 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilled Mid-Fusion Transformer Networks for Multi-Modal Human Activity Recognition
Paper and Code
May 05, 2023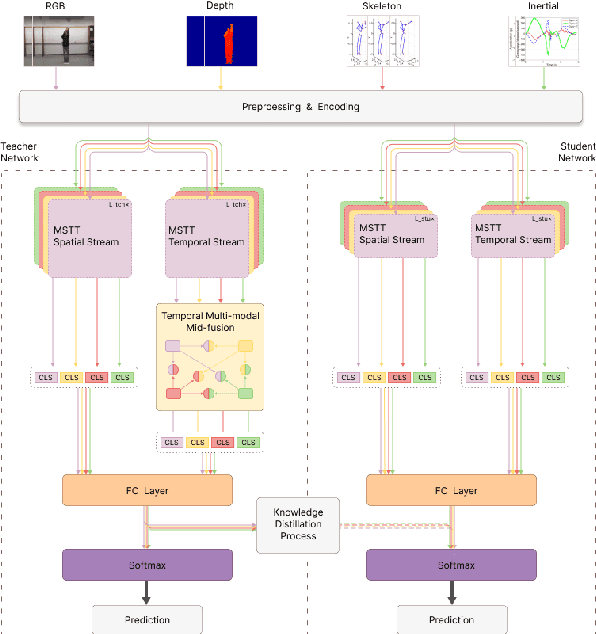

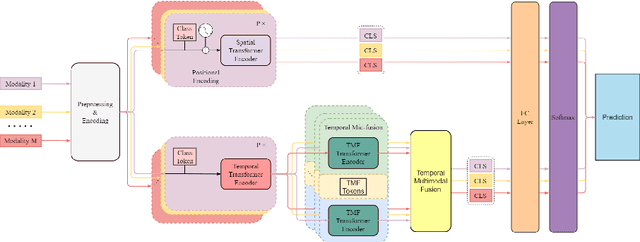
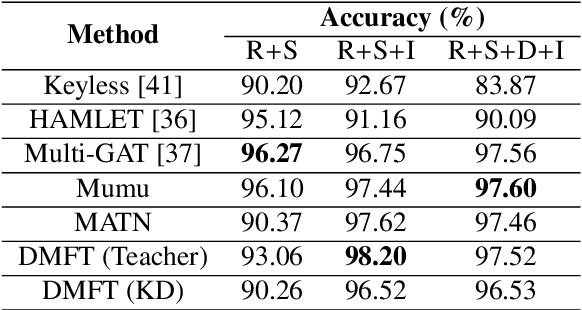
Human Activity Recognition is an important task in many human-computer collaborative scenarios, whilst having various practical applications. Although uni-modal approaches have been extensively studied, they suffer from data quality and require modality-specific feature engineering, thus not being robust and effective enough for real-world deployment. By utilizing various sensors, Multi-modal Human Activity Recognition could utilize the complementary information to build models that can generalize well. While deep learning methods have shown promising results, their potential in extracting salient multi-modal spatial-temporal features and better fusing complementary information has not been fully explored. Also, reducing the complexity of the multi-modal approach for edge deployment is another problem yet to resolve. To resolve the issues, a knowledge distillation-based Multi-modal Mid-Fusion approach, DMFT, is proposed to conduct informative feature extraction and fusion to resolve the Multi-modal Human Activity Recognition task efficiently. DMFT first encodes the multi-modal input data into a unified representation. Then the DMFT teacher model applies an attentive multi-modal spatial-temporal transformer module that extracts the salient spatial-temporal features. A temporal mid-fusion module is also proposed to further fuse the temporal features. Then the knowledge distillation method is applied to transfer the learned representation from the teacher model to a simpler DMFT student model, which consists of a lite version of the multi-modal spatial-temporal transformer module, to produce the results. Evaluation of DMFT was conducted on two public multi-modal human activity recognition datasets with various state-of-the-art approaches. The experimental results demonstrate that the model achieves competitive performance in terms of effectiveness, scalability, and robustness.