 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Language Agent Algorithms with Graph-based Orchestration Engine for Reproducible Agent Research
May 30, 2025


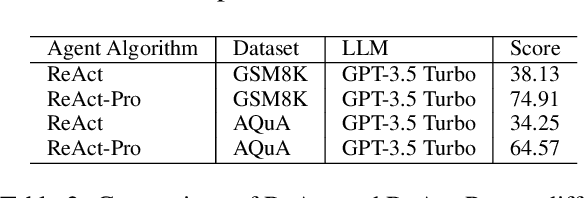
Language agents powered by large language models (LLMs) have demonstrated remarkable capabilities in understanding, reasoning, and executing complex tasks. However, developing robust agents presents significant challenges: substantial engineering overhead, lack of standardized components, and insufficient evaluation frameworks for fair comparison. We introduce Agent Graph-based Orchestration for Reasoning and Assessment (AGORA), a flexible and extensible framework that addresses these challenges through three key contributions: (1) a modular architecture with a graph-based workflow engine, efficient memory management, and clean component abstraction; (2) a comprehensive suite of reusable agent algorithms implementing state-of-the-art reasoning approaches; and (3) a rigorous evaluation framework enabling systematic comparison across multiple dimensions. Through extensive experiments on mathematical reasoning and multimodal tasks, we evaluate various agent algorithms across different LLMs, revealing important insights about their relative strengths and applicability. Our results demonstrate that while sophisticated reasoning approaches can enhance agent capabilities, simpler methods like Chain-of-Thought often exhibit robust performance with significantly lower computational overhead. AGORA not only simplifies language agent development but also establishes a foundation for reproducible agent research through standardized evaluation protocols.
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Apr 10, 2025
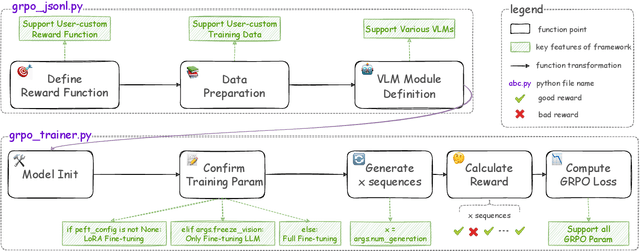
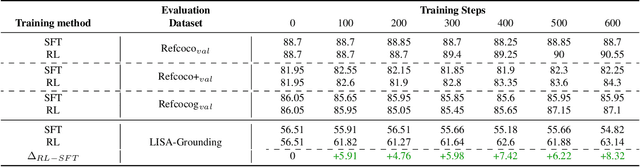
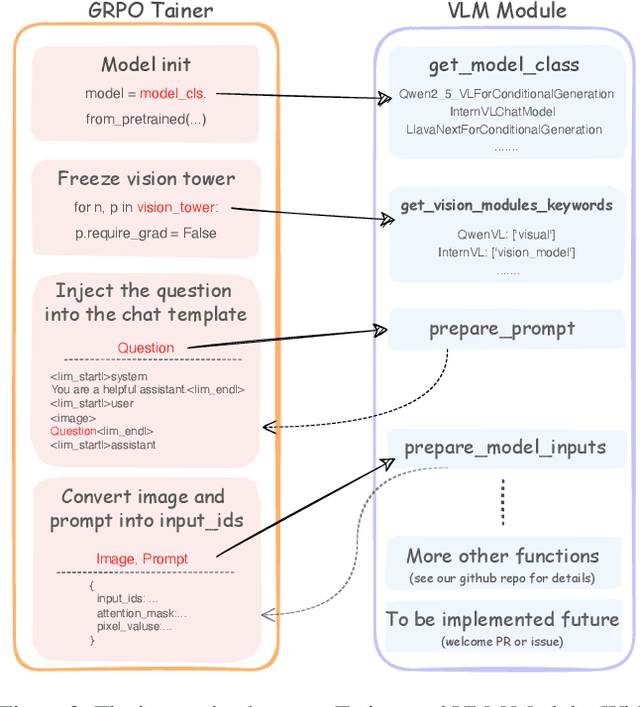
Recently DeepSeek R1 has shown that reinforcement learning (RL) can substantially improve the reasoning capabilities of Large Language Models (LLMs) through a simple yet effective design. The core of R1 lies in its rule-based reward formulation, which leverages tasks with deterministic ground-truth answers to enable precise and stable reward computation. In the visual domain, we similarly observe that a wide range of visual understanding tasks are inherently equipped with well-defined ground-truth annotations. This property makes them naturally compatible with rule-based reward mechanisms. Motivated by this observation, we investigate the extension of R1-style reinforcement learning to Vision-Language Models (VLMs), aiming to enhance their visual reasoning capabilities. To this end, we develop VLM-R1, a dedicated framework designed to harness RL for improving VLMs' performance on general vision-language tasks. Using this framework, we further explore the feasibility of applying RL to visual domain. Experimental results indicate that the RL-based model not only delivers competitive performance on visual understanding tasks but also surpasses Supervised Fine-Tuning (SFT) in generalization ability. Furthermore, we conduct comprehensive ablation studies that uncover a series of noteworthy insights, including the presence of reward hacking in object detection, the emergence of the "OD aha moment", the impact of training data quality, and the scaling behavior of RL across different model sizes. Through these analyses, we aim to deepen the understanding of how reinforcement learning enhances the capabilities of vision-language models, and we hope our findings and open-source contributions will support continued progress in the vision-language RL community. Our code and model are available at https://github.com/om-ai-lab/VLM-R1
RSEND: Retinex-based Squeeze and Excitation Network with Dark Region Detection for Efficient Low Light Image Enhancement
Jun 14, 2024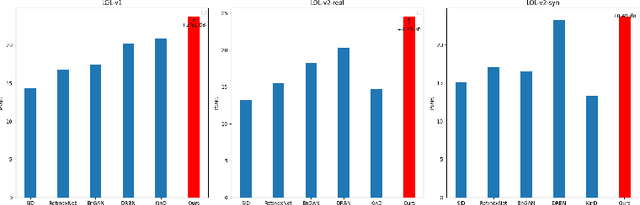
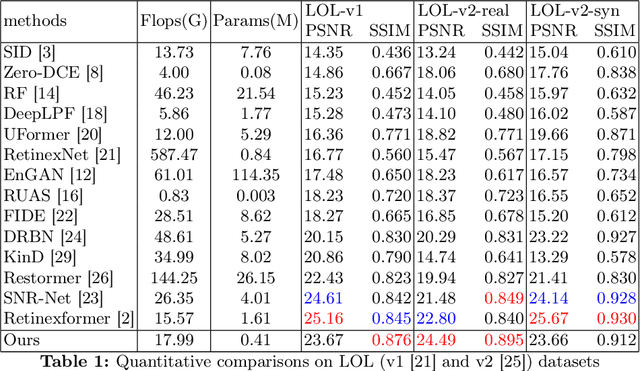
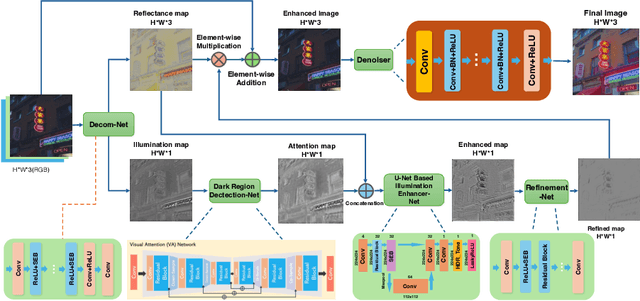

Images captured under low-light scenarios often suffer from low quality. Previous CNN-based deep learning methods often involve using Retinex theory. Nevertheless, most of them cannot perform well in more complicated datasets like LOL-v2 while consuming too much computational resources. Besides, some of these methods require sophisticated training at different stages, making the procedure even more time-consuming and tedious. In this paper, we propose a more accurate, concise, and one-stage Retinex theory based framework, RSEND. RSEND first divides the low-light image into the illumination map and reflectance map, then captures the important details in the illumination map and performs light enhancement. After this step, it refines the enhanced gray-scale image and does element-wise matrix multiplication with the reflectance map. By denoising the output it has from the previous step, it obtains the final result. In all the steps, RSEND utilizes Squeeze and Excitation network to better capture the details. Comprehensive quantitative and qualitative experiments show that our Efficient Retinex model significantly outperforms other CNN-based models, achieving a PSNR improvement ranging from 0.44 dB to 4.2 dB in different datasets and even outperforms transformer-based models in the LOL-v2-real dataset.
Unbiased organism-agnostic and highly sensitive signal peptide predictor with deep protein language model
Dec 14, 2023Signal peptide (SP) is a short peptide located in the N-terminus of proteins. It is essential to target and transfer transmembrane and secreted proteins to correct positions. Compared with traditional experimental methods to identify signal peptides, computational methods are faster and more efficient, which are more practical for analyzing thousands or even millions of protein sequences, especially for metagenomic data. Here we present Unbiased Organism-agnostic Signal Peptide Network (USPNet), a signal peptide classification and cleavage site prediction deep learning method that takes advantage of protein language models. We propose to apply label distribution-aware margin loss to handle data imbalance problems and use evolutionary information of protein to enrich representation and overcome species information dependence.
SecBeam: Securing mmWave Beam Alignment against Beam-Stealing Attacks
Jul 01, 2023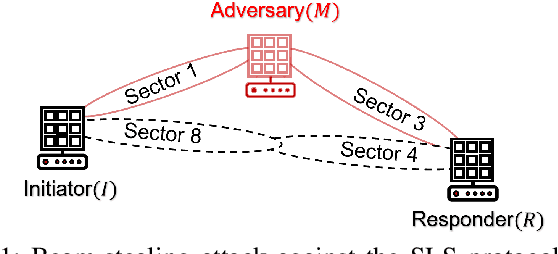
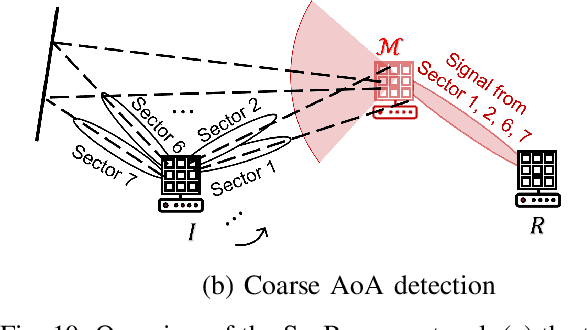
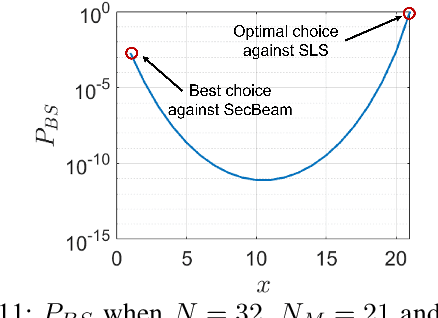
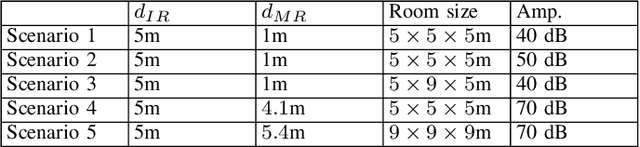
Millimeter wave (mmWave) communications employ narrow-beam directional communications to compensate for the high path loss at mmWave frequencies. Compared to their omnidirectional counterparts, an additional step of aligning the transmitter's and receiver's antennas is required. In current standards such as 802.11ad, this beam alignment process is implemented via an exhaustive search through the horizontal plane known as beam sweeping. However, the beam sweeping process is unauthenticated. As a result, an adversary, Mallory, can launch an active beam-stealing attack by injecting forged beacons of high power, forcing the legitimate devices to beamform towards her direction. Mallory is now in control of the communication link between the two devices, thus breaking the false sense of security given by the directionality of mmWave transmissions. Prior works have added integrity protection to beam alignment messages to prevent forgeries. In this paper, we demonstrate a new beam-stealing attack that does not require message forging. We show that Mallory can amplify and relay a beam sweeping frame from her direction without altering its contents. Intuitively, cryptographic primitives cannot verify physical properties such as the SNR used in beam selection. We propose a new beam sweeping protocol called SecBeam that utilizes power/sector randomization and coarse angle-of-arrival information to detect amplify-and-relay attacks. We demonstrate the security and performance of SecBeam using an experimental mmWave platform and via ray-tracing simulations.
Secret-Free Device Pairing in the mmWave Band
Jun 29, 2023



Many Next Generation (NextG) applications feature devices that are capable of communicating and sensing in the Millimeter-Wave (mmWave) bands. Trust establishment is an important first step to bootstrap secure mmWave communication links, which is challenging due to the lack of prior secrets and the fact that traditional cryptographic authentication methods cannot bind digital trust with physical properties. Previously, context-based device pairing approaches were proposed to extract shared secrets from common context, using various sensing modalities. However, they suffer from various limitations in practicality and security. In this work, we propose the first secret-free device pairing scheme in the mmWave band that explores the unique physical-layer properties of mmWave communications. Our basic idea is to let Alice and Bob derive common randomness by sampling physical activity in the surrounding environment that disturbs their wireless channel. They construct reliable fingerprints of the activity by extracting event timing information from the channel state. We further propose an uncoordinated path hopping mechanism to resolve the challenges of beam alignment for activity sensing without prior trust. A key novelty of our protocol is that it remains secure against both co-located passive adversaries and active Man-in-the-Middle attacks, which is not possible with existing context-based pairing approaches. We implement our protocol in a 28GHz mmWave testbed, and experimentally evaluate its security in realistic indoor environments. Results show that our protocol can effectively thwart several different types of adversaries.
Distilled Mid-Fusion Transformer Networks for Multi-Modal Human Activity Recognition
May 05, 2023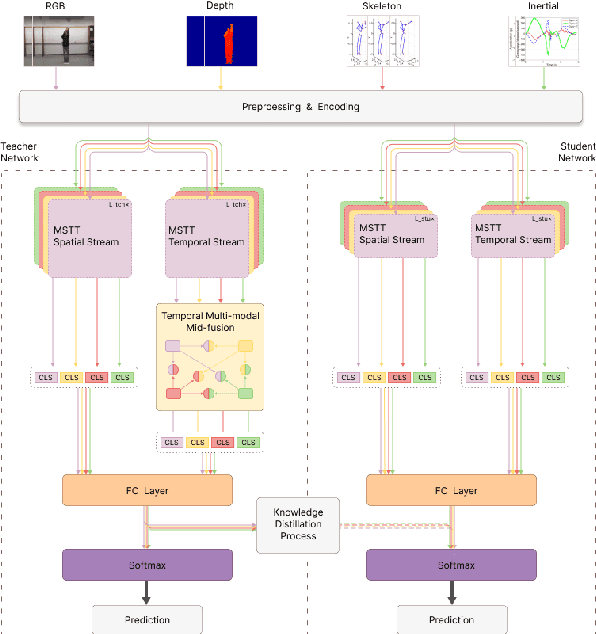

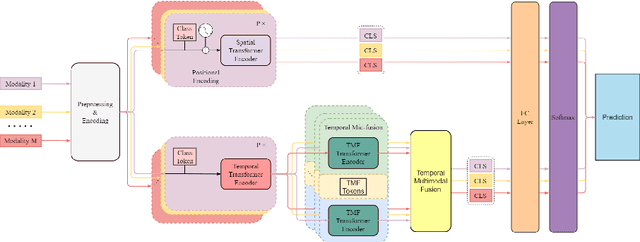
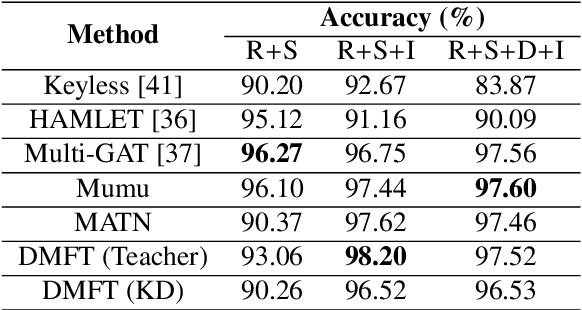
Human Activity Recognition is an important task in many human-computer collaborative scenarios, whilst having various practical applications. Although uni-modal approaches have been extensively studied, they suffer from data quality and require modality-specific feature engineering, thus not being robust and effective enough for real-world deployment. By utilizing various sensors, Multi-modal Human Activity Recognition could utilize the complementary information to build models that can generalize well. While deep learning methods have shown promising results, their potential in extracting salient multi-modal spatial-temporal features and better fusing complementary information has not been fully explored. Also, reducing the complexity of the multi-modal approach for edge deployment is another problem yet to resolve. To resolve the issues, a knowledge distillation-based Multi-modal Mid-Fusion approach, DMFT, is proposed to conduct informative feature extraction and fusion to resolve the Multi-modal Human Activity Recognition task efficiently. DMFT first encodes the multi-modal input data into a unified representation. Then the DMFT teacher model applies an attentive multi-modal spatial-temporal transformer module that extracts the salient spatial-temporal features. A temporal mid-fusion module is also proposed to further fuse the temporal features. Then the knowledge distillation method is applied to transfer the learned representation from the teacher model to a simpler DMFT student model, which consists of a lite version of the multi-modal spatial-temporal transformer module, to produce the results. Evaluation of DMFT was conducted on two public multi-modal human activity recognition datasets with various state-of-the-art approaches. The experimental results demonstrate that the model achieves competitive performance in terms of effectiveness, scalability, and robustness.