 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-CE: Enhancing Generalization for Deep Learning based Channel Estimation via a Mixture-of-Experts Framework
Sep 19, 2025Reliable channel estimation (CE) is fundamental for robust communication in dynamic wireless environments, where models must generalize across varying conditions such as signal-to-noise ratios (SNRs), the number of resource blocks (RBs), and channel profiles. Traditional deep learning (DL)-based methods struggle to generalize effectively across such diverse settings, particularly under multitask and zero-shot scenarios. In this work, we propose MoE-CE, a flexible mixture-of-experts (MoE) framework designed to enhance the generalization capability of DL-based CE methods. MoE-CE provides an appropriate inductive bias by leveraging multiple expert subnetworks, each specialized in distinct channel characteristics, and a learned router that dynamically selects the most relevant experts per input. This architecture enhances model capacity and adaptability without a proportional rise in computational cost while being agnostic to the choice of the backbone model and the learning algorithm. Through extensive experiments on synthetic datasets generated under diverse SNRs, RB numbers, and channel profiles, including multitask and zero-shot evaluations, we demonstrate that MoE-CE consistently outperforms conventional DL approaches, achieving significant performance gains while maintaining efficiency.
Understanding 6G through Language Models: A Case Study on LLM-aided Structured Entity Extraction in Telecom Domain
May 20, 2025Knowledge understanding is a foundational part of envisioned 6G networks to advance network intelligence and AI-native network architectures. In this paradigm, information extraction plays a pivotal role in transforming fragmented telecom knowledge into well-structured formats, empowering diverse AI models to better understand network terminologies. This work proposes a novel language model-based information extraction technique, aiming to extract structured entities from the telecom context. The proposed telecom structured entity extraction (TeleSEE) technique applies a token-efficient representation method to predict entity types and attribute keys, aiming to save the number of output tokens and improve prediction accuracy. Meanwhile, TeleSEE involves a hierarchical parallel decoding method, improving the standard encoder-decoder architecture by integrating additional prompting and decoding strategies into entity extraction tasks. In addition, to better evaluate the performance of the proposed technique in the telecom domain, we further designed a dataset named 6GTech, including 2390 sentences and 23747 words from more than 100 6G-related technical publications. Finally, the experiment shows that the proposed TeleSEE method achieves higher accuracy than other baseline techniques, and also presents 5 to 9 times higher sample processing speed.
Enhancing Large Language Models (LLMs) for Telecommunications using Knowledge Graphs and Retrieval-Augmented Generation
Mar 31, 2025Large language models (LLMs) have made significant progress in general-purpose natural language processing tasks. However, LLMs are still facing challenges when applied to domain-specific areas like telecommunications, which demands specialized expertise and adaptability to evolving standards. This paper presents a novel framework that combines knowledge graph (KG) and retrieval-augmented generation (RAG) techniques to enhance LLM performance in the telecom domain. The framework leverages a KG to capture structured, domain-specific information about network protocols, standards, and other telecom-related entities, comprehensively representing their relationships. By integrating KG with RAG, LLMs can dynamically access and utilize the most relevant and up-to-date knowledge during response generation. This hybrid approach bridges the gap between structured knowledge representation and the generative capabilities of LLMs, significantly enhancing accuracy, adaptability, and domain-specific comprehension. Our results demonstrate the effectiveness of the KG-RAG framework in addressing complex technical queries with precision. The proposed KG-RAG model attained an accuracy of 88% for question answering tasks on a frequently used telecom-specific dataset, compared to 82% for the RAG-only and 48% for the LLM-only approaches.
Plug-in UL-CSI-Assisted Precoder Upsampling Approach in Cellular FDD Systems
May 31, 2024Acquiring downlink channel state information (CSI) is crucial for optimizing performance in massive Multiple Input Multiple Output (MIMO) systems operating under Frequency-Division Duplexing (FDD). Most cellular wireless communication systems employ codebook-based precoder designs, which offer advantages such as simpler, more efficient feedback mechanisms and reduced feedback overhead. Common codebook-based approaches include Type II and eType II precoding methods defined in the 3GPP standards. Feedback in these systems is typically standardized per subband (SB), allowing user equipment (UE) to select the optimal precoder from the codebook for each SB, thereby reducing feedback overhead. However, this subband-level feedback resolution may not suffice for frequency-selective channels. This paper addresses this issue by introducing an uplink CSI-assisted precoder upsampling module deployed at the gNodeB. This module upsamples SB-level precoders to resource block (RB)-level precoders, acting as a plug-in compatible with existing gNodeB or base stations.
Physics-Inspired Deep Learning Anti-Aliasing Framework in Efficient Channel State Feedback
Mar 12, 2024Acquiring downlink channel state information (CSI) at the base station is vital for optimizing performance in massive Multiple input multiple output (MIMO) Frequency-Division Duplexing (FDD) systems. While deep learning architectures have been successful in facilitating UE-side CSI feedback and gNB-side recovery, the undersampling issue prior to CSI feedback is often overlooked. This issue, which arises from low density pilot placement in current standards, results in significant aliasing effects in outdoor channels and consequently limits CSI recovery performance. To this end, this work introduces a new CSI upsampling framework at the gNB as a post-processing solution to address the gaps caused by undersampling. Leveraging the physical principles of discrete Fourier transform shifting theorem and multipath reciprocity, our framework effectively uses uplink CSI to mitigate aliasing effects. We further develop a learning-based method that integrates the proposed algorithm with the Iterative Shrinkage-Thresholding Algorithm Net (ISTA-Net) architecture, enhancing our approach for non-uniform sampling recovery. Our numerical results show that both our rule-based and deep learning methods significantly outperform traditional interpolation techniques and current state-of-the-art approaches in terms of performance.
An Overview on IEEE 802.11bf: WLAN Sensing
Oct 20, 2023With recent advancements, the wireless local area network (WLAN) or wireless fidelity (Wi-Fi) technology has been successfully utilized to realize sensing functionalities such as detection, localization, and recognition. However, the WLANs standards are developed mainly for the purpose of communication, and thus may not be able to meet the stringent requirements for emerging sensing applications. To resolve this issue, a new Task Group (TG), namely IEEE 802.11bf, has been established by the IEEE 802.11 working group, with the objective of creating a new amendment to the WLAN standard to meet advanced sensing requirements while minimizing the effect on communications. This paper provides a comprehensive overview on the up-to-date efforts in the IEEE 802.11bf TG. First, we introduce the definition of the 802.11bf amendment and its formation and standardization timeline. Next, we discuss the WLAN sensing use cases with the corresponding key performance indicator (KPI) requirements. After reviewing previous WLAN sensing research based on communication-oriented WLAN standards, we identify their limitations and underscore the practical need for the new sensing-oriented amendment in 802.11bf. Furthermore, we discuss the WLAN sensing framework and procedure used for measurement acquisition, by considering both sensing at sub-7GHz and directional multi-gigabit (DMG) sensing at 60 GHz, respectively, and address their shared features, similarities, and differences. In addition, we present various candidate technical features for IEEE 802.11bf, including waveform/sequence design, feedback types, as well as quantization and compression techniques. We also describe the methodologies and the channel modeling used by the IEEE 802.11bf TG for evaluation. Finally, we discuss the challenges and future research directions to motivate more research endeavors towards this field in details.
Pareto Deterministic Policy Gradients and Its Application in 5G Massive MIMO Networks
Dec 02, 2020

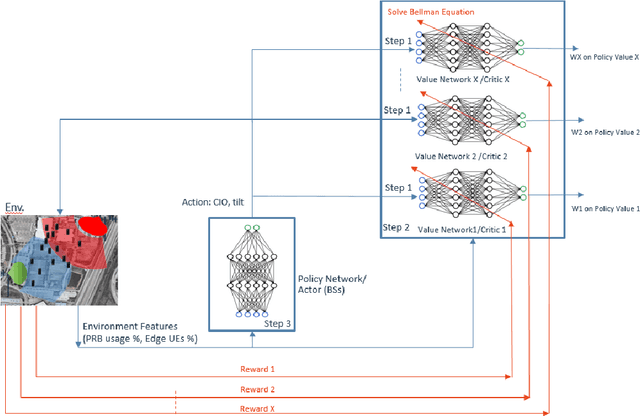
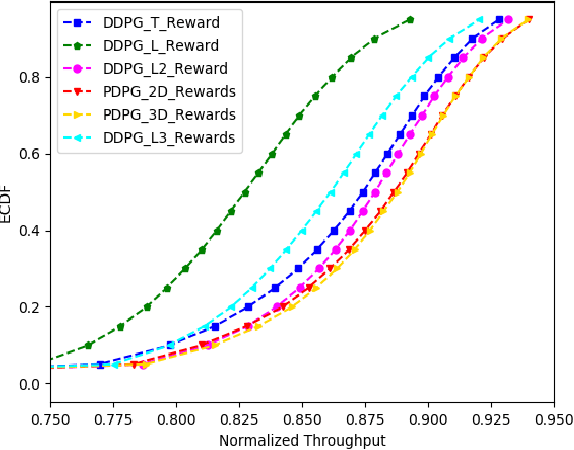
In this paper, we consider jointly optimizing cell load balance and network throughput via a reinforcement learning (RL) approach, where inter-cell handover (i.e., user association assignment) and massive MIMO antenna tilting are configured as the RL policy to learn. Our rationale behind using RL is to circumvent the challenges of analytically modeling user mobility and network dynamics. To accomplish this joint optimization, we integrate vector rewards into the RL value network and conduct RL action via a separate policy network. We name this method as Pareto deterministic policy gradients (PDPG). It is an actor-critic, model-free and deterministic policy algorithm which can handle the coupling objectives with the following two merits: 1) It solves the optimization via leveraging the degree of freedom of vector reward as opposed to choosing handcrafted scalar-reward; 2) Cross-validation over multiple policies can be significantly reduced. Accordingly, the RL enabled network behaves in a self-organized way: It learns out the underlying user mobility through measurement history to proactively operate handover and antenna tilt without environment assumptions. Our numerical evaluation demonstrates that the introduced RL method outperforms scalar-reward based approaches. Meanwhile, to be self-contained, an ideal static optimization based brute-force search solver is included as a benchmark. The comparison shows that the RL approach performs as well as this ideal strategy, though the former one is constrained with limited environment observations and lower action frequency, whereas the latter ones have full access to the user mobility. The convergence of our introduced approach is also tested under different user mobility environment based on our measurement data from a real scenario.