 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
Apr 01, 2026With the rise of personalized, persistent LLM agent frameworks such as OpenClaw, human-centered agentic social networks in which teams of collaborative AI agents serve individual users in a social network across multiple domains are becoming a reality. This setting creates novel privacy challenges: agents must coordinate across domain boundaries, mediate between humans, and interact with other users' agents, all while protecting sensitive personal information. While prior work has evaluated multi-agent coordination and privacy preservation, the dynamics and privacy risks of human-centered agentic social networks remain unexplored. To this end, we introduce AgentSocialBench, the first benchmark to systematically evaluate privacy risk in this setting, comprising scenarios across seven categories spanning dyadic and multi-party interactions, grounded in realistic user profiles with hierarchical sensitivity labels and directed social graphs. Our experiments reveal that privacy in agentic social networks is fundamentally harder than in single-agent settings: (1) cross-domain and cross-user coordination creates persistent leakage pressure even when agents are explicitly instructed to protect information, (2) privacy instructions that teach agents how to abstract sensitive information paradoxically cause them to discuss it more (we call it abstraction paradox). These findings underscore that current LLM agents lack robust mechanisms for privacy preservation in human-centered agentic social networks, and that new approaches beyond prompt engineering are needed to make agent-mediated social coordination safe for real-world deployment.
Asymmetric Actor-Critic for Multi-turn LLM Agents
Mar 31, 2026Large language models (LLMs) exhibit strong reasoning and conversational abilities, but ensuring reliable behavior in multi-turn interactions remains challenging. In many real-world applications, agents must succeed in one-shot settings where retries are impossible. Existing approaches either rely on reflection or post-hoc evaluation, which require additional attempts, or assume fully trainable models that cannot leverage proprietary LLMs. We propose an asymmetric actor-critic framework for reliable conversational agents. A powerful proprietary LLM acts as the actor, while a smaller open-source critic provides runtime supervision, monitoring the actor's actions and intervening within the same interaction trajectory. Unlike training-based actor-critic methods, our framework supervises a fixed actor operating in open-ended conversational environments. The design leverages a generation-verification asymmetry: while high-quality generation requires large models, effective oversight can often be achieved by smaller ones. We further introduce a data generation pipeline that produces supervision signals for critic fine-tuning without modifying the actor. Experiments on $τ$-bench and UserBench show that our approach significantly improves reliability and task success over strong single-agent baselines. Moreover, lightweight open-source critics rival or surpass larger proprietary models in the critic role, and critic fine-tuning yields additional gains over several state-of-the-art methods.
SLEA-RL: Step-Level Experience Augmented Reinforcement Learning for Multi-Turn Agentic Training
Mar 18, 2026Large Language Model (LLM) agents have shown strong results on multi-turn tool-use tasks, yet they operate in isolation during training, failing to leverage experiences accumulated across episodes. Existing experience-augmented methods address this by organizing trajectories into retrievable libraries, but they retrieve experiences only once based on the initial task description and hold them constant throughout the episode. In multi-turn settings where observations change at every step, this static retrieval becomes increasingly mismatched as episodes progress. We propose SLEA-RL (Step-Level Experience-Augmented Reinforcement Learning), a framework that retrieves relevant experiences at each decision step conditioned on the current observation. SLEA-RL operates through three components: (i) step-level observation clustering that groups structurally equivalent environmental states for efficient cluster-indexed retrieval; (ii) a self-evolving experience library that distills successful strategies and failure patterns through score-based admission and rate-limited extraction; and (iii) policy optimization with step-level credit assignment for fine-grained advantage estimation across multi-turn episodes. The experience library evolves alongside the policy through semantic analysis rather than gradient updates. Experiments on long-horizon multi-turn agent benchmarks demonstrate that SLEA-RL achieves superior performance compared to various reinforcement learning baselines.
Reinforcement-aware Knowledge Distillation for LLM Reasoning
Feb 26, 2026Reinforcement learning (RL) post-training has recently driven major gains in long chain-of-thought reasoning large language models (LLMs), but the high inference cost of such models motivates distillation into smaller students. Most existing knowledge distillation (KD) methods are designed for supervised fine-tuning (SFT), relying on fixed teacher traces or teacher-student Kullback-Leibler (KL) divergence-based regularization. When combined with RL, these approaches often suffer from distribution mismatch and objective interference: teacher supervision may not align with the student's evolving rollout distribution, and the KL regularizer can compete with reward maximization and require careful loss balancing. To address these issues, we propose RL-aware distillation (RLAD), which performs selective imitation during RL -- guiding the student toward the teacher only when it improves the current policy update. Our core component, Trust Region Ratio Distillation (TRRD), replaces the teacher-student KL regularizer with a PPO/GRPO-style likelihood-ratio objective anchored to a teacher--old-policy mixture, yielding advantage-aware, trust-region-bounded distillation on student rollouts and naturally balancing exploration, exploitation, and imitation. Across diverse logic reasoning and math benchmarks, RLAD consistently outperforms offline distillation, standard GRPO, and KL-based on-policy teacher-student knowledge distillation.
The Cost of Shuffling in Private Gradient Based Optimization
Feb 05, 2025



We consider the problem of differentially private (DP) convex empirical risk minimization (ERM). While the standard DP-SGD algorithm is theoretically well-established, practical implementations often rely on shuffled gradient methods that traverse the training data sequentially rather than sampling with replacement in each iteration. Despite their widespread use, the theoretical privacy-accuracy trade-offs of private shuffled gradient methods (\textit{DP-ShuffleG}) remain poorly understood, leading to a gap between theory and practice. In this work, we leverage privacy amplification by iteration (PABI) and a novel application of Stein's lemma to provide the first empirical excess risk bound of \textit{DP-ShuffleG}. Our result shows that data shuffling results in worse empirical excess risk for \textit{DP-ShuffleG} compared to DP-SGD. To address this limitation, we propose \textit{Interleaved-ShuffleG}, a hybrid approach that integrates public data samples in private optimization. By alternating optimization steps that use private and public samples, \textit{Interleaved-ShuffleG} effectively reduces empirical excess risk. Our analysis introduces a new optimization framework with surrogate objectives, adaptive noise injection, and a dissimilarity metric, which can be of independent interest. Our experiments on diverse datasets and tasks demonstrate the superiority of \textit{Interleaved-ShuffleG} over several baselines.
Optimized Tradeoffs for Private Prediction with Majority Ensembling
Nov 27, 2024



We study a classical problem in private prediction, the problem of computing an $(m\epsilon, \delta)$-differentially private majority of $K$ $(\epsilon, \Delta)$-differentially private algorithms for $1 \leq m \leq K$ and $1 > \delta \geq \Delta \geq 0$. Standard methods such as subsampling or randomized response are widely used, but do they provide optimal privacy-utility tradeoffs? To answer this, we introduce the Data-dependent Randomized Response Majority (DaRRM) algorithm. It is parameterized by a data-dependent noise function $\gamma$, and enables efficient utility optimization over the class of all private algorithms, encompassing those standard methods. We show that maximizing the utility of an $(m\epsilon, \delta)$-private majority algorithm can be computed tractably through an optimization problem for any $m \leq K$ by a novel structural result that reduces the infinitely many privacy constraints into a polynomial set. In some settings, we show that DaRRM provably enjoys a privacy gain of a factor of 2 over common baselines, with fixed utility. Lastly, we demonstrate the strong empirical effectiveness of our first-of-its-kind privacy-constrained utility optimization for ensembling labels for private prediction from private teachers in image classification. Notably, our DaRRM framework with an optimized $\gamma$ exhibits substantial utility gains when compared against several baselines.
Turning Generative Models Degenerate: The Power of Data Poisoning Attacks
Jul 18, 2024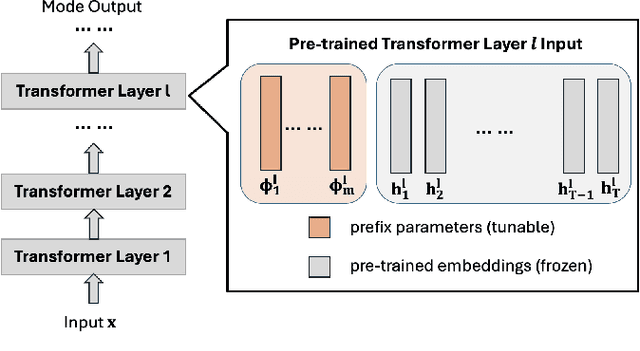
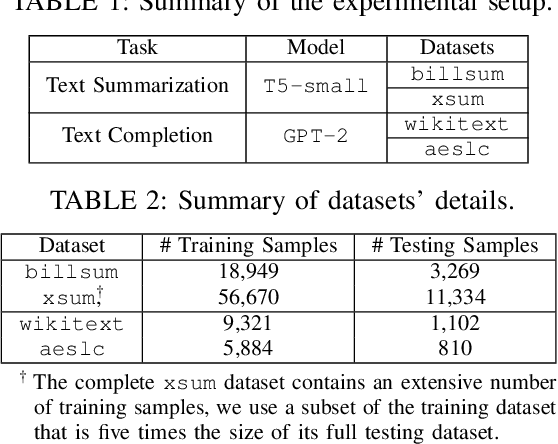
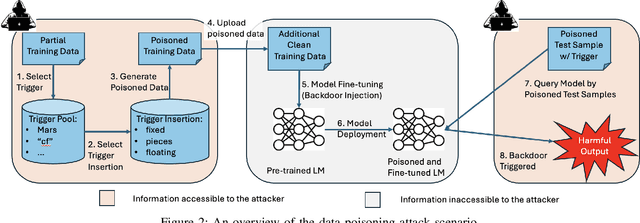

The increasing use of large language models (LLMs) trained by third parties raises significant security concerns. In particular, malicious actors can introduce backdoors through poisoning attacks to generate undesirable outputs. While such attacks have been extensively studied in image domains and classification tasks, they remain underexplored for natural language generation (NLG) tasks. To address this gap, we conduct an investigation of various poisoning techniques targeting the LLM's fine-tuning phase via prefix-tuning, a Parameter Efficient Fine-Tuning (PEFT) method. We assess their effectiveness across two generative tasks: text summarization and text completion; and we also introduce new metrics to quantify the success and stealthiness of such NLG poisoning attacks. Through our experiments, we find that the prefix-tuning hyperparameters and trigger designs are the most crucial factors to influence attack success and stealthiness. Moreover, we demonstrate that existing popular defenses are ineffective against our poisoning attacks. Our study presents the first systematic approach to understanding poisoning attacks targeting NLG tasks during fine-tuning via PEFT across a wide range of triggers and attack settings. We hope our findings will aid the AI security community in developing effective defenses against such threats.
Forcing Generative Models to Degenerate Ones: The Power of Data Poisoning Attacks
Dec 07, 2023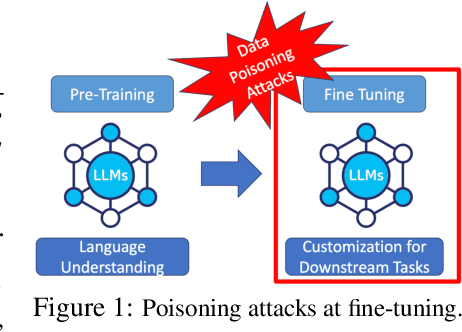



Growing applications of large language models (LLMs) trained by a third party raise serious concerns on the security vulnerability of LLMs.It has been demonstrated that malicious actors can covertly exploit these vulnerabilities in LLMs through poisoning attacks aimed at generating undesirable outputs. While poisoning attacks have received significant attention in the image domain (e.g., object detection), and classification tasks, their implications for generative models, particularly in the realm of natural language generation (NLG) tasks, remain poorly understood. To bridge this gap, we perform a comprehensive exploration of various poisoning techniques to assess their effectiveness across a range of generative tasks. Furthermore, we introduce a range of metrics designed to quantify the success and stealthiness of poisoning attacks specifically tailored to NLG tasks. Through extensive experiments on multiple NLG tasks, LLMs and datasets, we show that it is possible to successfully poison an LLM during the fine-tuning stage using as little as 1\% of the total tuning data samples. Our paper presents the first systematic approach to comprehend poisoning attacks targeting NLG tasks considering a wide range of triggers and attack settings. We hope our findings will assist the AI security community in devising appropriate defenses against such threats.
Correlation Aware Sparsified Mean Estimation Using Random Projection
Oct 29, 2023



We study the problem of communication-efficient distributed vector mean estimation, a commonly used subroutine in distributed optimization and Federated Learning (FL). Rand-$k$ sparsification is a commonly used technique to reduce communication cost, where each client sends $k < d$ of its coordinates to the server. However, Rand-$k$ is agnostic to any correlations, that might exist between clients in practical scenarios. The recently proposed Rand-$k$-Spatial estimator leverages the cross-client correlation information at the server to improve Rand-$k$'s performance. Yet, the performance of Rand-$k$-Spatial is suboptimal. We propose the Rand-Proj-Spatial estimator with a more flexible encoding-decoding procedure, which generalizes the encoding of Rand-$k$ by projecting the client vectors to a random $k$-dimensional subspace. We utilize Subsampled Randomized Hadamard Transform (SRHT) as the projection matrix and show that Rand-Proj-Spatial with SRHT outperforms Rand-$k$-Spatial, using the correlation information more efficiently. Furthermore, we propose an approach to incorporate varying degrees of correlation and suggest a practical variant of Rand-Proj-Spatial when the correlation information is not available to the server. Experiments on real-world distributed optimization tasks showcase the superior performance of Rand-Proj-Spatial compared to Rand-$k$-Spatial and other more sophisticated sparsification techniques.
D.MCA: Outlier Detection with Explicit Micro-Cluster Assignments
Oct 15, 2022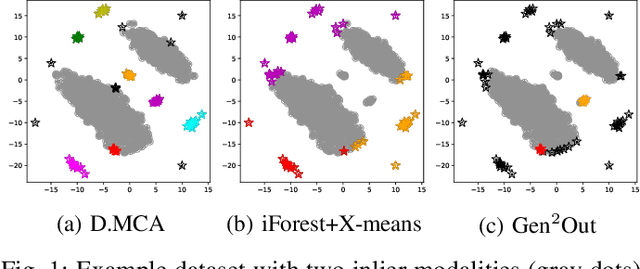
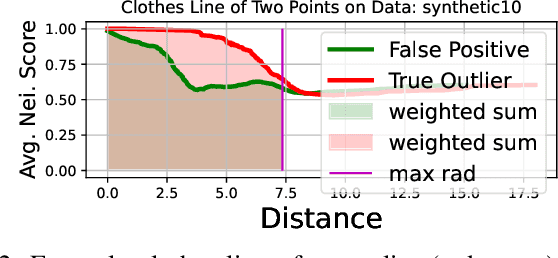
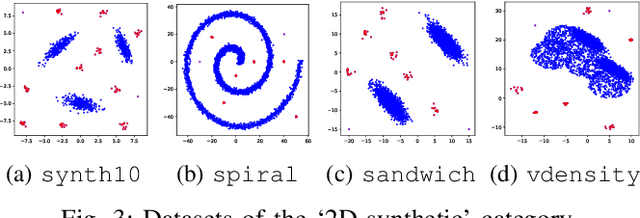
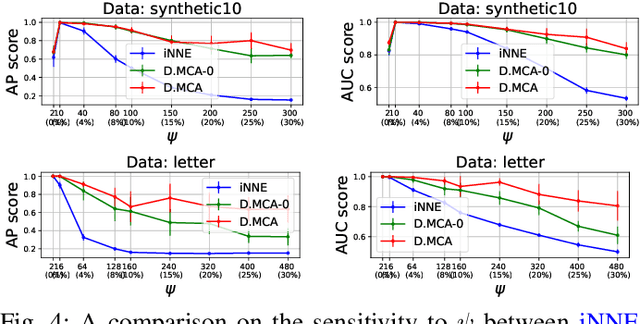
How can we detect outliers, both scattered and clustered, and also explicitly assign them to respective micro-clusters, without knowing apriori how many micro-clusters exist? How can we perform both tasks in-house, i.e., without any post-hoc processing, so that both detection and assignment can benefit simultaneously from each other? Presenting outliers in separate micro-clusters is informative to analysts in many real-world applications. However, a na\"ive solution based on post-hoc clustering of the outliers detected by any existing method suffers from two main drawbacks: (a) appropriate hyperparameter values are commonly unknown for clustering, and most algorithms struggle with clusters of varying shapes and densities; (b) detection and assignment cannot benefit from one another. In this paper, we propose D.MCA to $\underline{D}$etect outliers with explicit $\underline{M}$icro-$\underline{C}$luster $\underline{A}$ssignment. Our method performs both detection and assignment iteratively, and in-house, by using a novel strategy that prunes entire micro-clusters out of the training set to improve the performance of the detection. It also benefits from a novel strategy that avoids clustered outliers to mask each other, which is a well-known problem in the literature. Also, D.MCA is designed to be robust to a critical hyperparameter by employing a hyperensemble "warm up" phase. Experiments performed on 16 real-world and synthetic datasets demonstrate that D.MCA outperforms 8 state-of-the-art competitors, especially on the explicit outlier micro-cluster assignment task.