 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinToolBench: Evaluating LLM Agents for Real-World Financial Tool Use
Mar 09, 2026The integration of Large Language Models (LLMs) into the financial domain is driving a paradigm shift from passive information retrieval to dynamic, agentic interaction. While general-purpose tool learning has witnessed a surge in benchmarks, the financial sector, characterized by high stakes, strict compliance, and rapid data volatility, remains critically underserved. Existing financial evaluations predominantly focus on static textual analysis or document-based QA, ignoring the complex reality of tool execution. Conversely, general tool benchmarks lack the domain-specific rigor required for finance, often relying on toy environments or a negligible number of financial APIs. To bridge this gap, we introduce FinToolBench, the first real-world, runnable benchmark dedicated to evaluating financial tool learning agents. Unlike prior works limited to a handful of mock tools, FinToolBench establishes a realistic ecosystem coupling 760 executable financial tools with 295 rigorous, tool-required queries. We propose a novel evaluation framework that goes beyond binary execution success, assessing agents on finance-critical dimensions: timeliness, intent type, and regulatory domain alignment. Furthermore, we present FATR, a finance-aware tool retrieval and reasoning baseline that enhances stability and compliance. By providing the first testbed for auditable, agentic financial execution, FinToolBench sets a new standard for trustworthy AI in finance. The tool manifest, execution environment, and evaluation code will be open-sourced to facilitate future research.
Structure based SAT dataset for analysing GNN generalisation
Feb 17, 2025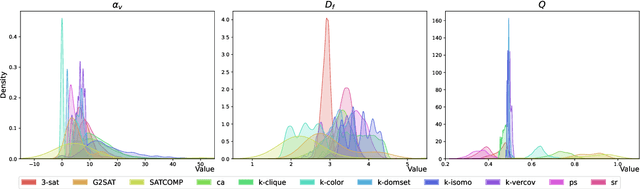
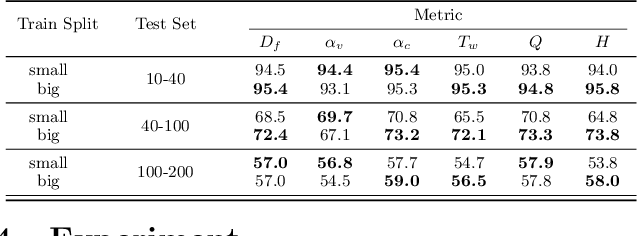
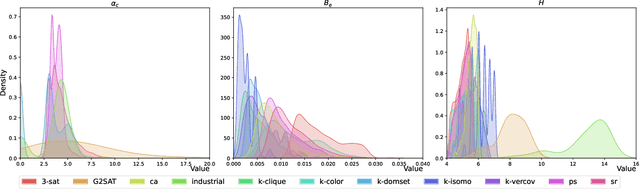
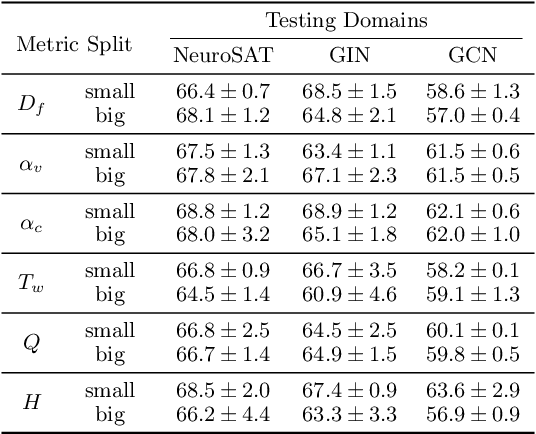
Satisfiability (SAT) solvers based on techniques such as conflict driven clause learning (CDCL) have produced excellent performance on both synthetic and real world industrial problems. While these CDCL solvers only operate on a per-problem basis, graph neural network (GNN) based solvers bring new benefits to the field by allowing practitioners to exploit knowledge gained from solved problems to expedite solving of new SAT problems. However, one specific area that is often studied in the context of CDCL solvers, but largely overlooked in GNN solvers, is the relationship between graph theoretic measure of structure in SAT problems and the generalisation ability of GNN solvers. To bridge the gap between structural graph properties (e.g., modularity, self-similarity) and the generalisability (or lack thereof) of GNN based SAT solvers, we present StructureSAT: a curated dataset, along with code to further generate novel examples, containing a diverse set of SAT problems from well known problem domains. Furthermore, we utilise a novel splitting method that focuses on deconstructing the families into more detailed hierarchies based on their structural properties. With the new dataset, we aim to help explain problematic generalisation in existing GNN SAT solvers by exploiting knowledge of structural graph properties. We conclude with multiple future directions that can help researchers in GNN based SAT solving develop more effective and generalisable SAT solvers.
Collaborative Tracking Learning for Frame-Rate-Insensitive Multi-Object Tracking
Aug 11, 2023



Multi-object tracking (MOT) at low frame rates can reduce computational, storage and power overhead to better meet the constraints of edge devices. Many existing MOT methods suffer from significant performance degradation in low-frame-rate videos due to significant location and appearance changes between adjacent frames. To this end, we propose to explore collaborative tracking learning (ColTrack) for frame-rate-insensitive MOT in a query-based end-to-end manner. Multiple historical queries of the same target jointly track it with richer temporal descriptions. Meanwhile, we insert an information refinement module between every two temporal blocking decoders to better fuse temporal clues and refine features. Moreover, a tracking object consistency loss is proposed to guide the interaction between historical queries. Extensive experimental results demonstrate that in high-frame-rate videos, ColTrack obtains higher performance than state-of-the-art methods on large-scale datasets Dancetrack and BDD100K, and outperforms the existing end-to-end methods on MOT17. More importantly, ColTrack has a significant advantage over state-of-the-art methods in low-frame-rate videos, which allows it to obtain faster processing speeds by reducing frame-rate requirements while maintaining higher performance. Code will be released at https://github.com/yolomax/ColTrack
Deep learning numerical methods for high-dimensional fully nonlinear PIDEs and coupled FBSDEs with jumps
Jan 30, 2023We propose a deep learning algorithm for solving high-dimensional parabolic integro-differential equations (PIDEs) and high-dimensional forward-backward stochastic differential equations with jumps (FBSDEJs), where the jump-diffusion process are derived by a Brownian motion and an independent compensated Poisson random measure. In this novel algorithm, a pair of deep neural networks for the approximations of the gradient and the integral kernel is introduced in a crucial way based on deep FBSDE method. To derive the error estimates for this deep learning algorithm, the convergence of Markovian iteration, the error bound of Euler time discretization, and the simulation error of deep learning algorithm are investigated. Two numerical examples are provided to show the efficiency of this proposed algorithm.
Coherent Loss: A Generic Framework for Stable Video Segmentation
Oct 25, 2020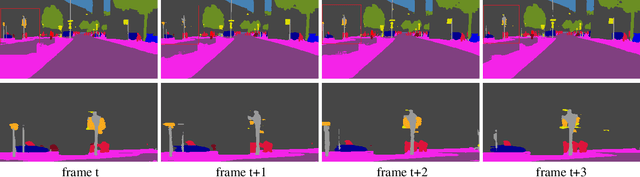

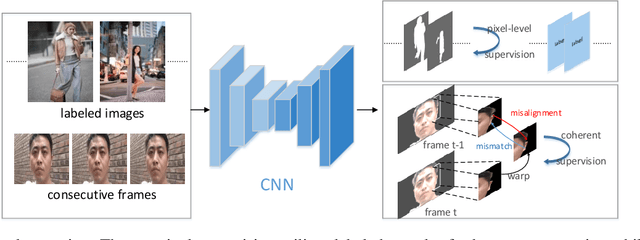
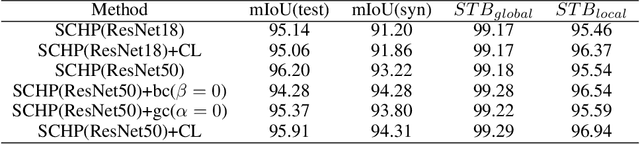
Video segmentation approaches are of great importance for numerous vision tasks especially in video manipulation for entertainment. Due to the challenges associated with acquiring high-quality per-frame segmentation annotations and large video datasets with different environments at scale, learning approaches shows overall higher accuracy on test dataset but lack strict temporal constraints to self-correct jittering artifacts in most practical applications. We investigate how this jittering artifact degrades the visual quality of video segmentation results and proposed a metric of temporal stability to numerically evaluate it. In particular, we propose a Coherent Loss with a generic framework to enhance the performance of a neural network against jittering artifacts, which combines with high accuracy and high consistency. Equipped with our method, existing video object/semantic segmentation approaches achieve a significant improvement in term of more satisfactory visual quality on video human dataset, which we provide for further research in this field, and also on DAVIS and Cityscape.
Exploiting Spatial-Temporal Modelling and Multi-Modal Fusion for Human Action Recognition
Jun 27, 2018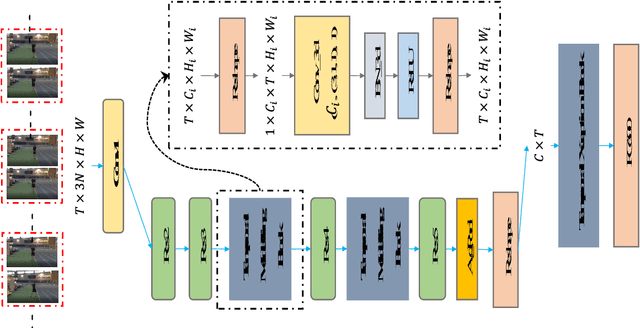

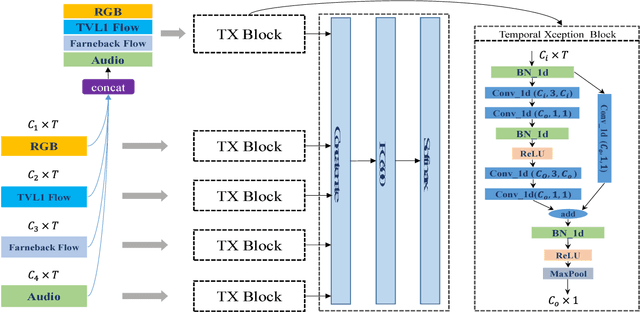

In this report, our approach to tackling the task of ActivityNet 2018 Kinetics-600 challenge is described in detail. Though spatial-temporal modelling methods, which adopt either such end-to-end framework as I3D \cite{i3d} or two-stage frameworks (i.e., CNN+RNN), have been proposed in existing state-of-the-arts for this task, video modelling is far from being well solved. In this challenge, we propose spatial-temporal network (StNet) for better joint spatial-temporal modelling and comprehensively video understanding. Besides, given that multi-modal information is contained in video source, we manage to integrate both early-fusion and later-fusion strategy of multi-modal information via our proposed improved temporal Xception network (iTXN) for video understanding. Our StNet RGB single model achieves 78.99\% top-1 precision in the Kinetics-600 validation set and that of our improved temporal Xception network which integrates RGB, flow and audio modalities is up to 82.35\%. After model ensemble, we achieve top-1 precision as high as 85.0\% on the validation set and rank No.1 among all submissions.