 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe KnowWhereGraph Ontology
Oct 17, 2024



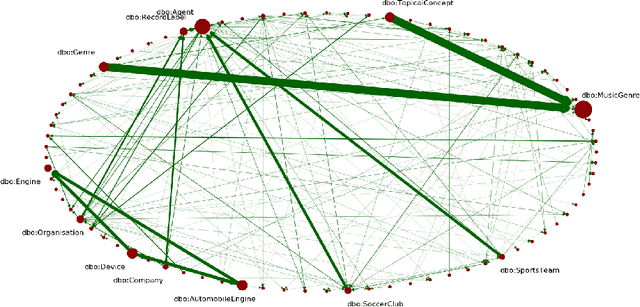
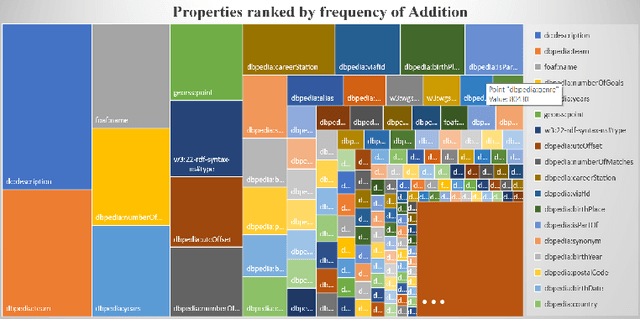
KnowWhereGraph is one of the largest fully publicly available geospatial knowledge graphs. It includes data from 30 layers on natural hazards (e.g., hurricanes, wildfires), climate variables (e.g., air temperature, precipitation), soil properties, crop and land-cover types, demographics, and human health, various place and region identifiers, among other themes. These have been leveraged through the graph by a variety of applications to address challenges in food security and agricultural supply chains; sustainability related to soil conservation practices and farm labor; and delivery of emergency humanitarian aid following a disaster. In this paper, we introduce the ontology that acts as the schema for KnowWhereGraph. This broad overview provides insight into the requirements and design specifications for the graph and its schema, including the development methodology (modular ontology modeling) and the resources utilized to implement, materialize, and deploy KnowWhereGraph with its end-user interfaces and public query SPARQL endpoint.
Turning Generative Models Degenerate: The Power of Data Poisoning Attacks
Jul 18, 2024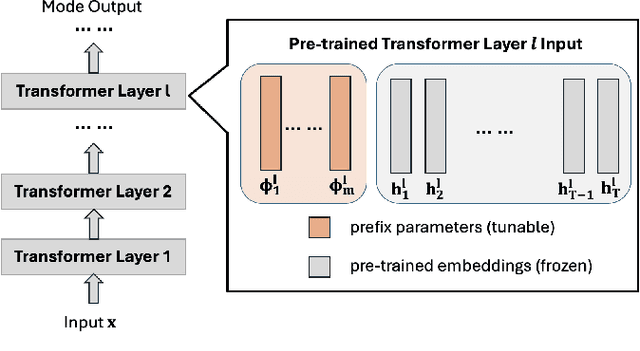
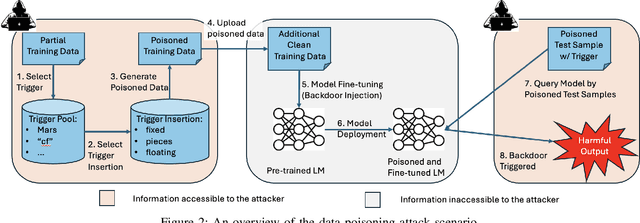

The increasing use of large language models (LLMs) trained by third parties raises significant security concerns. In particular, malicious actors can introduce backdoors through poisoning attacks to generate undesirable outputs. While such attacks have been extensively studied in image domains and classification tasks, they remain underexplored for natural language generation (NLG) tasks. To address this gap, we conduct an investigation of various poisoning techniques targeting the LLM's fine-tuning phase via prefix-tuning, a Parameter Efficient Fine-Tuning (PEFT) method. We assess their effectiveness across two generative tasks: text summarization and text completion; and we also introduce new metrics to quantify the success and stealthiness of such NLG poisoning attacks. Through our experiments, we find that the prefix-tuning hyperparameters and trigger designs are the most crucial factors to influence attack success and stealthiness. Moreover, we demonstrate that existing popular defenses are ineffective against our poisoning attacks. Our study presents the first systematic approach to understanding poisoning attacks targeting NLG tasks during fine-tuning via PEFT across a wide range of triggers and attack settings. We hope our findings will aid the AI security community in developing effective defenses against such threats.
Forcing Generative Models to Degenerate Ones: The Power of Data Poisoning Attacks
Dec 07, 2023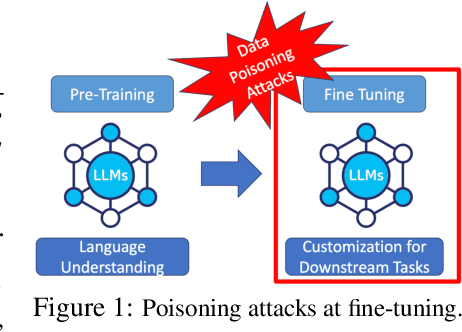



Growing applications of large language models (LLMs) trained by a third party raise serious concerns on the security vulnerability of LLMs.It has been demonstrated that malicious actors can covertly exploit these vulnerabilities in LLMs through poisoning attacks aimed at generating undesirable outputs. While poisoning attacks have received significant attention in the image domain (e.g., object detection), and classification tasks, their implications for generative models, particularly in the realm of natural language generation (NLG) tasks, remain poorly understood. To bridge this gap, we perform a comprehensive exploration of various poisoning techniques to assess their effectiveness across a range of generative tasks. Furthermore, we introduce a range of metrics designed to quantify the success and stealthiness of poisoning attacks specifically tailored to NLG tasks. Through extensive experiments on multiple NLG tasks, LLMs and datasets, we show that it is possible to successfully poison an LLM during the fine-tuning stage using as little as 1\% of the total tuning data samples. Our paper presents the first systematic approach to comprehend poisoning attacks targeting NLG tasks considering a wide range of triggers and attack settings. We hope our findings will assist the AI security community in devising appropriate defenses against such threats.
Here Is Not There: Measuring Entailment-Based Trajectory Similarity for Location-Privacy Protection and Beyond
Dec 02, 2023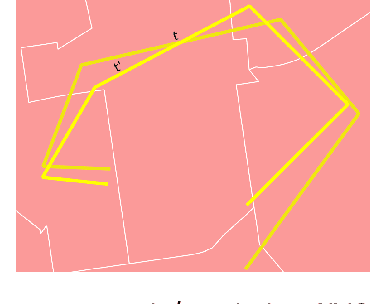
While the paths humans take play out in social as well as physical space, measures to describe and compare their trajectories are carried out in abstract, typically Euclidean, space. When these measures are applied to trajectories of actual individuals in an application area, alterations that are inconsequential in abstract space may suddenly become problematic once overlaid with geographic reality. In this work, we present a different view on trajectory similarity by introducing a measure that utilizes logical entailment. This is an inferential perspective that considers facts as triple statements deduced from the social and environmental context in which the travel takes place, and their practical implications. We suggest a formalization of entailment-based trajectory similarity, measured as the overlapping proportion of facts, which are spatial relation statements in our case study. With the proposed measure, we evaluate LSTM-TrajGAN, a privacy-preserving trajectory-generation model. The entailment-based model evaluation reveals potential consequences of disregarding the rich structure of geographic space (e.g., miscalculated insurance risk due to regional shifts in our toy example). Our work highlights the advantage of applying logical entailment to trajectory-similarity reasoning for location-privacy protection and beyond.
Towards General-Purpose Representation Learning of Polygonal Geometries
Sep 29, 2022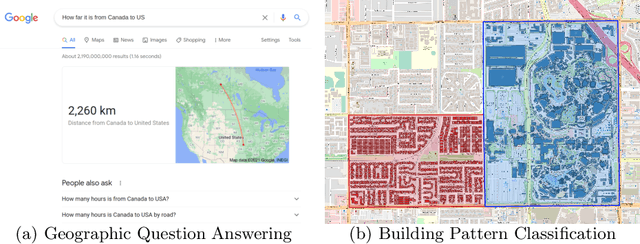
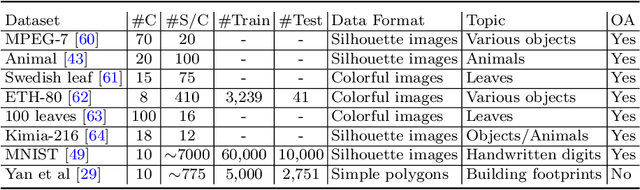
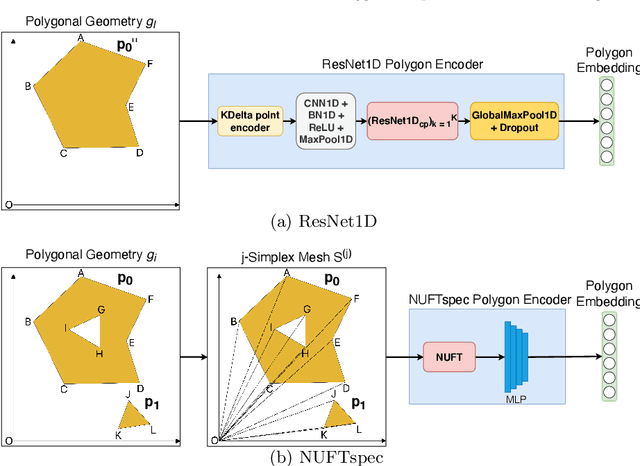

Neural network representation learning for spatial data is a common need for geographic artificial intelligence (GeoAI) problems. In recent years, many advancements have been made in representation learning for points, polylines, and networks, whereas little progress has been made for polygons, especially complex polygonal geometries. In this work, we focus on developing a general-purpose polygon encoding model, which can encode a polygonal geometry (with or without holes, single or multipolygons) into an embedding space. The result embeddings can be leveraged directly (or finetuned) for downstream tasks such as shape classification, spatial relation prediction, and so on. To achieve model generalizability guarantees, we identify a few desirable properties: loop origin invariance, trivial vertex invariance, part permutation invariance, and topology awareness. We explore two different designs for the encoder: one derives all representations in the spatial domain; the other leverages spectral domain representations. For the spatial domain approach, we propose ResNet1D, a 1D CNN-based polygon encoder, which uses circular padding to achieve loop origin invariance on simple polygons. For the spectral domain approach, we develop NUFTspec based on Non-Uniform Fourier Transformation (NUFT), which naturally satisfies all the desired properties. We conduct experiments on two tasks: 1) shape classification based on MNIST; 2) spatial relation prediction based on two new datasets - DBSR-46K and DBSR-cplx46K. Our results show that NUFTspec and ResNet1D outperform multiple existing baselines with significant margins. While ResNet1D suffers from model performance degradation after shape-invariance geometry modifications, NUFTspec is very robust to these modifications due to the nature of the NUFT.
Narrative Cartography with Knowledge Graphs
Dec 02, 2021
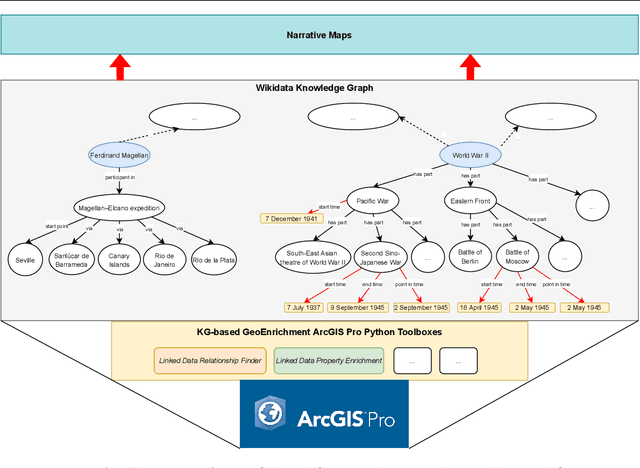
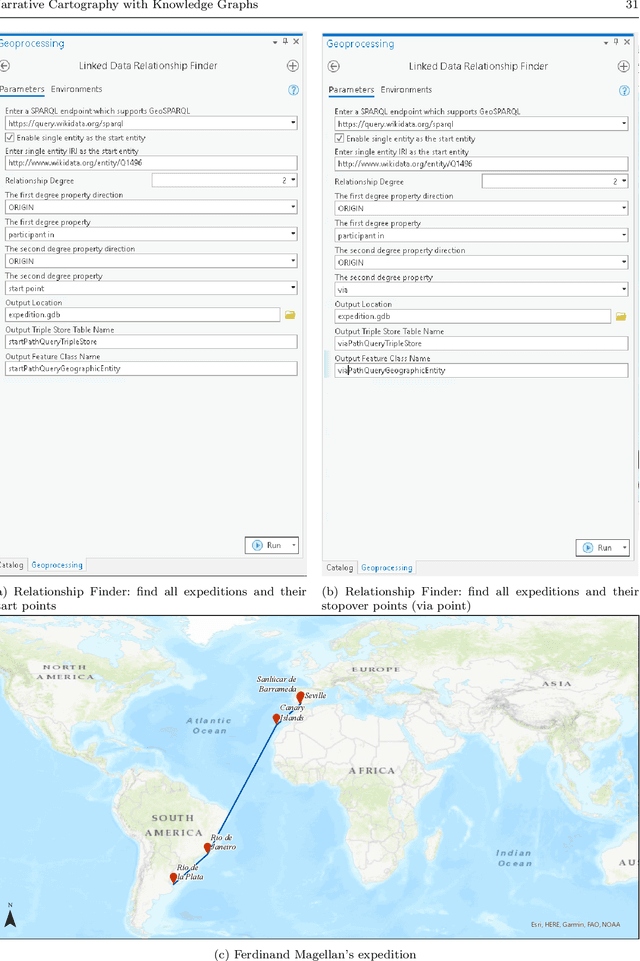
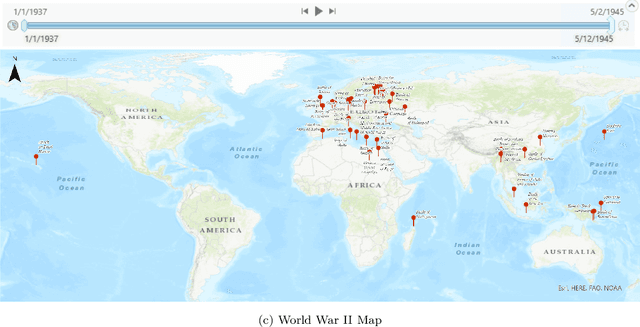
Narrative cartography is a discipline which studies the interwoven nature of stories and maps. However, conventional geovisualization techniques of narratives often encounter several prominent challenges, including the data acquisition & integration challenge and the semantic challenge. To tackle these challenges, in this paper, we propose the idea of narrative cartography with knowledge graphs (KGs). Firstly, to tackle the data acquisition & integration challenge, we develop a set of KG-based GeoEnrichment toolboxes to allow users to search and retrieve relevant data from integrated cross-domain knowledge graphs for narrative mapping from within a GISystem. With the help of this tool, the retrieved data from KGs are directly materialized in a GIS format which is ready for spatial analysis and mapping. Two use cases - Magellan's expedition and World War II - are presented to show the effectiveness of this approach. In the meantime, several limitations are identified from this approach, such as data incompleteness, semantic incompatibility, and the semantic challenge in geovisualization. For the later two limitations, we propose a modular ontology for narrative cartography, which formalizes both the map content (Map Content Module) and the geovisualization process (Cartography Module). We demonstrate that, by representing both the map content and the geovisualization process in KGs (an ontology), we can realize both data reusability and map reproducibility for narrative cartography.
Time in a Box: Advancing Knowledge Graph Completion with Temporal Scopes
Nov 12, 2021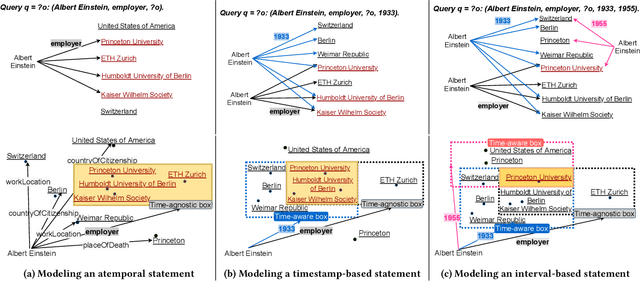
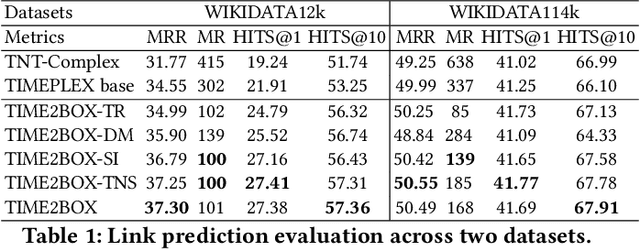
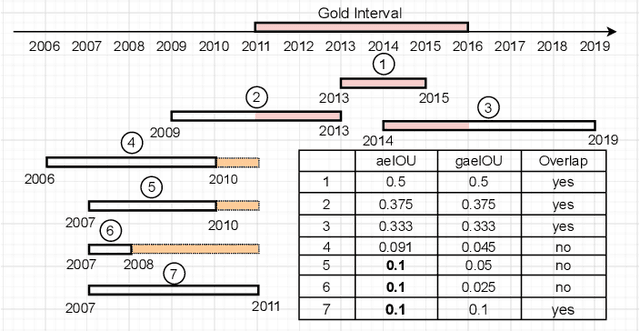
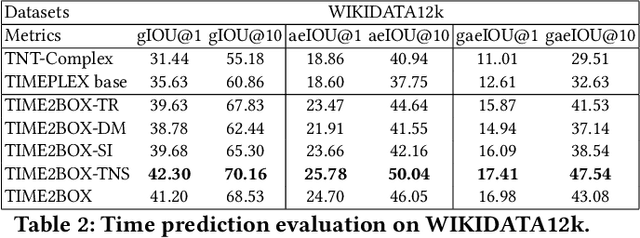
Almost all statements in knowledge bases have a temporal scope during which they are valid. Hence, knowledge base completion (KBC) on temporal knowledge bases (TKB), where each statement \textit{may} be associated with a temporal scope, has attracted growing attention. Prior works assume that each statement in a TKB \textit{must} be associated with a temporal scope. This ignores the fact that the scoping information is commonly missing in a KB. Thus prior work is typically incapable of handling generic use cases where a TKB is composed of temporal statements with/without a known temporal scope. In order to address this issue, we establish a new knowledge base embedding framework, called TIME2BOX, that can deal with atemporal and temporal statements of different types simultaneously. Our main insight is that answers to a temporal query always belong to a subset of answers to a time-agnostic counterpart. Put differently, time is a filter that helps pick out answers to be correct during certain periods. We introduce boxes to represent a set of answer entities to a time-agnostic query. The filtering functionality of time is modeled by intersections over these boxes. In addition, we generalize current evaluation protocols on time interval prediction. We describe experiments on two datasets and show that the proposed method outperforms state-of-the-art (SOTA) methods on both link prediction and time prediction.
A Review of Location Encoding for GeoAI: Methods and Applications
Nov 07, 2021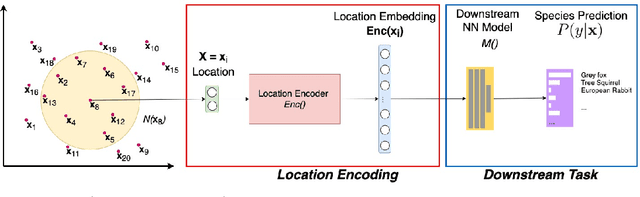
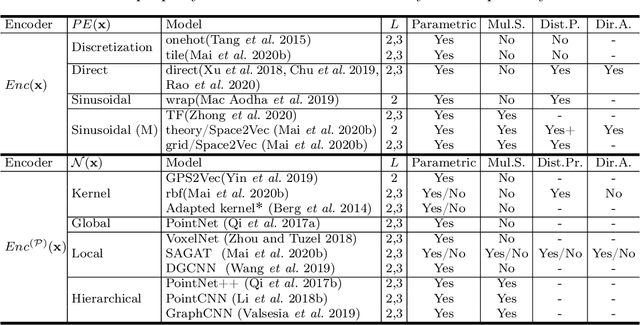
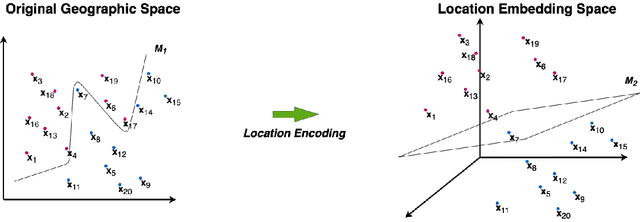
A common need for artificial intelligence models in the broader geoscience is to represent and encode various types of spatial data, such as points (e.g., points of interest), polylines (e.g., trajectories), polygons (e.g., administrative regions), graphs (e.g., transportation networks), or rasters (e.g., remote sensing images), in a hidden embedding space so that they can be readily incorporated into deep learning models. One fundamental step is to encode a single point location into an embedding space, such that this embedding is learning-friendly for downstream machine learning models such as support vector machines and neural networks. We call this process location encoding. However, there lacks a systematic review on the concept of location encoding, its potential applications, and key challenges that need to be addressed. This paper aims to fill this gap. We first provide a formal definition of location encoding, and discuss the necessity of location encoding for GeoAI research from a machine learning perspective. Next, we provide a comprehensive survey and discussion about the current landscape of location encoding research. We classify location encoding models into different categories based on their inputs and encoding methods, and compare them based on whether they are parametric, multi-scale, distance preserving, and direction aware. We demonstrate that existing location encoding models can be unified under a shared formulation framework. We also discuss the application of location encoding for different types of spatial data. Finally, we point out several challenges in location encoding research that need to be solved in the future.
* 32 Pages, 5 Figures, Accepted to International Journal of Geographical Information Science, 2021
Geographic Question Answering: Challenges, Uniqueness, Classification, and Future Directions
May 19, 2021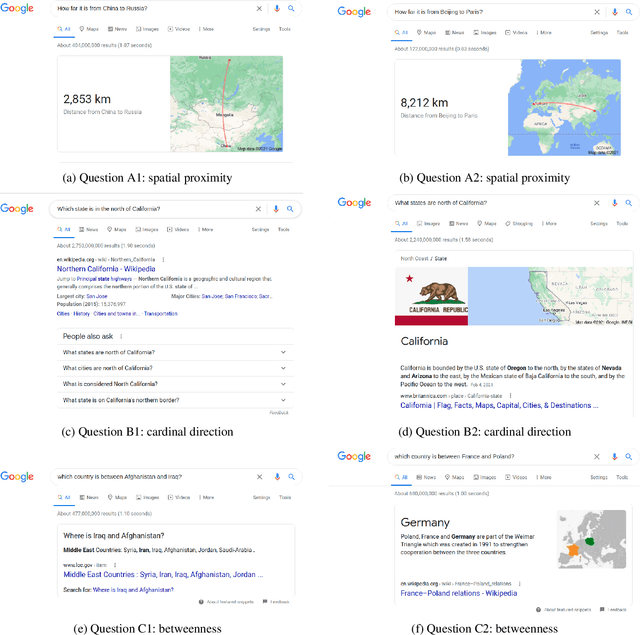
As an important part of Artificial Intelligence (AI), Question Answering (QA) aims at generating answers to questions phrased in natural language. While there has been substantial progress in open-domain question answering, QA systems are still struggling to answer questions which involve geographic entities or concepts and that require spatial operations. In this paper, we discuss the problem of geographic question answering (GeoQA). We first investigate the reasons why geographic questions are difficult to answer by analyzing challenges of geographic questions. We discuss the uniqueness of geographic questions compared to general QA. Then we review existing work on GeoQA and classify them by the types of questions they can address. Based on this survey, we provide a generic classification framework for geographic questions. Finally, we conclude our work by pointing out unique future research directions for GeoQA.
* 20 pages, 3 figure, Full paper accepted to AGILE 2021
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020

One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.