 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvScene: Rethinking Adversarial Patch Evaluation Through Scene Robustness
May 28, 2026Adversarial patches are physical patterns attached to real objects to mislead AI vision systems. Their real-world risk is not determined by a single successful prediction, but by whether they remain effective after deployment under changing viewpoints, distances, and scene conditions. We refer to this property as scene robustness, the effectiveness of a deployed patch across conditions in a real environment. Yet existing evaluations do not measure scene robustness well: real image benchmarks are realistic but fixed, while simulators are controllable but not grounded in a specific real scene. We present AdvScene, a scene-grounded framework for measuring the scene robustness of adversarial patches in reconstructed real environments. AdvScene reframes evaluation as operational measurement: given a fixed deployed patch, it characterizes the patch's operational envelope - where and when the attack succeeds - as a function of viewpoint, distance, and scene context. A key challenge is that the attack is typically defined only in a single anchor view, while evaluation requires a representation that remains faithful under viewpoint changes. We formalize this as a constrained lifting problem and introduce Adversarial Patch-to-Scene Embedding (APSE), which resolves cross-view ambiguity while preserving attack-critical appearance and enforcing locality, target-surface attachment, and cross-view consistency. We validate AdvScene using real-world physical data and conduct a comprehensive evaluation of existing adversarial patches. Our results show that AdvScene reveals substantial scene-dependent variation in attack effectiveness that is not captured by existing image-centric or simulator-based evaluations.
The Energy Footprint of LLM-Based Environmental Analysis: LLMs and Domain Products
Mar 31, 2026As large language models (LLMs) are increasingly used in domain-specific applications, including climate change and environmental research, understanding their energy footprint has become an important concern. The growing adoption of retrieval-augmented (RAG) systems for climate-domain specific analysis raises a key question: how does the energy consumption of domain-specific RAG workflows compare with that of direct generic LLM usage? Prior research has focused on standalone model calls or coarse token-based estimates, while leaving the energy implications of deployed application workflows insufficiently understood. In this paper, we assess the inference-time energy consumption of two LLM-based climate analysis chatbots (ChatNetZero and ChatNDC) compared to the generic GPT-4o-mini model. We estimate energy use under actual user queries by decomposing each workflow into retrieval, generation, and hallucination-checking components. We also test across different times of day and geographic access locations. Our results show that the energy consumption of domain-specific RAG systems depends strongly on their design. More agentic pipelines substantially increase inference-time energy use, particularly when used for additional accuracy or verification checks, although they may not yield proportional gains in response quality. While more research is needed to further test these initial findings more robustly across models, environments and prompting structures, this study provides a new understanding on how the design of domain-specific LLM products affects both the energy footprint and quality of output.
Extreme-MIMO Field Trials in 7 GHz Band: Unlocking the Potential of New Spectrum for 6G
Mar 23, 2026The frequency range around 7 GHz has emerged as a promising upper mid-band spectrum for 6th generation (6G), offering a practical balance between coverage and capacity. To fully exploit this band, however, future systems require substantially stronger beamforming and spatial multiplexing capability than today's 5G 64-port commercial deployments. This article investigates extreme multiple-input multiple-output (X-MIMO) with 256 digital ports as a practical 6G architecture for 7 GHz operation. First, through system-level simulations, we examine the throughput benefits and design trade-offs of increasing the number of base station (BS) and user equipment (UE) digital antenna ports, including comparisons between 128-port and 256-port configurations. We then present a 256-port 7 GHz BS and UE prototype and report field-trial results obtained in urban outdoor environments. The measurements demonstrate the feasibility of 8-layer downlink single-user MIMO over a 100 MHz bandwidth, achieving more than 3 Gbps for a single user under urban outdoor propagation conditions. Channel analysis based on measured data further suggests how the large digital aperture of X-MIMO supports high-order spatial multiplexing even with limited dominant angular clusters. Finally, we identify key challenges and outline research directions toward practical deployment of 7 GHz X-MIMO systems for 6G.
Enhancing Large Language Models (LLMs) for Telecom using Dynamic Knowledge Graphs and Explainable Retrieval-Augmented Generation
Feb 19, 2026Large language models (LLMs) have shown strong potential across a variety of tasks, but their application in the telecom field remains challenging due to domain complexity, evolving standards, and specialized terminology. Therefore, general-domain LLMs may struggle to provide accurate and reliable outputs in this context, leading to increased hallucinations and reduced utility in telecom operations.To address these limitations, this work introduces KG-RAG-a novel framework that integrates knowledge graphs (KGs) with retrieval-augmented generation (RAG) to enhance LLMs for telecom-specific tasks. In particular, the KG provides a structured representation of domain knowledge derived from telecom standards and technical documents, while RAG enables dynamic retrieval of relevant facts to ground the model's outputs. Such a combination improves factual accuracy, reduces hallucination, and ensures compliance with telecom specifications.Experimental results across benchmark datasets demonstrate that KG-RAG outperforms both LLM-only and standard RAG baselines, e.g., KG-RAG achieves an average accuracy improvement of 14.3% over RAG and 21.6% over LLM-only models. These results highlight KG-RAG's effectiveness in producing accurate, reliable, and explainable outputs in complex telecom scenarios.
Randomization Boosts KV Caching, Learning Balances Query Load: A Joint Perspective
Jan 26, 2026KV caching is a fundamental technique for accelerating Large Language Model (LLM) inference by reusing key-value (KV) pairs from previous queries, but its effectiveness under limited memory is highly sensitive to the eviction policy. The default Least Recently Used (LRU) eviction algorithm struggles with dynamic online query arrivals, especially in multi-LLM serving scenarios, where balancing query load across workers and maximizing cache hit rate of each worker are inherently conflicting objectives. We give the first unified mathematical model that captures the core trade-offs between KV cache eviction and query routing. Our analysis reveals the theoretical limitations of existing methods and leads to principled algorithms that integrate provably competitive randomized KV cache eviction with learning-based methods to adaptively route queries with evolving patterns, thus balancing query load and cache hit rate. Our theoretical results are validated by extensive experiments across 4 benchmarks and 3 prefix-sharing settings, demonstrating improvements of up to 6.92$\times$ in cache hit rate, 11.96$\times$ reduction in latency, 14.06$\times$ reduction in time-to-first-token (TTFT), and 77.4% increase in throughput over the state-of-the-art methods. Our code is available at https://github.com/fzwark/KVRouting.
Exploring Protein Language Model Architecture-Induced Biases for Antibody Comprehension
Dec 10, 2025



Recent advances in protein language models (PLMs) have demonstrated remarkable capabilities in understanding protein sequences. However, the extent to which different model architectures capture antibody-specific biological properties remains unexplored. In this work, we systematically investigate how architectural choices in PLMs influence their ability to comprehend antibody sequence characteristics and functions. We evaluate three state-of-the-art PLMs-AntiBERTa, BioBERT, and ESM2--against a general-purpose language model (GPT-2) baseline on antibody target specificity prediction tasks. Our results demonstrate that while all PLMs achieve high classification accuracy, they exhibit distinct biases in capturing biological features such as V gene usage, somatic hypermutation patterns, and isotype information. Through attention attribution analysis, we show that antibody-specific models like AntiBERTa naturally learn to focus on complementarity-determining regions (CDRs), while general protein models benefit significantly from explicit CDR-focused training strategies. These findings provide insights into the relationship between model architecture and biological feature extraction, offering valuable guidance for future PLM development in computational antibody design.
When to Think and When to Look: Uncertainty-Guided Lookback
Nov 19, 2025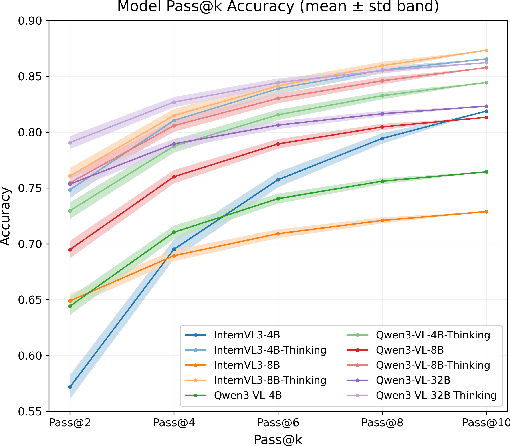

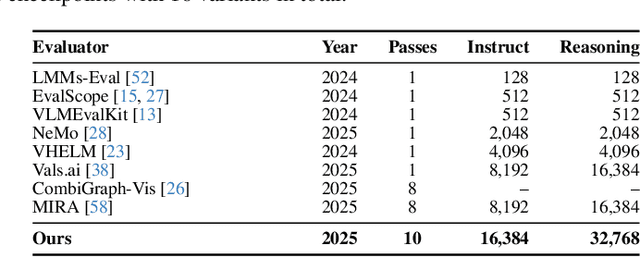
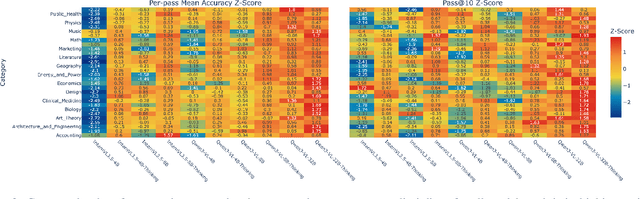
Test-time thinking (that is, generating explicit intermediate reasoning chains) is known to boost performance in large language models and has recently shown strong gains for large vision language models (LVLMs). However, despite these promising results, there is still no systematic analysis of how thinking actually affects visual reasoning. We provide the first such analysis with a large scale, controlled comparison of thinking for LVLMs, evaluating ten variants from the InternVL3.5 and Qwen3-VL families on MMMU-val under generous token budgets and multi pass decoding. We show that more thinking is not always better; long chains often yield long wrong trajectories that ignore the image and underperform the same models run in standard instruct mode. A deeper analysis reveals that certain short lookback phrases, which explicitly refer back to the image, are strongly enriched in successful trajectories and correlate with better visual grounding. Building on this insight, we propose uncertainty guided lookback, a training free decoding strategy that combines an uncertainty signal with adaptive lookback prompts and breadth search. Our method improves overall MMMU performance, delivers the largest gains in categories where standard thinking is weak, and outperforms several strong decoding baselines, setting a new state of the art under fixed model families and token budgets. We further show that this decoding strategy generalizes, yielding consistent improvements on five additional benchmarks, including two broad multimodal suites and math focused visual reasoning datasets.
Step-Audio-EditX Technical Report
Nov 05, 2025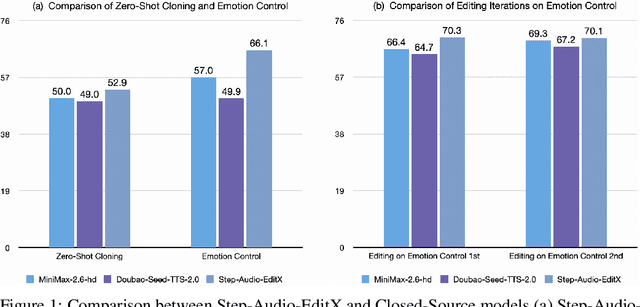
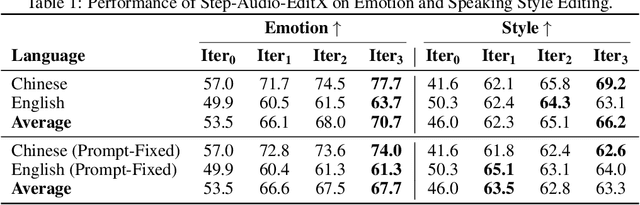

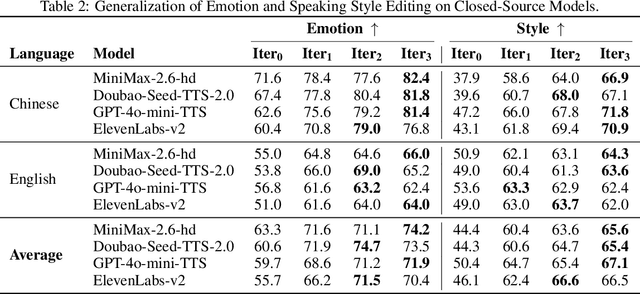
We present Step-Audio-EditX, the first open-source LLM-based audio model excelling at expressive and iterative audio editing encompassing emotion, speaking style, and paralinguistics alongside robust zero-shot text-to-speech (TTS) capabilities.Our core innovation lies in leveraging only large-margin synthetic data, which circumvents the need for embedding-based priors or auxiliary modules. This large-margin learning approach enables both iterative control and high expressivity across voices, and represents a fundamental pivot from the conventional focus on representation-level disentanglement. Evaluation results demonstrate that Step-Audio-EditX surpasses both MiniMax-2.6-hd and Doubao-Seed-TTS-2.0 in emotion editing and other fine-grained control tasks.
Mind-Paced Speaking: A Dual-Brain Approach to Real-Time Reasoning in Spoken Language Models
Oct 10, 2025Real-time Spoken Language Models (SLMs) struggle to leverage Chain-of-Thought (CoT) reasoning due to the prohibitive latency of generating the entire thought process sequentially. Enabling SLMs to think while speaking, similar to humans, is attracting increasing attention. We present, for the first time, Mind-Paced Speaking (MPS), a brain-inspired framework that enables high-fidelity, real-time reasoning. Similar to how humans utilize distinct brain regions for thinking and responding, we propose a novel dual-brain approach, employing a "Formulation Brain" for high-level reasoning to pace and guide a separate "Articulation Brain" for fluent speech generation. This division of labor eliminates mode-switching, preserving the integrity of the reasoning process. Experiments show that MPS significantly outperforms existing think-while-speaking methods and achieves reasoning performance comparable to models that pre-compute the full CoT before speaking, while drastically reducing latency. Under a zero-latency configuration, the proposed method achieves an accuracy of 92.8% on the mathematical reasoning task Spoken-MQA and attains a score of 82.5 on the speech conversation task URO-Bench. Our work effectively bridges the gap between high-quality reasoning and real-time interaction.
MoE-CE: Enhancing Generalization for Deep Learning based Channel Estimation via a Mixture-of-Experts Framework
Sep 19, 2025Reliable channel estimation (CE) is fundamental for robust communication in dynamic wireless environments, where models must generalize across varying conditions such as signal-to-noise ratios (SNRs), the number of resource blocks (RBs), and channel profiles. Traditional deep learning (DL)-based methods struggle to generalize effectively across such diverse settings, particularly under multitask and zero-shot scenarios. In this work, we propose MoE-CE, a flexible mixture-of-experts (MoE) framework designed to enhance the generalization capability of DL-based CE methods. MoE-CE provides an appropriate inductive bias by leveraging multiple expert subnetworks, each specialized in distinct channel characteristics, and a learned router that dynamically selects the most relevant experts per input. This architecture enhances model capacity and adaptability without a proportional rise in computational cost while being agnostic to the choice of the backbone model and the learning algorithm. Through extensive experiments on synthetic datasets generated under diverse SNRs, RB numbers, and channel profiles, including multitask and zero-shot evaluations, we demonstrate that MoE-CE consistently outperforms conventional DL approaches, achieving significant performance gains while maintaining efficiency.