 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeography According to ChatGPT -- How Generative AI Represents and Reasons about Geography
Mar 19, 2026Understanding how AI will represent and reason about geography should be a key concern for all of us, as the broader public increasingly interacts with spaces and places through these systems. Similarly, in line with the nature of foundation models, our own research often relies on pre-trained models. Hence, understanding what world AI systems construct is as important as evaluating their accuracy, including factual recall. To motivate the need for such studies, we provide three illustrative vignettes, i.e., exploratory probes, in the hope that they will spark lively discussions and follow-up work: (1) Do models form strong defaults, and how brittle are model outputs to minute syntactic variations? (2) Can distributional shifts resurface from the composition of individually benign tasks, e.g., when using AI systems to create personas? (3) Do we overlook deeper questions of understanding when solely focusing on the ability of systems to recall facts such as geographic principles?
Whose Truth? Pluralistic Geo-Alignment for (Agentic) AI
Aug 07, 2025AI (super) alignment describes the challenge of ensuring (future) AI systems behave in accordance with societal norms and goals. While a quickly evolving literature is addressing biases and inequalities, the geographic variability of alignment remains underexplored. Simply put, what is considered appropriate, truthful, or legal can differ widely across regions due to cultural norms, political realities, and legislation. Alignment measures applied to AI/ML workflows can sometimes produce outcomes that diverge from statistical realities, such as text-to-image models depicting balanced gender ratios in company leadership despite existing imbalances. Crucially, some model outputs are globally acceptable, while others, e.g., questions about Kashmir, depend on knowing the user's location and their context. This geographic sensitivity is not new. For instance, Google Maps renders Kashmir's borders differently based on user location. What is new is the unprecedented scale and automation with which AI now mediates knowledge, expresses opinions, and represents geographic reality to millions of users worldwide, often with little transparency about how context is managed. As we approach Agentic AI, the need for spatio-temporally aware alignment, rather than one-size-fits-all approaches, is increasingly urgent. This paper reviews key geographic research problems, suggests topics for future work, and outlines methods for assessing alignment sensitivity.
Foundation Models for Geospatial Reasoning: Assessing Capabilities of Large Language Models in Understanding Geometries and Topological Spatial Relations
May 22, 2025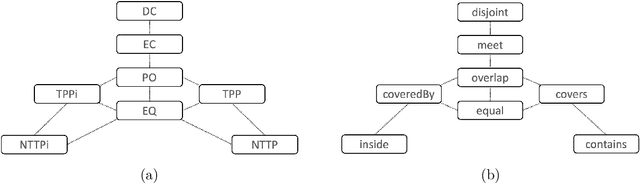
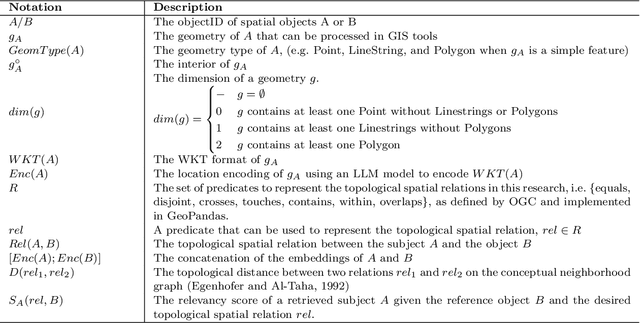
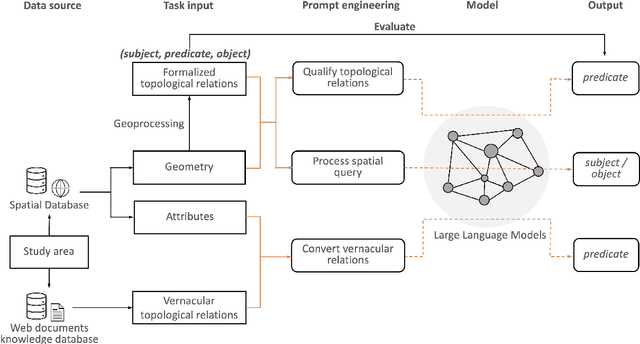
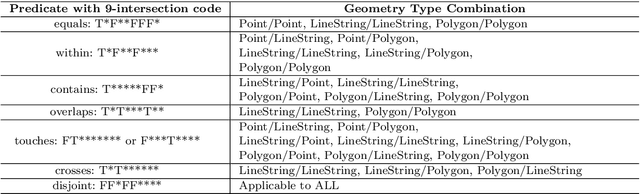
Applying AI foundation models directly to geospatial datasets remains challenging due to their limited ability to represent and reason with geographical entities, specifically vector-based geometries and natural language descriptions of complex spatial relations. To address these issues, we investigate the extent to which a well-known-text (WKT) representation of geometries and their spatial relations (e.g., topological predicates) are preserved during spatial reasoning when the geospatial vector data are passed to large language models (LLMs) including GPT-3.5-turbo, GPT-4, and DeepSeek-R1-14B. Our workflow employs three distinct approaches to complete the spatial reasoning tasks for comparison, i.e., geometry embedding-based, prompt engineering-based, and everyday language-based evaluation. Our experiment results demonstrate that both the embedding-based and prompt engineering-based approaches to geospatial question-answering tasks with GPT models can achieve an accuracy of over 0.6 on average for the identification of topological spatial relations between two geometries. Among the evaluated models, GPT-4 with few-shot prompting achieved the highest performance with over 0.66 accuracy on topological spatial relation inference. Additionally, GPT-based reasoner is capable of properly comprehending inverse topological spatial relations and including an LLM-generated geometry can enhance the effectiveness for geographic entity retrieval. GPT-4 also exhibits the ability to translate certain vernacular descriptions about places into formal topological relations, and adding the geometry-type or place-type context in prompts may improve inference accuracy, but it varies by instance. The performance of these spatial reasoning tasks offers valuable insights for the refinement of LLMs with geographical knowledge towards the development of geo-foundation models capable of geospatial reasoning.
* 33 pages, 13 figures, IJGIS GeoFM Special Issue
GIScience in the Era of Artificial Intelligence: A Research Agenda Towards Autonomous GIS
Apr 01, 2025The advent of generative AI exemplified by large language models (LLMs) opens new ways to represent and compute geographic information and transcend the process of geographic knowledge production, driving geographic information systems (GIS) towards autonomous GIS. Leveraging LLMs as the decision core, autonomous GIS can independently generate and execute geoprocessing workflows to perform spatial analysis. In this vision paper, we elaborate on the concept of autonomous GIS and present a framework that defines its five autonomous goals, five levels of autonomy, five core functions, and three operational scales. We demonstrate how autonomous GIS could perform geospatial data retrieval, spatial analysis, and map making with four proof-of-concept GIS agents. We conclude by identifying critical challenges and future research directions, including fine-tuning and self-growing decision cores, autonomous modeling, and examining the ethical and practical implications of autonomous GIS. By establishing the groundwork for a paradigm shift in GIScience, this paper envisions a future where GIS moves beyond traditional workflows to autonomously reason, derive, innovate, and advance solutions to pressing global challenges.
The S2 Hierarchical Discrete Global Grid as a Nexus for Data Representation, Integration, and Querying Across Geospatial Knowledge Graphs
Oct 18, 2024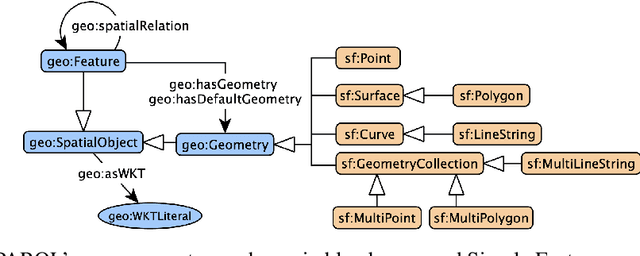


Geospatial Knowledge Graphs (GeoKGs) have become integral to the growing field of Geospatial Artificial Intelligence. Initiatives like the U.S. National Science Foundation's Open Knowledge Network program aim to create an ecosystem of nation-scale, cross-disciplinary GeoKGs that provide AI-ready geospatial data aligned with FAIR principles. However, building this infrastructure presents key challenges, including 1) managing large volumes of data, 2) the computational complexity of discovering topological relations via SPARQL, and 3) conflating multi-scale raster and vector data. Discrete Global Grid Systems (DGGS) help tackle these issues by offering efficient data integration and representation strategies. The KnowWhereGraph utilizes Google's S2 Geometry -- a DGGS framework -- to enable efficient multi-source data processing, qualitative spatial querying, and cross-graph integration. This paper outlines the implementation of S2 within KnowWhereGraph, emphasizing its role in topologically enriching and semantically compressing data. Ultimately, this work demonstrates the potential of DGGS frameworks, particularly S2, for building scalable GeoKGs.
The KnowWhereGraph Ontology
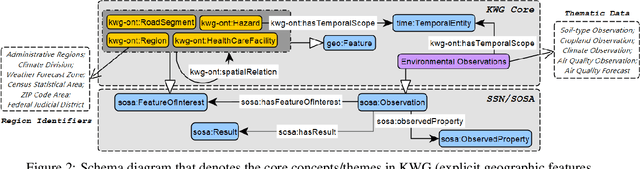
Oct 17, 2024



KnowWhereGraph is one of the largest fully publicly available geospatial knowledge graphs. It includes data from 30 layers on natural hazards (e.g., hurricanes, wildfires), climate variables (e.g., air temperature, precipitation), soil properties, crop and land-cover types, demographics, and human health, various place and region identifiers, among other themes. These have been leveraged through the graph by a variety of applications to address challenges in food security and agricultural supply chains; sustainability related to soil conservation practices and farm labor; and delivery of emergency humanitarian aid following a disaster. In this paper, we introduce the ontology that acts as the schema for KnowWhereGraph. This broad overview provides insight into the requirements and design specifications for the graph and its schema, including the development methodology (modular ontology modeling) and the resources utilized to implement, materialize, and deploy KnowWhereGraph with its end-user interfaces and public query SPARQL endpoint.
Probing the Information Theoretical Roots of Spatial Dependence Measures
May 28, 2024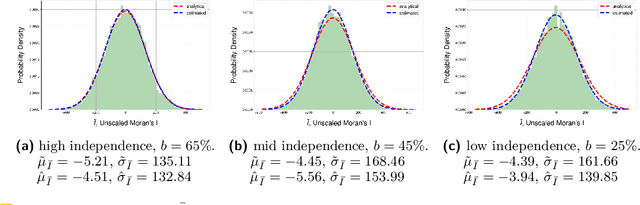

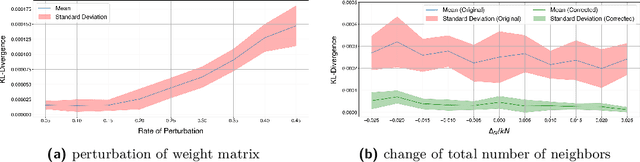
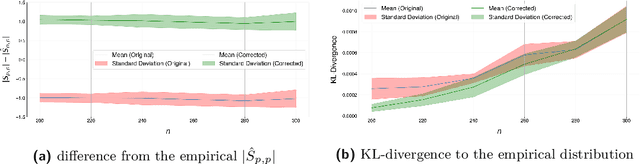
Intuitively, there is a relation between measures of spatial dependence and information theoretical measures of entropy. For instance, we can provide an intuition of why spatial data is special by stating that, on average, spatial data samples contain less than expected information. Similarly, spatial data, e.g., remotely sensed imagery, that is easy to compress is also likely to show significant spatial autocorrelation. Formulating our (highly specific) core concepts of spatial information theory in the widely used language of information theory opens new perspectives on their differences and similarities and also fosters cross-disciplinary collaboration, e.g., with the broader AI/ML communities. Interestingly, however, this intuitive relation is challenging to formalize and generalize, leading prior work to rely mostly on experimental results, e.g., for describing landscape patterns. In this work, we will explore the information theoretical roots of spatial autocorrelation, more specifically Moran's I, through the lens of self-information (also known as surprisal) and provide both formal proofs and experiments.
MC-GTA: Metric-Constrained Model-Based Clustering using Goodness-of-fit Tests with Autocorrelations
May 28, 2024



A wide range of (multivariate) temporal (1D) and spatial (2D) data analysis tasks, such as grouping vehicle sensor trajectories, can be formulated as clustering with given metric constraints. Existing metric-constrained clustering algorithms overlook the rich correlation between feature similarity and metric distance, i.e., metric autocorrelation. The model-based variations of these clustering algorithms (e.g. TICC and STICC) achieve SOTA performance, yet suffer from computational instability and complexity by using a metric-constrained Expectation-Maximization procedure. In order to address these two problems, we propose a novel clustering algorithm, MC-GTA (Model-based Clustering via Goodness-of-fit Tests with Autocorrelations). Its objective is only composed of pairwise weighted sums of feature similarity terms (square Wasserstein-2 distance) and metric autocorrelation terms (a novel multivariate generalization of classic semivariogram). We show that MC-GTA is effectively minimizing the total hinge loss for intra-cluster observation pairs not passing goodness-of-fit tests, i.e., statistically not originating from the same distribution. Experiments on 1D/2D synthetic and real-world datasets demonstrate that MC-GTA successfully incorporates metric autocorrelation. It outperforms strong baselines by large margins (up to 14.3% in ARI and 32.1% in NMI) with faster and stabler optimization (>10x speedup).
MobilityDL: A Review of Deep Learning From Trajectory Data
Feb 01, 2024Trajectory data combines the complexities of time series, spatial data, and (sometimes irrational) movement behavior. As data availability and computing power have increased, so has the popularity of deep learning from trajectory data. This review paper provides the first comprehensive overview of deep learning approaches for trajectory data. We have identified eight specific mobility use cases which we analyze with regards to the deep learning models and the training data used. Besides a comprehensive quantitative review of the literature since 2018, the main contribution of our work is the data-centric analysis of recent work in this field, placing it along the mobility data continuum which ranges from detailed dense trajectories of individual movers (quasi-continuous tracking data), to sparse trajectories (such as check-in data), and aggregated trajectories (crowd information).
Here Is Not There: Measuring Entailment-Based Trajectory Similarity for Location-Privacy Protection and Beyond
Dec 02, 2023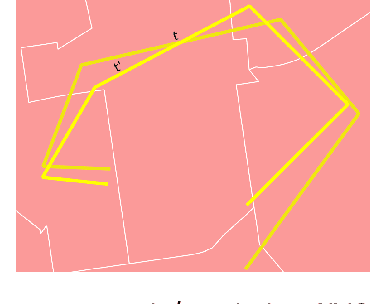
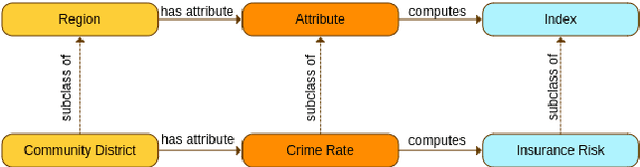
While the paths humans take play out in social as well as physical space, measures to describe and compare their trajectories are carried out in abstract, typically Euclidean, space. When these measures are applied to trajectories of actual individuals in an application area, alterations that are inconsequential in abstract space may suddenly become problematic once overlaid with geographic reality. In this work, we present a different view on trajectory similarity by introducing a measure that utilizes logical entailment. This is an inferential perspective that considers facts as triple statements deduced from the social and environmental context in which the travel takes place, and their practical implications. We suggest a formalization of entailment-based trajectory similarity, measured as the overlapping proportion of facts, which are spatial relation statements in our case study. With the proposed measure, we evaluate LSTM-TrajGAN, a privacy-preserving trajectory-generation model. The entailment-based model evaluation reveals potential consequences of disregarding the rich structure of geographic space (e.g., miscalculated insurance risk due to regional shifts in our toy example). Our work highlights the advantage of applying logical entailment to trajectory-similarity reasoning for location-privacy protection and beyond.