 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADTI: Fourier and Attention Driven Diffusion for Multivariate Time Series Imputation
Dec 17, 2025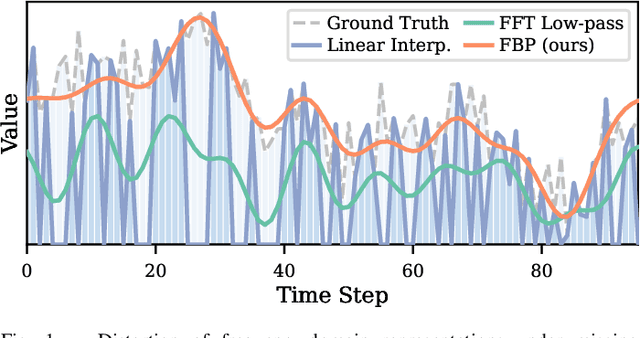
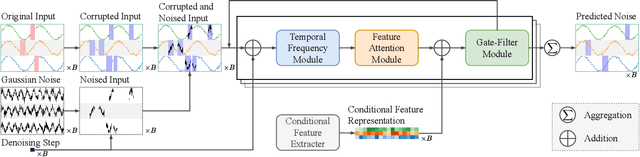

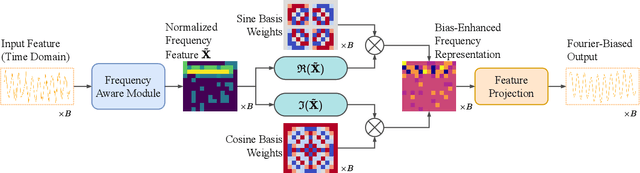
Multivariate time series imputation is fundamental in applications such as healthcare, traffic forecasting, and biological modeling, where sensor failures and irregular sampling lead to pervasive missing values. However, existing Transformer- and diffusion-based models lack explicit inductive biases and frequency awareness, limiting their generalization under structured missing patterns and distribution shifts. We propose FADTI, a diffusion-based framework that injects frequency-informed feature modulation via a learnable Fourier Bias Projection (FBP) module and combines it with temporal modeling through self-attention and gated convolution. FBP supports multiple spectral bases, enabling adaptive encoding of both stationary and non-stationary patterns. This design injects frequency-domain inductive bias into the generative imputation process. Experiments on multiple benchmarks, including a newly introduced biological time series dataset, show that FADTI consistently outperforms state-of-the-art methods, particularly under high missing rates. Code is available at https://anonymous.4open.science/r/TimeSeriesImputation-52BF
Seeing Text in the Dark: Algorithm and Benchmark
Apr 13, 2024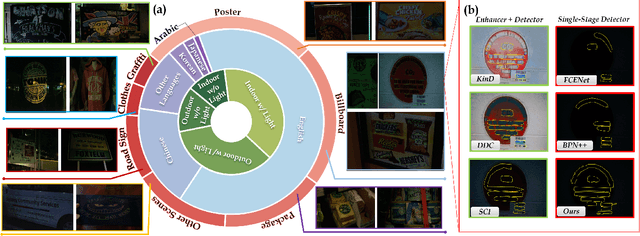

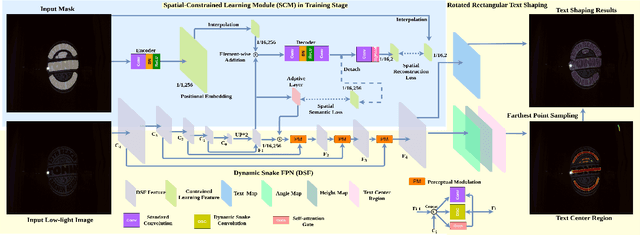

Localizing text in low-light environments is challenging due to visual degradations. Although a straightforward solution involves a two-stage pipeline with low-light image enhancement (LLE) as the initial step followed by detector, LLE is primarily designed for human vision instead of machine and can accumulate errors. In this work, we propose an efficient and effective single-stage approach for localizing text in dark that circumvents the need for LLE. We introduce a constrained learning module as an auxiliary mechanism during the training stage of the text detector. This module is designed to guide the text detector in preserving textual spatial features amidst feature map resizing, thus minimizing the loss of spatial information in texts under low-light visual degradations. Specifically, we incorporate spatial reconstruction and spatial semantic constraints within this module to ensure the text detector acquires essential positional and contextual range knowledge. Our approach enhances the original text detector's ability to identify text's local topological features using a dynamic snake feature pyramid network and adopts a bottom-up contour shaping strategy with a novel rectangular accumulation technique for accurate delineation of streamlined text features. In addition, we present a comprehensive low-light dataset for arbitrary-shaped text, encompassing diverse scenes and languages. Notably, our method achieves state-of-the-art results on this low-light dataset and exhibits comparable performance on standard normal light datasets. The code and dataset will be released.
Attention-aware Social Graph Transformer Networks for Stochastic Trajectory Prediction
Dec 26, 2023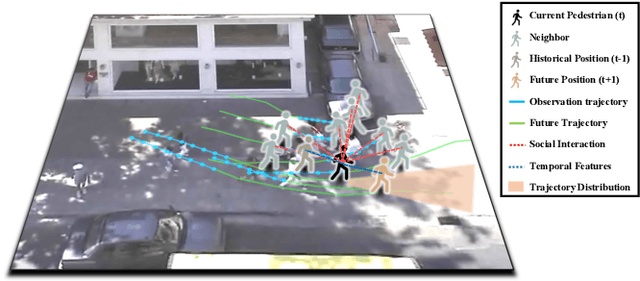
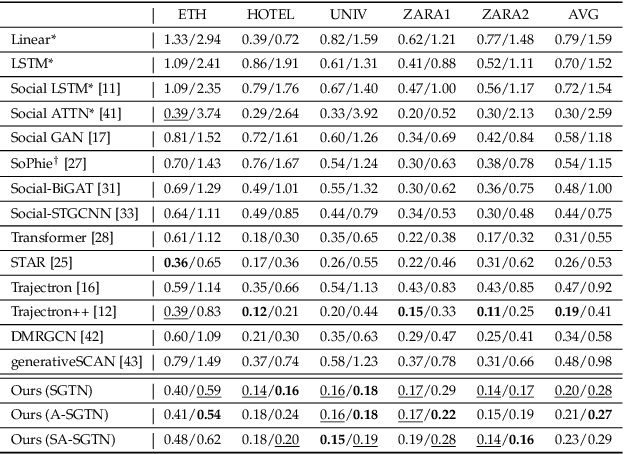
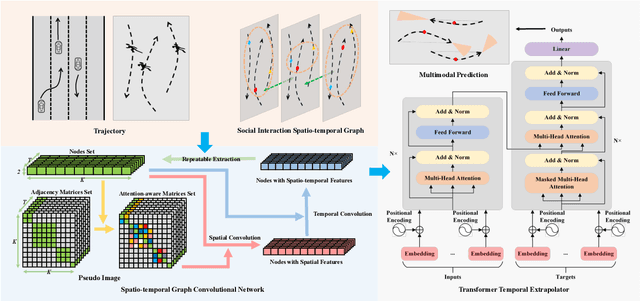
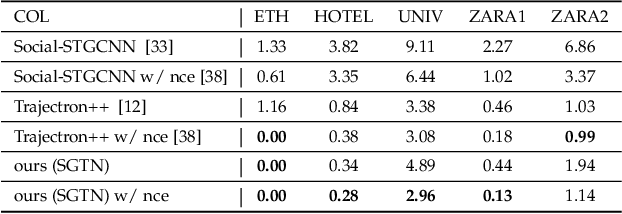
Trajectory prediction is fundamental to various intelligent technologies, such as autonomous driving and robotics. The motion prediction of pedestrians and vehicles helps emergency braking, reduces collisions, and improves traffic safety. Current trajectory prediction research faces problems of complex social interactions, high dynamics and multi-modality. Especially, it still has limitations in long-time prediction. We propose Attention-aware Social Graph Transformer Networks for multi-modal trajectory prediction. We combine Graph Convolutional Networks and Transformer Networks by generating stable resolution pseudo-images from Spatio-temporal graphs through a designed stacking and interception method. Furthermore, we design the attention-aware module to handle social interaction information in scenarios involving mixed pedestrian-vehicle traffic. Thus, we maintain the advantages of the Graph and Transformer, i.e., the ability to aggregate information over an arbitrary number of neighbors and the ability to perform complex time-dependent data processing. We conduct experiments on datasets involving pedestrian, vehicle, and mixed trajectories, respectively. Our results demonstrate that our model minimizes displacement errors across various metrics and significantly reduces the likelihood of collisions. It is worth noting that our model effectively reduces the final displacement error, illustrating the ability of our model to predict for a long time.
Distilled Mid-Fusion Transformer Networks for Multi-Modal Human Activity Recognition
May 05, 2023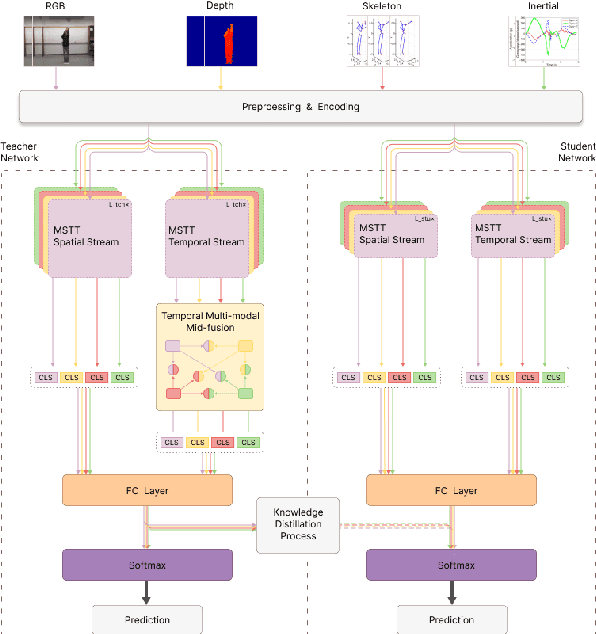

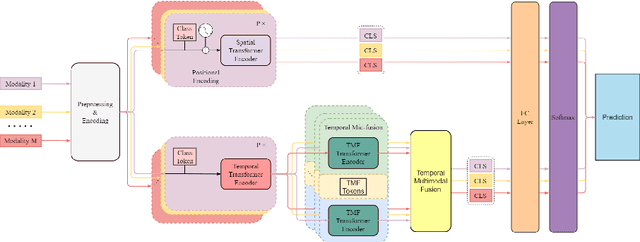
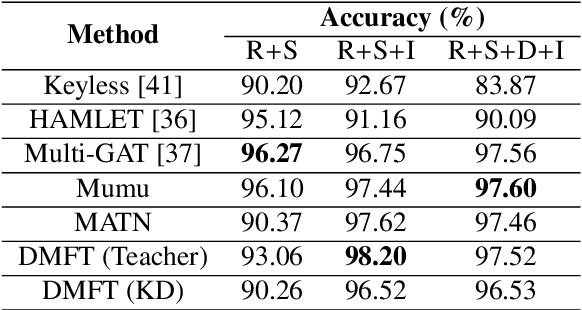
Human Activity Recognition is an important task in many human-computer collaborative scenarios, whilst having various practical applications. Although uni-modal approaches have been extensively studied, they suffer from data quality and require modality-specific feature engineering, thus not being robust and effective enough for real-world deployment. By utilizing various sensors, Multi-modal Human Activity Recognition could utilize the complementary information to build models that can generalize well. While deep learning methods have shown promising results, their potential in extracting salient multi-modal spatial-temporal features and better fusing complementary information has not been fully explored. Also, reducing the complexity of the multi-modal approach for edge deployment is another problem yet to resolve. To resolve the issues, a knowledge distillation-based Multi-modal Mid-Fusion approach, DMFT, is proposed to conduct informative feature extraction and fusion to resolve the Multi-modal Human Activity Recognition task efficiently. DMFT first encodes the multi-modal input data into a unified representation. Then the DMFT teacher model applies an attentive multi-modal spatial-temporal transformer module that extracts the salient spatial-temporal features. A temporal mid-fusion module is also proposed to further fuse the temporal features. Then the knowledge distillation method is applied to transfer the learned representation from the teacher model to a simpler DMFT student model, which consists of a lite version of the multi-modal spatial-temporal transformer module, to produce the results. Evaluation of DMFT was conducted on two public multi-modal human activity recognition datasets with various state-of-the-art approaches. The experimental results demonstrate that the model achieves competitive performance in terms of effectiveness, scalability, and robustness.
Uncertainty-Aware Pedestrian Trajectory Prediction via Distributional Diffusion
Mar 15, 2023



Tremendous efforts have been devoted to pedestrian trajectory prediction using generative modeling for accommodating uncertainty and multi-modality in human behaviors. An individual's inherent uncertainty, e.g., change of destination, can be masked by complex patterns resulting from the movements of interacting pedestrians. However, latent variable-based generative models often entangle such uncertainty with complexity, leading to either limited expressivity or overconfident predictions. In this work, we propose to separately model these two factors by implicitly deriving a flexible distribution that describes complex pedestrians' movements, whereas incorporating predictive uncertainty of individuals with explicit density functions over their future locations. More specifically, we present an uncertainty-aware pedestrian trajectory prediction framework, parameterizing sufficient statistics for the distributions of locations that jointly comprise the multi-modal trajectories. We further estimate these parameters of interest by approximating a denoising process that progressively recovers pedestrian movements from noise. Unlike prior studies, we translate the predictive stochasticity to the explicit distribution, making it readily used to generate plausible future trajectories indicating individuals' self-uncertainty. Moreover, our framework is model-agnostic for compatibility with different neural network architectures. We empirically show the performance advantages of our framework on widely-used benchmarks, outperforming state-of-the-art in most scenes even with lighter backbones.