 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsight Miner: A Time Series Analysis Dataset for Cross-Domain Alignment with Natural Language
Dec 12, 2025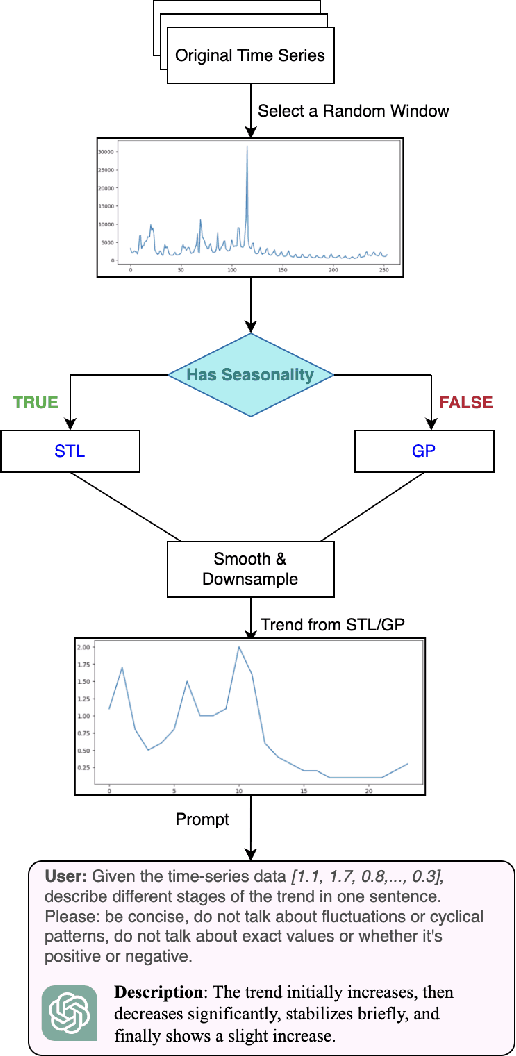
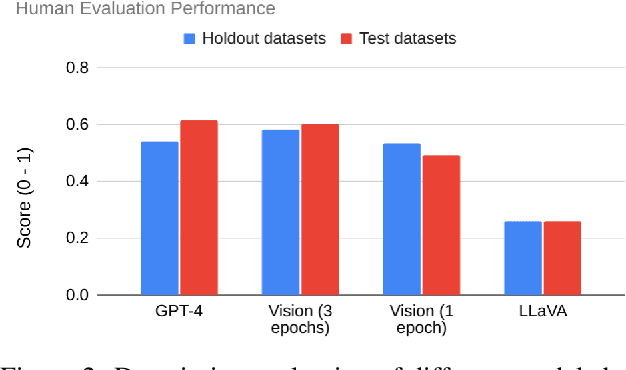
Time-series data is critical across many scientific and industrial domains, including environmental analysis, agriculture, transportation, and finance. However, mining insights from this data typically requires deep domain expertise, a process that is both time-consuming and labor-intensive. In this paper, we propose \textbf{Insight Miner}, a large-scale multimodal model (LMM) designed to generate high-quality, comprehensive time-series descriptions enriched with domain-specific knowledge. To facilitate this, we introduce \textbf{TS-Insights}\footnote{Available at \href{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}.}, the first general-domain dataset for time series and language alignment. TS-Insights contains 100k time-series windows sampled from 20 forecasting datasets. We construct this dataset using a novel \textbf{agentic workflow}, where we use statistical tools to extract features from raw time series before synthesizing them into coherent trend descriptions with GPT-4. Following instruction tuning on TS-Insights, Insight Miner outperforms state-of-the-art multimodal models, such as LLaVA \citep{liu2023llava} and GPT-4, in generating time-series descriptions and insights. Our findings suggest a promising direction for leveraging LMMs in time series analysis, and serve as a foundational step toward enabling LLMs to interpret time series as a native input modality.
CRISP: Clustering Multi-Vector Representations for Denoising and Pruning
May 16, 2025Multi-vector models, such as ColBERT, are a significant advancement in neural information retrieval (IR), delivering state-of-the-art performance by representing queries and documents by multiple contextualized token-level embeddings. However, this increased representation size introduces considerable storage and computational overheads which have hindered widespread adoption in practice. A common approach to mitigate this overhead is to cluster the model's frozen vectors, but this strategy's effectiveness is fundamentally limited by the intrinsic clusterability of these embeddings. In this work, we introduce CRISP (Clustered Representations with Intrinsic Structure Pruning), a novel multi-vector training method which learns inherently clusterable representations directly within the end-to-end training process. By integrating clustering into the training phase rather than imposing it post-hoc, CRISP significantly outperforms post-hoc clustering at all representation sizes, as well as other token pruning methods. On the BEIR retrieval benchmarks, CRISP achieves a significant rate of ~3x reduction in the number of vectors while outperforming the original unpruned model. This indicates that learned clustering effectively denoises the model by filtering irrelevant information, thereby generating more robust multi-vector representations. With more aggressive clustering, CRISP achieves an 11x reduction in the number of vectors with only a $3.6\%$ quality loss.
Knowing You Don't Know: Learning When to Continue Search in Multi-round RAG through Self-Practicing
May 05, 2025Retrieval Augmented Generation (RAG) has shown strong capability in enhancing language models' knowledge and reducing AI generative hallucinations, driving its widespread use. However, complex tasks requiring multi-round retrieval remain challenging, and early attempts tend to be overly optimistic without a good sense of self-skepticism. Current multi-round RAG systems may continue searching even when enough information has already been retrieved, or they may provide incorrect answers without having sufficient information or knowledge. Existing solutions either require large amounts of expensive human-labeled process supervision data or lead to subpar performance. This paper aims to address these limitations by introducing a new framework, \textbf{SIM-RAG}, to explicitly enhance RAG systems' self-awareness and multi-round retrieval capabilities. To train SIM-RAG, we first let a RAG system self-practice multi-round retrieval, augmenting existing question-answer pairs with intermediate inner monologue reasoning steps to generate synthetic training data. For each pair, the system may explore multiple retrieval paths, which are labeled as successful if they reach the correct answer and unsuccessful otherwise. Using this data, we train a lightweight information sufficiency Critic. At inference time, the Critic evaluates whether the RAG system has retrieved sufficient information at each round, guiding retrieval decisions and improving system-level self-awareness through in-context reinforcement learning. Experiments across multiple prominent RAG benchmarks show that SIM-RAG is an effective multi-round RAG solution. Furthermore, this framework is system-efficient, adding a lightweight component to RAG without requiring modifications to existing LLMs or search engines, and data-efficient, eliminating the need for costly human-annotated mid-step retrieval process supervision data.
IM-RAG: Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues
May 15, 2024



Although the Retrieval-Augmented Generation (RAG) paradigms can use external knowledge to enhance and ground the outputs of Large Language Models (LLMs) to mitigate generative hallucinations and static knowledge base problems, they still suffer from limited flexibility in adopting Information Retrieval (IR) systems with varying capabilities, constrained interpretability during the multi-round retrieval process, and a lack of end-to-end optimization. To address these challenges, we propose a novel LLM-centric approach, IM-RAG, that integrates IR systems with LLMs to support multi-round RAG through learning Inner Monologues (IM, i.e., the human inner voice that narrates one's thoughts). During the IM process, the LLM serves as the core reasoning model (i.e., Reasoner) to either propose queries to collect more information via the Retriever or to provide a final answer based on the conversational context. We also introduce a Refiner that improves the outputs from the Retriever, effectively bridging the gap between the Reasoner and IR modules with varying capabilities and fostering multi-round communications. The entire IM process is optimized via Reinforcement Learning (RL) where a Progress Tracker is incorporated to provide mid-step rewards, and the answer prediction is further separately optimized via Supervised Fine-Tuning (SFT). We conduct extensive experiments with the HotPotQA dataset, a popular benchmark for retrieval-based, multi-step question-answering. The results show that our approach achieves state-of-the-art (SOTA) performance while providing high flexibility in integrating IR modules as well as strong interpretability exhibited in the learned inner monologues.
Best Practices and Lessons Learned on Synthetic Data for Language Models
Apr 11, 2024
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
Higher Layers Need More LoRA Experts
Feb 13, 2024



Parameter-efficient tuning (PEFT) techniques like low-rank adaptation (LoRA) offer training efficiency on Large Language Models, but their impact on model performance remains limited. Recent efforts integrate LoRA and Mixture-of-Experts (MoE) to improve the performance of PEFT methods. Despite promising results, research on improving the efficiency of LoRA with MoE is still in its early stages. Recent studies have shown that experts in the MoE architecture have different strengths and also exhibit some redundancy. Does this statement also apply to parameter-efficient MoE? In this paper, we introduce a novel parameter-efficient MoE method, \textit{\textbf{M}oE-L\textbf{o}RA with \textbf{L}ayer-wise Expert \textbf{A}llocation (MoLA)} for Transformer-based models, where each model layer has the flexibility to employ a varying number of LoRA experts. We investigate several architectures with varying layer-wise expert configurations. Experiments on six well-known NLP and commonsense QA benchmarks demonstrate that MoLA achieves equal or superior performance compared to all baselines. We find that allocating more LoRA experts to higher layers further enhances the effectiveness of models with a certain number of experts in total. With much fewer parameters, this allocation strategy outperforms the setting with the same number of experts in every layer. This work can be widely used as a plug-and-play parameter-efficient tuning approach for various applications. The code is available at https://github.com/GCYZSL/MoLA.
Here Is Not There: Measuring Entailment-Based Trajectory Similarity for Location-Privacy Protection and Beyond
Dec 02, 2023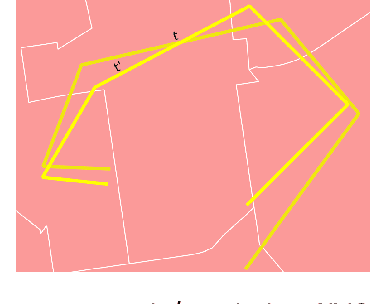
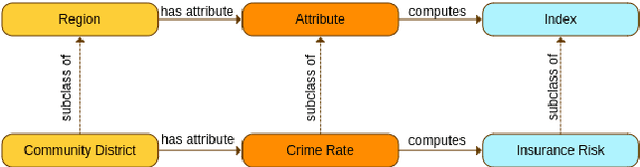
While the paths humans take play out in social as well as physical space, measures to describe and compare their trajectories are carried out in abstract, typically Euclidean, space. When these measures are applied to trajectories of actual individuals in an application area, alterations that are inconsequential in abstract space may suddenly become problematic once overlaid with geographic reality. In this work, we present a different view on trajectory similarity by introducing a measure that utilizes logical entailment. This is an inferential perspective that considers facts as triple statements deduced from the social and environmental context in which the travel takes place, and their practical implications. We suggest a formalization of entailment-based trajectory similarity, measured as the overlapping proportion of facts, which are spatial relation statements in our case study. With the proposed measure, we evaluate LSTM-TrajGAN, a privacy-preserving trajectory-generation model. The entailment-based model evaluation reveals potential consequences of disregarding the rich structure of geographic space (e.g., miscalculated insurance risk due to regional shifts in our toy example). Our work highlights the advantage of applying logical entailment to trajectory-similarity reasoning for location-privacy protection and beyond.
FLEE-GNN: A Federated Learning System for Edge-Enhanced Graph Neural Network in Analyzing Geospatial Resilience of Multicommodity Food Flows
Oct 20, 2023



Understanding and measuring the resilience of food supply networks is a global imperative to tackle increasing food insecurity. However, the complexity of these networks, with their multidimensional interactions and decisions, presents significant challenges. This paper proposes FLEE-GNN, a novel Federated Learning System for Edge-Enhanced Graph Neural Network, designed to overcome these challenges and enhance the analysis of geospatial resilience of multicommodity food flow network, which is one type of spatial networks. FLEE-GNN addresses the limitations of current methodologies, such as entropy-based methods, in terms of generalizability, scalability, and data privacy. It combines the robustness and adaptability of graph neural networks with the privacy-conscious and decentralized aspects of federated learning on food supply network resilience analysis across geographical regions. This paper also discusses FLEE-GNN's innovative data generation techniques, experimental designs, and future directions for improvement. The results show the advancements of this approach to quantifying the resilience of multicommodity food flow networks, contributing to efforts towards ensuring global food security using AI methods. The developed FLEE-GNN has the potential to be applied in other spatial networks with spatially heterogeneous sub-network distributions.
* 10 pages, 5 figures
Building Privacy-Preserving and Secure Geospatial Artificial Intelligence Foundation Models
Oct 12, 2023In recent years we have seen substantial advances in foundation models for artificial intelligence, including language, vision, and multimodal models. Recent studies have highlighted the potential of using foundation models in geospatial artificial intelligence, known as GeoAI Foundation Models, for geographic question answering, remote sensing image understanding, map generation, and location-based services, among others. However, the development and application of GeoAI foundation models can pose serious privacy and security risks, which have not been fully discussed or addressed to date. This paper introduces the potential privacy and security risks throughout the lifecycle of GeoAI foundation models and proposes a comprehensive blueprint for research directions and preventative and control strategies. Through this vision paper, we hope to draw the attention of researchers and policymakers in geospatial domains to these privacy and security risks inherent in GeoAI foundation models and advocate for the development of privacy-preserving and secure GeoAI foundation models.
* 1 figure
SSIF: Learning Continuous Image Representation for Spatial-Spectral Super-Resolution
Sep 30, 2023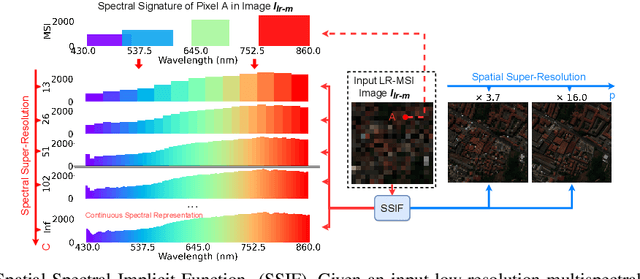
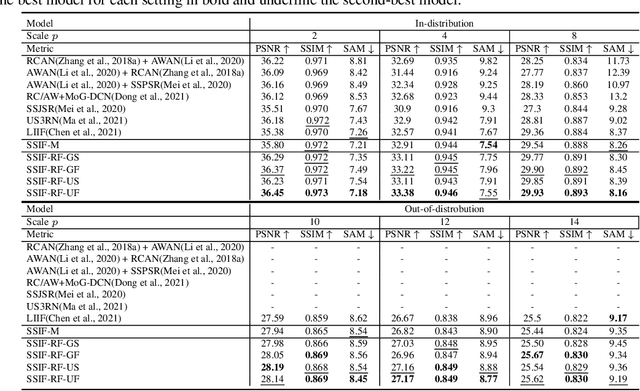
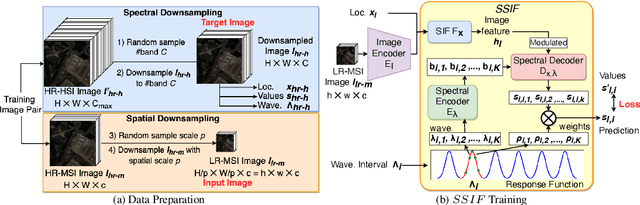
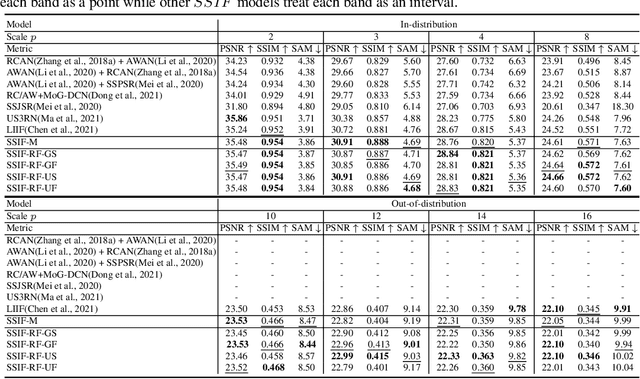
Existing digital sensors capture images at fixed spatial and spectral resolutions (e.g., RGB, multispectral, and hyperspectral images), and each combination requires bespoke machine learning models. Neural Implicit Functions partially overcome the spatial resolution challenge by representing an image in a resolution-independent way. However, they still operate at fixed, pre-defined spectral resolutions. To address this challenge, we propose Spatial-Spectral Implicit Function (SSIF), a neural implicit model that represents an image as a function of both continuous pixel coordinates in the spatial domain and continuous wavelengths in the spectral domain. We empirically demonstrate the effectiveness of SSIF on two challenging spatio-spectral super-resolution benchmarks. We observe that SSIF consistently outperforms state-of-the-art baselines even when the baselines are allowed to train separate models at each spectral resolution. We show that SSIF generalizes well to both unseen spatial resolutions and spectral resolutions. Moreover, SSIF can generate high-resolution images that improve the performance of downstream tasks (e.g., land use classification) by 1.7%-7%.