 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Language Agent Algorithms with Graph-based Orchestration Engine for Reproducible Agent Research
May 30, 2025


Language agents powered by large language models (LLMs) have demonstrated remarkable capabilities in understanding, reasoning, and executing complex tasks. However, developing robust agents presents significant challenges: substantial engineering overhead, lack of standardized components, and insufficient evaluation frameworks for fair comparison. We introduce Agent Graph-based Orchestration for Reasoning and Assessment (AGORA), a flexible and extensible framework that addresses these challenges through three key contributions: (1) a modular architecture with a graph-based workflow engine, efficient memory management, and clean component abstraction; (2) a comprehensive suite of reusable agent algorithms implementing state-of-the-art reasoning approaches; and (3) a rigorous evaluation framework enabling systematic comparison across multiple dimensions. Through extensive experiments on mathematical reasoning and multimodal tasks, we evaluate various agent algorithms across different LLMs, revealing important insights about their relative strengths and applicability. Our results demonstrate that while sophisticated reasoning approaches can enhance agent capabilities, simpler methods like Chain-of-Thought often exhibit robust performance with significantly lower computational overhead. AGORA not only simplifies language agent development but also establishes a foundation for reproducible agent research through standardized evaluation protocols.
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Apr 10, 2025
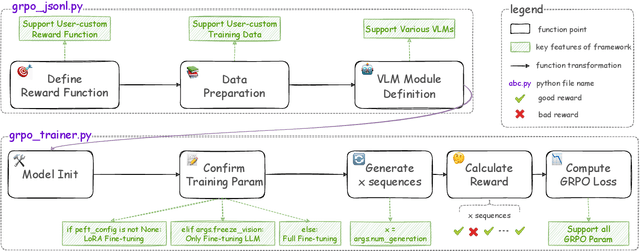
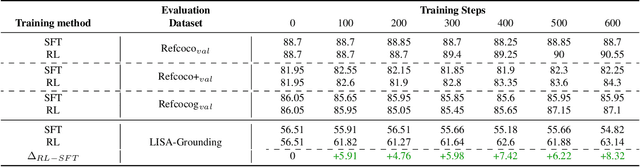
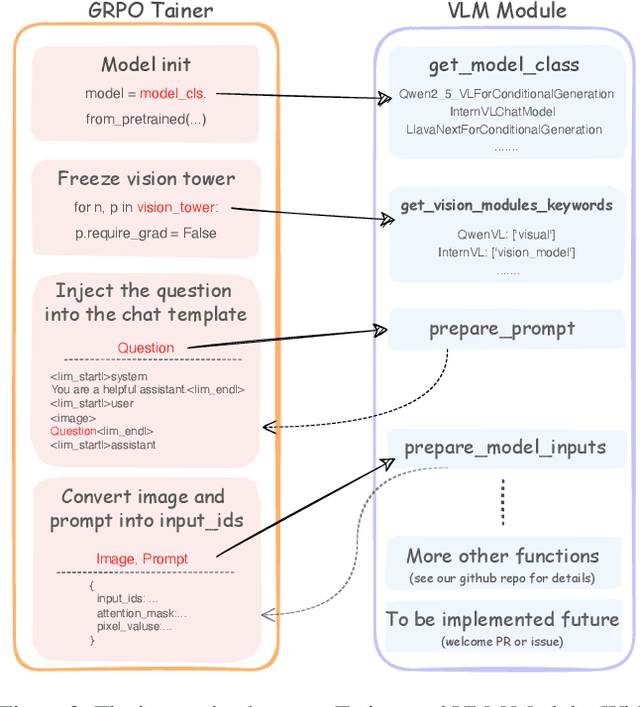
Recently DeepSeek R1 has shown that reinforcement learning (RL) can substantially improve the reasoning capabilities of Large Language Models (LLMs) through a simple yet effective design. The core of R1 lies in its rule-based reward formulation, which leverages tasks with deterministic ground-truth answers to enable precise and stable reward computation. In the visual domain, we similarly observe that a wide range of visual understanding tasks are inherently equipped with well-defined ground-truth annotations. This property makes them naturally compatible with rule-based reward mechanisms. Motivated by this observation, we investigate the extension of R1-style reinforcement learning to Vision-Language Models (VLMs), aiming to enhance their visual reasoning capabilities. To this end, we develop VLM-R1, a dedicated framework designed to harness RL for improving VLMs' performance on general vision-language tasks. Using this framework, we further explore the feasibility of applying RL to visual domain. Experimental results indicate that the RL-based model not only delivers competitive performance on visual understanding tasks but also surpasses Supervised Fine-Tuning (SFT) in generalization ability. Furthermore, we conduct comprehensive ablation studies that uncover a series of noteworthy insights, including the presence of reward hacking in object detection, the emergence of the "OD aha moment", the impact of training data quality, and the scaling behavior of RL across different model sizes. Through these analyses, we aim to deepen the understanding of how reinforcement learning enhances the capabilities of vision-language models, and we hope our findings and open-source contributions will support continued progress in the vision-language RL community. Our code and model are available at https://github.com/om-ai-lab/VLM-R1
OmChat: A Recipe to Train Multimodal Language Models with Strong Long Context and Video Understanding
Jul 06, 2024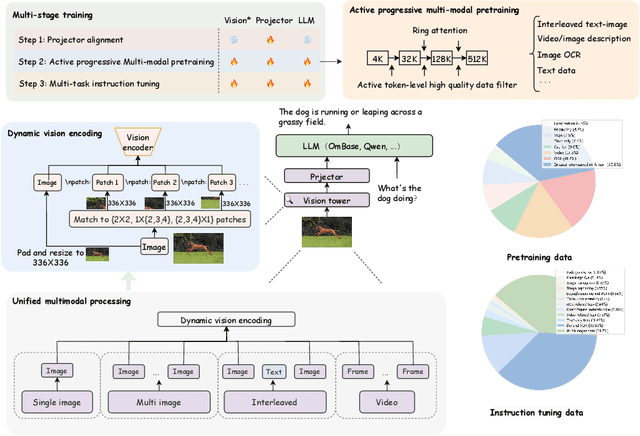
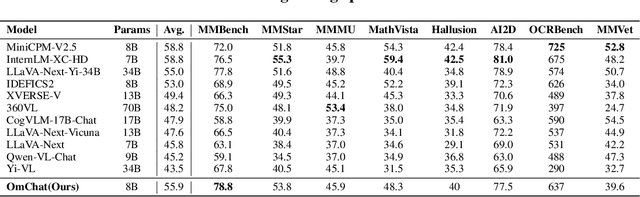
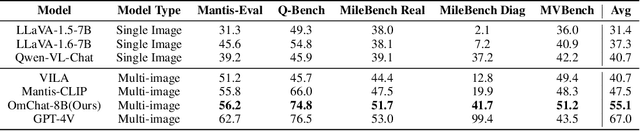
We introduce OmChat, a model designed to excel in handling long contexts and video understanding tasks. OmChat's new architecture standardizes how different visual inputs are processed, making it more efficient and adaptable. It uses a dynamic vision encoding process to effectively handle images of various resolutions, capturing fine details across a range of image qualities. OmChat utilizes an active progressive multimodal pretraining strategy, which gradually increases the model's capacity for long contexts and enhances its overall abilities. By selecting high-quality data during training, OmChat learns from the most relevant and informative data points. With support for a context length of up to 512K, OmChat demonstrates promising performance in tasks involving multiple images and videos, outperforming most open-source models in these benchmarks. Additionally, OmChat proposes a prompting strategy for unifying complex multimodal inputs including single image text, multi-image text and videos, and achieving competitive performance on single-image benchmarks. To further evaluate the model's capabilities, we proposed a benchmark dataset named Temporal Visual Needle in a Haystack. This dataset assesses OmChat's ability to comprehend temporal visual details within long videos. Our analysis highlights several key factors contributing to OmChat's success: support for any-aspect high image resolution, the active progressive pretraining strategy, and high-quality supervised fine-tuning datasets. This report provides a detailed overview of OmChat's capabilities and the strategies that enhance its performance in visual understanding.
OmAgent: A Multi-modal Agent Framework for Complex Video Understanding with Task Divide-and-Conquer
Jun 25, 2024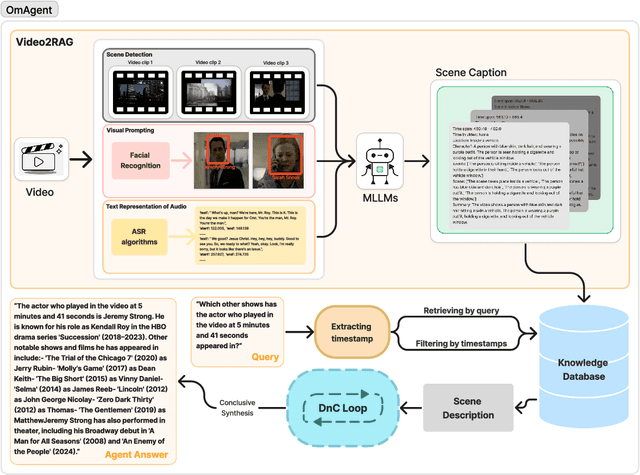
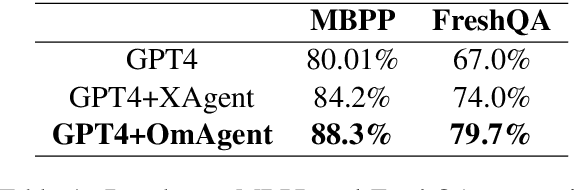
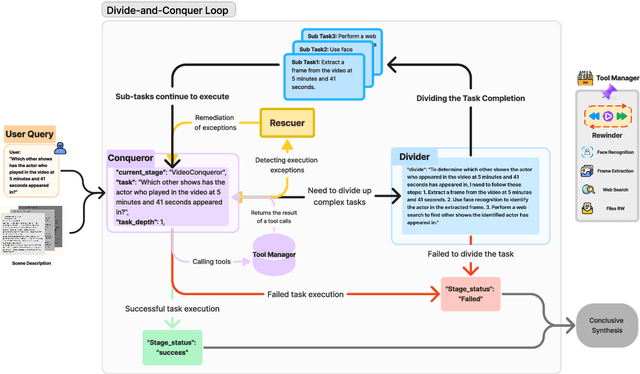

Recent advancements in Large Language Models (LLMs) have expanded their capabilities to multimodal contexts, including comprehensive video understanding. However, processing extensive videos such as 24-hour CCTV footage or full-length films presents significant challenges due to the vast data and processing demands. Traditional methods, like extracting key frames or converting frames to text, often result in substantial information loss. To address these shortcomings, we develop OmAgent, efficiently stores and retrieves relevant video frames for specific queries, preserving the detailed content of videos. Additionally, it features an Divide-and-Conquer Loop capable of autonomous reasoning, dynamically invoking APIs and tools to enhance query processing and accuracy. This approach ensures robust video understanding, significantly reducing information loss. Experimental results affirm OmAgent's efficacy in handling various types of videos and complex tasks. Moreover, we have endowed it with greater autonomy and a robust tool-calling system, enabling it to accomplish even more intricate tasks.
Plug-in UL-CSI-Assisted Precoder Upsampling Approach in Cellular FDD Systems
May 31, 2024Acquiring downlink channel state information (CSI) is crucial for optimizing performance in massive Multiple Input Multiple Output (MIMO) systems operating under Frequency-Division Duplexing (FDD). Most cellular wireless communication systems employ codebook-based precoder designs, which offer advantages such as simpler, more efficient feedback mechanisms and reduced feedback overhead. Common codebook-based approaches include Type II and eType II precoding methods defined in the 3GPP standards. Feedback in these systems is typically standardized per subband (SB), allowing user equipment (UE) to select the optimal precoder from the codebook for each SB, thereby reducing feedback overhead. However, this subband-level feedback resolution may not suffice for frequency-selective channels. This paper addresses this issue by introducing an uplink CSI-assisted precoder upsampling module deployed at the gNodeB. This module upsamples SB-level precoders to resource block (RB)-level precoders, acting as a plug-in compatible with existing gNodeB or base stations.