 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAIRT2V: Training-Free Debiasing for Text-to-Video Diffusion Models
Jan 28, 2026Text-to-video (T2V) diffusion models have achieved rapid progress, yet their demographic biases, particularly gender bias, remain largely unexplored. We present FairT2V, a training-free debiasing framework for text-to-video generation that mitigates encoder-induced bias without finetuning. We first analyze demographic bias in T2V models and show that it primarily originates from pretrained text encoders, which encode implicit gender associations even for neutral prompts. We quantify this effect with a gender-leaning score that correlates with bias in generated videos. Based on this insight, FairT2V mitigates demographic bias by neutralizing prompt embeddings via anchor-based spherical geodesic transformations while preserving semantics. To maintain temporal coherence, we apply debiasing only during early identity-forming steps through a dynamic denoising schedule. We further propose a video-level fairness evaluation protocol combining VideoLLM-based reasoning with human verification. Experiments on the modern T2V model Open-Sora show that FairT2V substantially reduces demographic bias across occupations with minimal impact on video quality.
Reinforcement Learning for Follow-the-Leader Robotic Endoscopic Navigation via Synthetic Data
Jan 06, 2026Autonomous navigation is crucial for both medical and industrial endoscopic robots, enabling safe and efficient exploration of narrow tubular environments without continuous human intervention, where avoiding contact with the inner walls has been a longstanding challenge for prior approaches. We present a follow-the-leader endoscopic robot based on a flexible continuum structure designed to minimize contact between the endoscope body and intestinal walls, thereby reducing patient discomfort. To achieve this objective, we propose a vision-based deep reinforcement learning framework guided by monocular depth estimation. A realistic intestinal simulation environment was constructed in \textit{NVIDIA Omniverse} to train and evaluate autonomous navigation strategies. Furthermore, thousands of synthetic intraluminal images were generated using NVIDIA Replicator to fine-tune the Depth Anything model, enabling dense three-dimensional perception of the intestinal environment with a single monocular camera. Subsequently, we introduce a geometry-aware reward and penalty mechanism to enable accurate lumen tracking. Compared with the original Depth Anything model, our method improves $δ_{1}$ depth accuracy by 39.2% and reduces the navigation J-index by 0.67 relative to the second-best method, demonstrating the robustness and effectiveness of the proposed approach.
Principles2Plan: LLM-Guided System for Operationalising Ethical Principles into Plans
Dec 09, 2025Ethical awareness is critical for robots operating in human environments, yet existing automated planning tools provide little support. Manually specifying ethical rules is labour-intensive and highly context-specific. We present Principles2Plan, an interactive research prototype demonstrating how a human and a Large Language Model (LLM) can collaborate to produce context-sensitive ethical rules and guide automated planning. A domain expert provides the planning domain, problem details, and relevant high-level principles such as beneficence and privacy. The system generates operationalisable ethical rules consistent with these principles, which the user can review, prioritise, and supply to a planner to produce ethically-informed plans. To our knowledge, no prior system supports users in generating principle-grounded rules for classical planning contexts. Principles2Plan showcases the potential of human-LLM collaboration for making ethical automated planning more practical and feasible.
Temporal Alignment of Time Sensitive Facts with Activation Engineering
May 20, 2025Large Language Models (LLMs) are trained on diverse and often conflicting knowledge spanning multiple domains and time periods. Some of this knowledge is only valid within specific temporal contexts, such as answering the question, "Who is the President of the United States in 2022?" Ensuring LLMs generate time appropriate responses is crucial for maintaining relevance and accuracy. In this work we explore activation engineering as a method for temporally aligning LLMs to improve factual recall without any training or dataset creation. In this research we explore an activation engineering technique to ground three versions of LLaMA 2 to specific points in time and examine the effects of varying injection layers and prompting strategies. Our experiments demonstrate up to a 44% and 16% improvement in relative and explicit prompting respectively, achieving comparable performance to the fine-tuning method proposed by Zhao et al. (2024) . Notably, our approach achieves similar results to the fine-tuning baseline while being significantly more computationally efficient and requiring no pre-aligned datasets.
Prototype-Based Image Prompting for Weakly Supervised Histopathological Image Segmentation
Mar 15, 2025



Weakly supervised image segmentation with image-level labels has drawn attention due to the high cost of pixel-level annotations. Traditional methods using Class Activation Maps (CAMs) often highlight only the most discriminative regions, leading to incomplete masks. Recent approaches that introduce textual information struggle with histopathological images due to inter-class homogeneity and intra-class heterogeneity. In this paper, we propose a prototype-based image prompting framework for histopathological image segmentation. It constructs an image bank from the training set using clustering, extracting multiple prototype features per class to capture intra-class heterogeneity. By designing a matching loss between input features and class-specific prototypes using contrastive learning, our method addresses inter-class homogeneity and guides the model to generate more accurate CAMs. Experiments on four datasets (LUAD-HistoSeg, BCSS-WSSS, GCSS, and BCSS) show that our method outperforms existing weakly supervised segmentation approaches, setting new benchmarks in histopathological image segmentation.
Interpretable Image Classification via Non-parametric Part Prototype Learning
Mar 13, 2025Classifying images with an interpretable decision-making process is a long-standing problem in computer vision. In recent years, Prototypical Part Networks has gained traction as an approach for self-explainable neural networks, due to their ability to mimic human visual reasoning by providing explanations based on prototypical object parts. However, the quality of the explanations generated by these methods leaves room for improvement, as the prototypes usually focus on repetitive and redundant concepts. Leveraging recent advances in prototype learning, we present a framework for part-based interpretable image classification that learns a set of semantically distinctive object parts for each class, and provides diverse and comprehensive explanations. The core of our method is to learn the part-prototypes in a non-parametric fashion, through clustering deep features extracted from foundation vision models that encode robust semantic information. To quantitatively evaluate the quality of explanations provided by ProtoPNets, we introduce Distinctiveness Score and Comprehensiveness Score. Through evaluation on CUB-200-2011, Stanford Cars and Stanford Dogs datasets, we show that our framework compares favourably against existing ProtoPNets while achieving better interpretability. Code is available at: https://github.com/zijizhu/proto-non-param.
Structure based SAT dataset for analysing GNN generalisation
Feb 17, 2025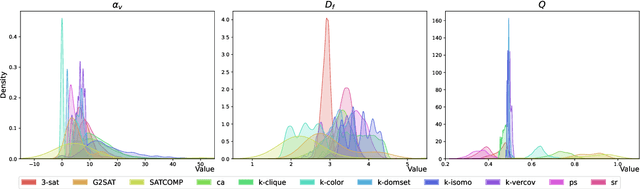
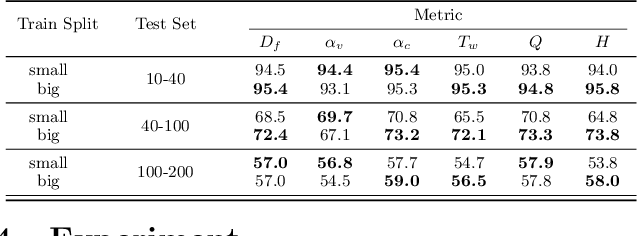
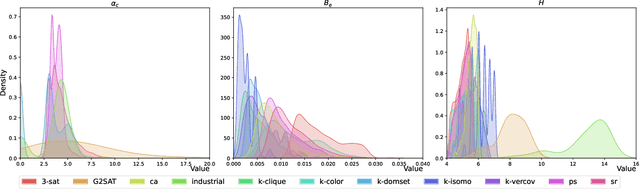
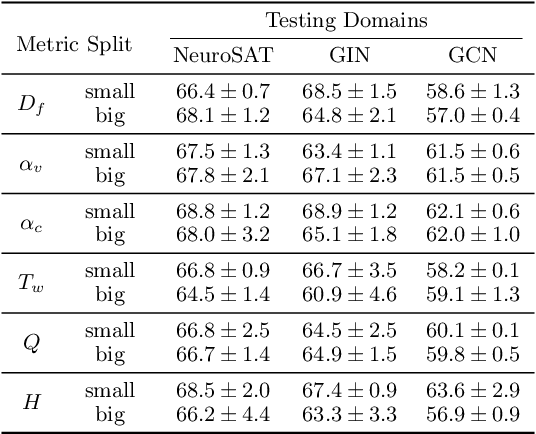
Satisfiability (SAT) solvers based on techniques such as conflict driven clause learning (CDCL) have produced excellent performance on both synthetic and real world industrial problems. While these CDCL solvers only operate on a per-problem basis, graph neural network (GNN) based solvers bring new benefits to the field by allowing practitioners to exploit knowledge gained from solved problems to expedite solving of new SAT problems. However, one specific area that is often studied in the context of CDCL solvers, but largely overlooked in GNN solvers, is the relationship between graph theoretic measure of structure in SAT problems and the generalisation ability of GNN solvers. To bridge the gap between structural graph properties (e.g., modularity, self-similarity) and the generalisability (or lack thereof) of GNN based SAT solvers, we present StructureSAT: a curated dataset, along with code to further generate novel examples, containing a diverse set of SAT problems from well known problem domains. Furthermore, we utilise a novel splitting method that focuses on deconstructing the families into more detailed hierarchies based on their structural properties. With the new dataset, we aim to help explain problematic generalisation in existing GNN SAT solvers by exploiting knowledge of structural graph properties. We conclude with multiple future directions that can help researchers in GNN based SAT solving develop more effective and generalisable SAT solvers.
Revitalizing Reconstruction Models for Multi-class Anomaly Detection via Class-Aware Contrastive Learning
Dec 06, 2024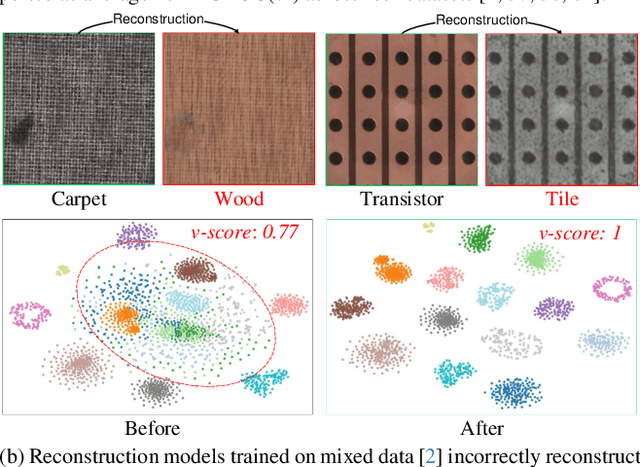
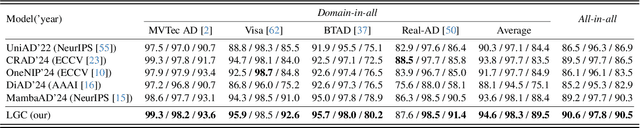
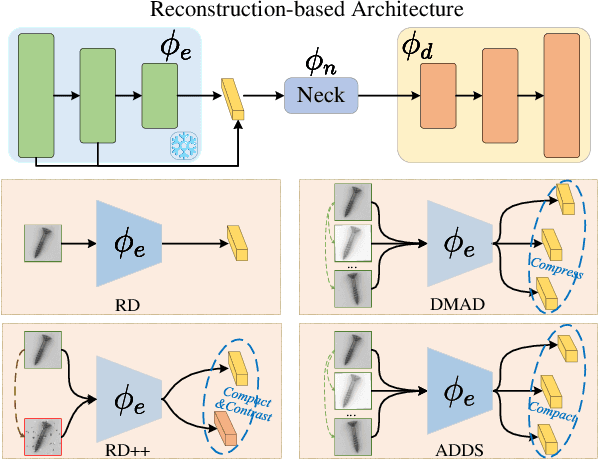

For anomaly detection (AD), early approaches often train separate models for individual classes, yielding high performance but posing challenges in scalability and resource management. Recent efforts have shifted toward training a single model capable of handling multiple classes. However, directly extending early AD methods to multi-class settings often results in degraded performance. In this paper, we analyze this degradation observed in reconstruction-based methods, identifying two key issues: catastrophic forgetting and inter-class confusion. To this end, we propose a plug-and-play modification by incorporating class-aware contrastive learning (CL). By explicitly leveraging raw object category information (e.g., carpet or wood) as supervised signals, we apply local CL to fine-tune multiscale features and global CL to learn more compact feature representations of normal patterns, thereby effectively adapting the models to multi-class settings. Experiments across four datasets (over 60 categories) verify the effectiveness of our approach, yielding significant improvements and superior performance compared to advanced methods. Notably, ablation studies show that even using pseudo-class labels can achieve comparable performance.
MANTA: A Large-Scale Multi-View and Visual-Text Anomaly Detection Dataset for Tiny Objects
Dec 06, 2024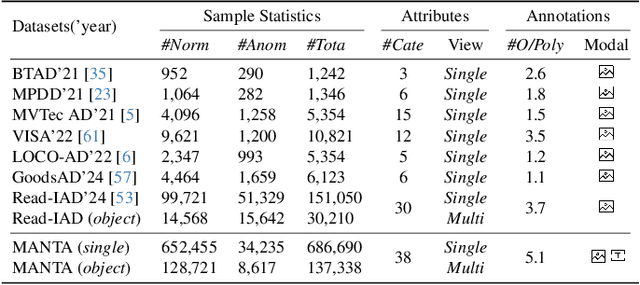
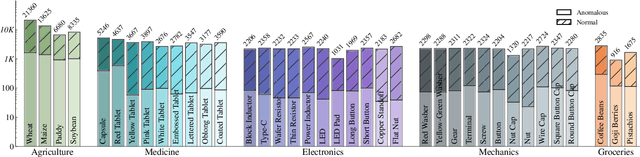

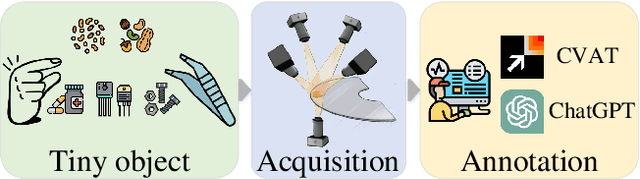
We present MANTA, a visual-text anomaly detection dataset for tiny objects. The visual component comprises over 137.3K images across 38 object categories spanning five typical domains, of which 8.6K images are labeled as anomalous with pixel-level annotations. Each image is captured from five distinct viewpoints to ensure comprehensive object coverage. The text component consists of two subsets: Declarative Knowledge, including 875 words that describe common anomalies across various domains and specific categories, with detailed explanations for < what, why, how>, including causes and visual characteristics; and Constructivist Learning, providing 2K multiple-choice questions with varying levels of difficulty, each paired with images and corresponded answer explanations. We also propose a baseline for visual-text tasks and conduct extensive benchmarking experiments to evaluate advanced methods across different settings, highlighting the challenges and efficacy of our dataset.
Soft Tensor Product Representations for Fully Continuous, Compositional Visual Representations
Dec 05, 2024



Since the inception of the classicalist vs. connectionist debate, it has been argued that the ability to systematically combine symbol-like entities into compositional representations is crucial for human intelligence. In connectionist systems, the field of disentanglement has emerged to address this need by producing representations with explicitly separated factors of variation (FoV). By treating the overall representation as a *string-like concatenation* of the inferred FoVs, however, disentanglement provides a fundamentally *symbolic* treatment of compositional structure, one inherently at odds with the underlying *continuity* of deep learning vector spaces. We hypothesise that this symbolic-continuous mismatch produces broadly suboptimal performance in deep learning models that learn or use such representations. To fully align compositional representations with continuous vector spaces, we extend Smolensky's Tensor Product Representation (TPR) and propose a new type of inherently *continuous* compositional representation, *Soft TPR*, along with a theoretically-principled architecture, *Soft TPR Autoencoder*, designed specifically for learning Soft TPRs. In the visual representation learning domain, our Soft TPR confers broad benefits over symbolic compositional representations: state-of-the-art disentanglement and improved representation learner convergence, along with enhanced sample efficiency and superior low-sample regime performance for downstream models, empirically affirming the value of our inherently continuous compositional representation learning framework.