 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoherent Loss: A Generic Framework for Stable Video Segmentation
Paper and Code
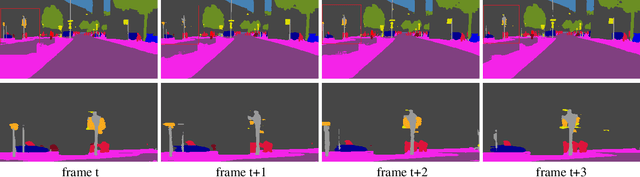

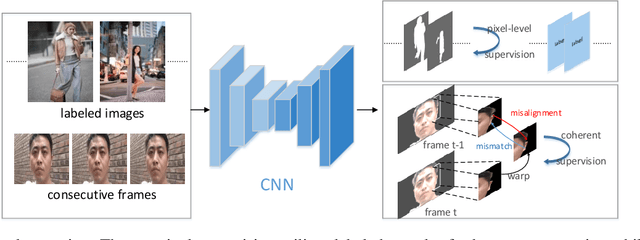
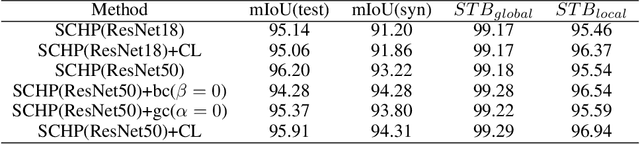
Video segmentation approaches are of great importance for numerous vision tasks especially in video manipulation for entertainment. Due to the challenges associated with acquiring high-quality per-frame segmentation annotations and large video datasets with different environments at scale, learning approaches shows overall higher accuracy on test dataset but lack strict temporal constraints to self-correct jittering artifacts in most practical applications. We investigate how this jittering artifact degrades the visual quality of video segmentation results and proposed a metric of temporal stability to numerically evaluate it. In particular, we propose a Coherent Loss with a generic framework to enhance the performance of a neural network against jittering artifacts, which combines with high accuracy and high consistency. Equipped with our method, existing video object/semantic segmentation approaches achieve a significant improvement in term of more satisfactory visual quality on video human dataset, which we provide for further research in this field, and also on DAVIS and Cityscape.