 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-aware Social Graph Transformer Networks for Stochastic Trajectory Prediction
Dec 26, 2023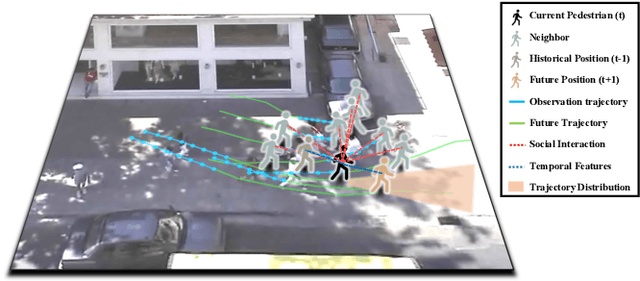
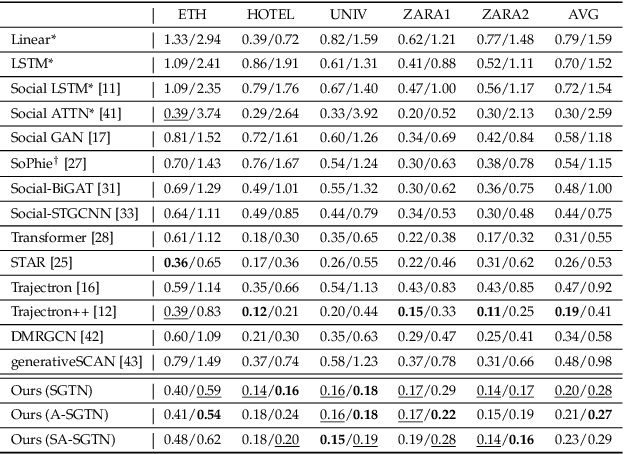
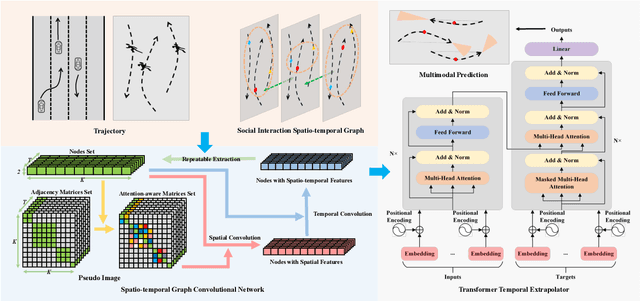
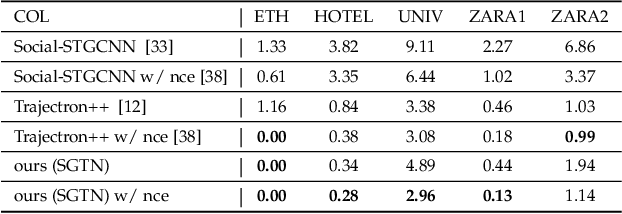
Trajectory prediction is fundamental to various intelligent technologies, such as autonomous driving and robotics. The motion prediction of pedestrians and vehicles helps emergency braking, reduces collisions, and improves traffic safety. Current trajectory prediction research faces problems of complex social interactions, high dynamics and multi-modality. Especially, it still has limitations in long-time prediction. We propose Attention-aware Social Graph Transformer Networks for multi-modal trajectory prediction. We combine Graph Convolutional Networks and Transformer Networks by generating stable resolution pseudo-images from Spatio-temporal graphs through a designed stacking and interception method. Furthermore, we design the attention-aware module to handle social interaction information in scenarios involving mixed pedestrian-vehicle traffic. Thus, we maintain the advantages of the Graph and Transformer, i.e., the ability to aggregate information over an arbitrary number of neighbors and the ability to perform complex time-dependent data processing. We conduct experiments on datasets involving pedestrian, vehicle, and mixed trajectories, respectively. Our results demonstrate that our model minimizes displacement errors across various metrics and significantly reduces the likelihood of collisions. It is worth noting that our model effectively reduces the final displacement error, illustrating the ability of our model to predict for a long time.
Online Learning and Planning in Cognitive Hierarchies
Oct 18, 2023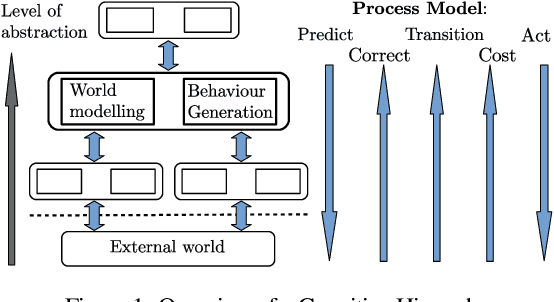
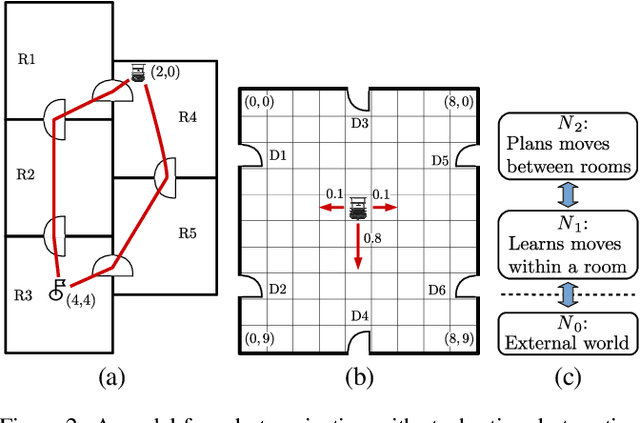
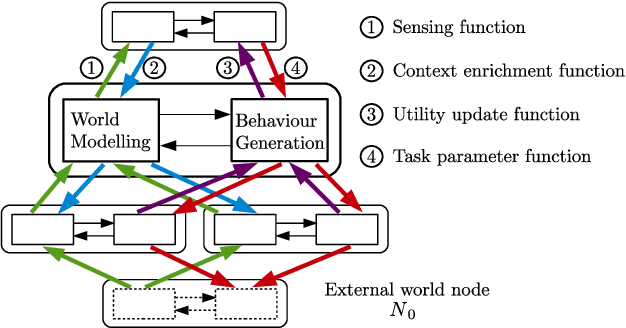
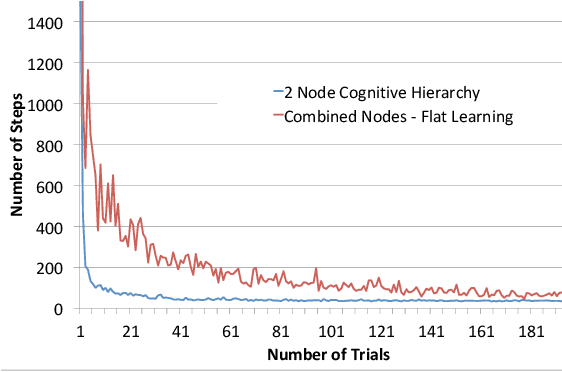
Complex robot behaviour typically requires the integration of multiple robotic and Artificial Intelligence (AI) techniques and components. Integrating such disparate components into a coherent system, while also ensuring global properties and behaviours, is a significant challenge for cognitive robotics. Using a formal framework to model the interactions between components can be an important step in dealing with this challenge. In this paper we extend an existing formal framework [Clark et al., 2016] to model complex integrated reasoning behaviours of robotic systems; from symbolic planning through to online learning of policies and transition systems. Furthermore the new framework allows for a more flexible modelling of the interactions between different reasoning components.
Distilled Mid-Fusion Transformer Networks for Multi-Modal Human Activity Recognition
May 05, 2023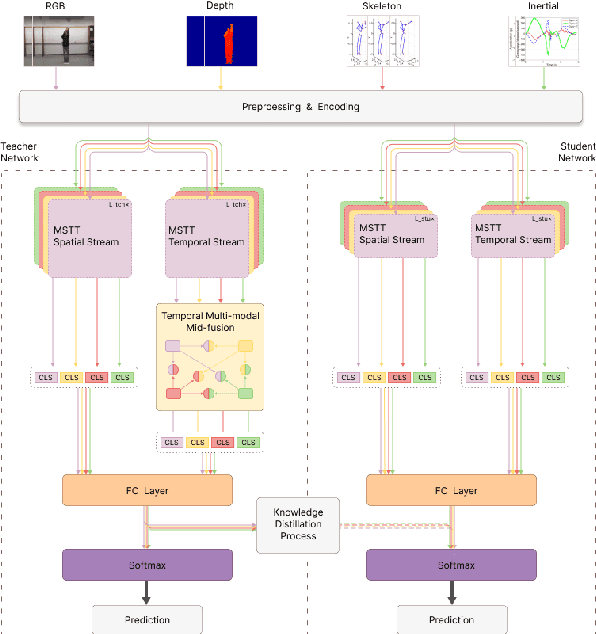

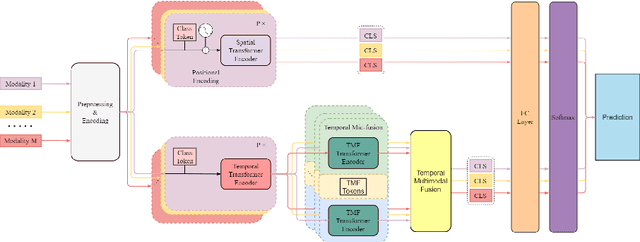
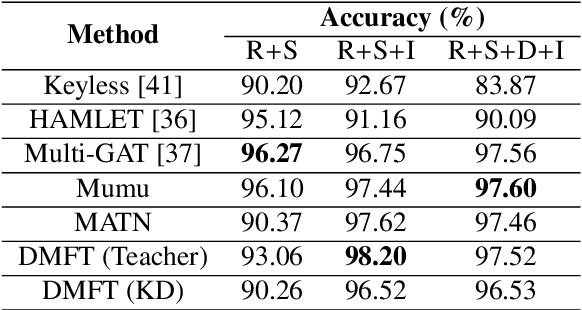
Human Activity Recognition is an important task in many human-computer collaborative scenarios, whilst having various practical applications. Although uni-modal approaches have been extensively studied, they suffer from data quality and require modality-specific feature engineering, thus not being robust and effective enough for real-world deployment. By utilizing various sensors, Multi-modal Human Activity Recognition could utilize the complementary information to build models that can generalize well. While deep learning methods have shown promising results, their potential in extracting salient multi-modal spatial-temporal features and better fusing complementary information has not been fully explored. Also, reducing the complexity of the multi-modal approach for edge deployment is another problem yet to resolve. To resolve the issues, a knowledge distillation-based Multi-modal Mid-Fusion approach, DMFT, is proposed to conduct informative feature extraction and fusion to resolve the Multi-modal Human Activity Recognition task efficiently. DMFT first encodes the multi-modal input data into a unified representation. Then the DMFT teacher model applies an attentive multi-modal spatial-temporal transformer module that extracts the salient spatial-temporal features. A temporal mid-fusion module is also proposed to further fuse the temporal features. Then the knowledge distillation method is applied to transfer the learned representation from the teacher model to a simpler DMFT student model, which consists of a lite version of the multi-modal spatial-temporal transformer module, to produce the results. Evaluation of DMFT was conducted on two public multi-modal human activity recognition datasets with various state-of-the-art approaches. The experimental results demonstrate that the model achieves competitive performance in terms of effectiveness, scalability, and robustness.
D-Flow: A Real Time Spatial Temporal Model for Target Area Segmentation
Nov 08, 2021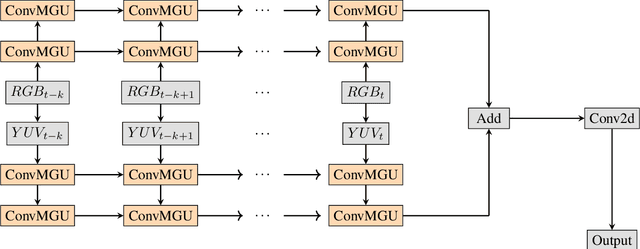
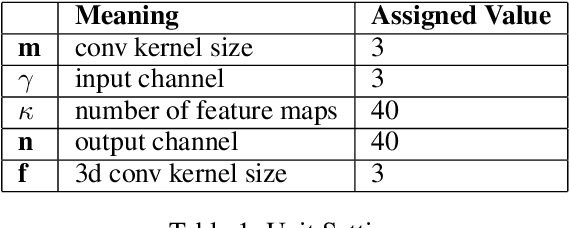
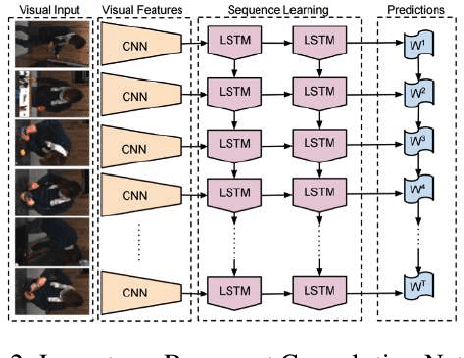
Semantic segmentation has attracted a large amount of attention in recent years. In robotics, segmentation can be used to identify a region of interest, or \emph{target area}. For example, in the RoboCup Standard Platform League (SPL), segmentation separates the soccer field from the background and from players on the field. For satellite or vehicle applications, it is often necessary to find certain regions such as roads, bodies of water or kinds of terrain. In this paper, we propose a novel approach to real-time target area segmentation based on a newly designed spatial temporal network. The method operates under domain constraints defined by both the robot's hardware and its operating environment . The proposed network is able to run in real-time, working within the constraints of limited run time and computing power. This work is compared against other real time segmentation methods on a dataset generated by a Nao V6 humanoid robot simulating the RoboCup SPL competition. In this case, the target area is defined as the artificial grass field. The method is also tested on a maritime dataset collected by a moving vessel, where the aim is to separate the ocean region from the rest of the image. This dataset demonstrates that the proposed model can generalise to a variety of vision problems.
Perceptual Context in Cognitive Hierarchies
Jan 07, 2018
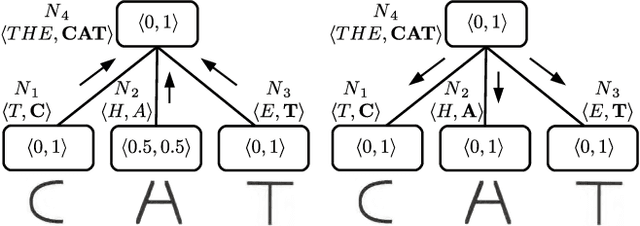
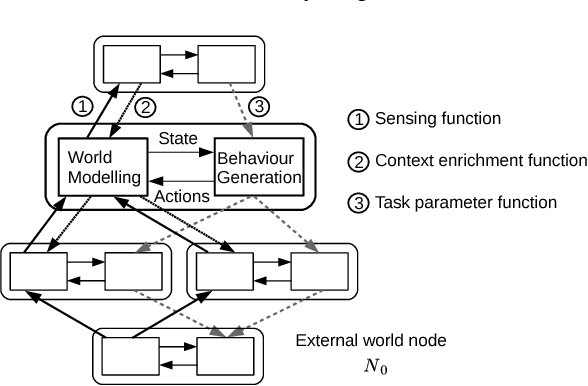
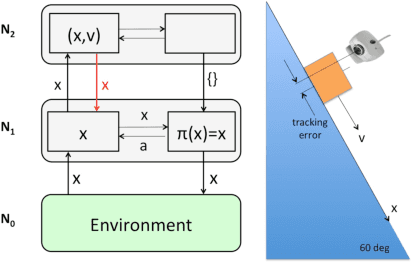
Cognition does not only depend on bottom-up sensor feature abstraction, but also relies on contextual information being passed top-down. Context is higher level information that helps to predict belief states at lower levels. The main contribution of this paper is to provide a formalisation of perceptual context and its integration into a new process model for cognitive hierarchies. Several simple instantiations of a cognitive hierarchy are used to illustrate the role of context. Notably, we demonstrate the use context in a novel approach to visually track the pose of rigid objects with just a 2D camera.