceted by institution and time, we can develop tools to rank institutions given a keyword query. We present an interactive atlas, Quoka, designed to enable a user to explore these rankings contextually by geography and over time. Through a set of use cases we demonstrate that the atlas can be used to perform sensemaking tasks to learn and collect information about the relationships between institutions and scholarly knowledge production.
Measuring Linguistic Diversity During COVID-19
Apr 03, 2021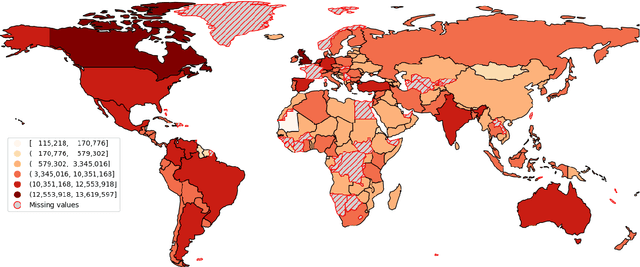
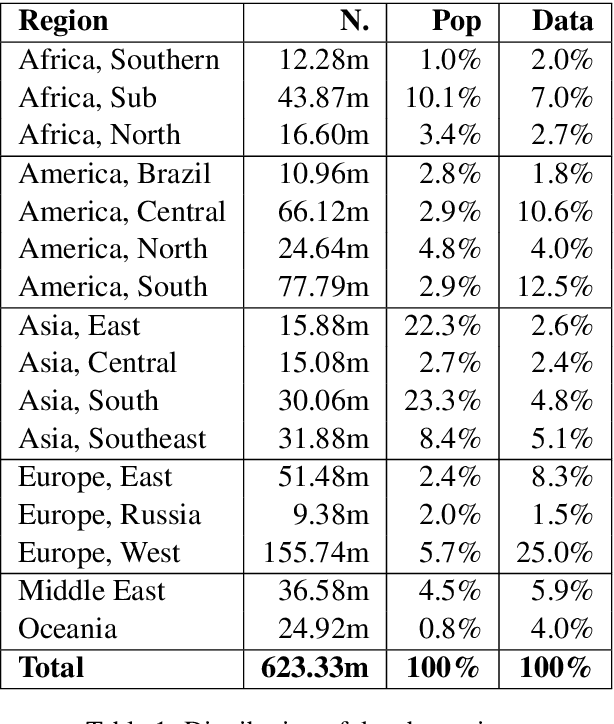
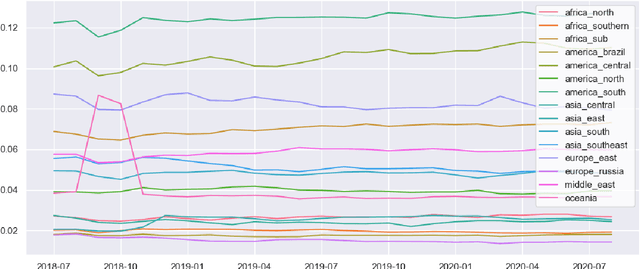
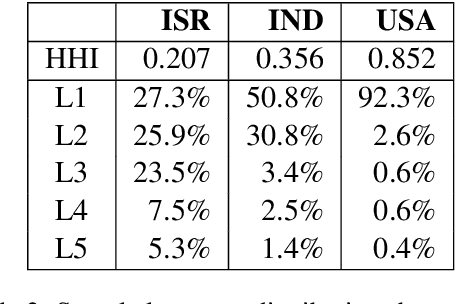
Computational measures of linguistic diversity help us understand the linguistic landscape using digital language data. The contribution of this paper is to calibrate measures of linguistic diversity using restrictions on international travel resulting from the COVID-19 pandemic. Previous work has mapped the distribution of languages using geo-referenced social media and web data. The goal, however, has been to describe these corpora themselves rather than to make inferences about underlying populations. This paper shows that a difference-in-differences method based on the Herfindahl-Hirschman Index can identify the bias in digital corpora that is introduced by non-local populations. These methods tell us where significant changes have taken place and whether this leads to increased or decreased diversity. This is an important step in aligning digital corpora like social media with the real-world populations that have produced them.
The observational roots of reference of the semantic web
Jun 27, 2012Shared reference is an essential aspect of meaning. It is also indispensable for the semantic web, since it enables to weave the global graph, i.e., it allows different users to contribute to an identical referent. For example, an essential kind of referent is a geographic place, to which users may contribute observations. We argue for a human-centric, operational approach towards reference, based on respective human competences. These competences encompass perceptual, cognitive as well as technical ones, and together they allow humans to inter-subjectively refer to a phenomenon in their environment. The technology stack of the semantic web should be extended by such operations. This would allow establishing new kinds of observation-based reference systems that help constrain and integrate the semantic web bottom-up.