 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Bokeh Effect Rendering on Mobile GPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



As mobile cameras with compact optics are unable to produce a strong bokeh effect, lots of interest is now devoted to deep learning-based solutions for this task. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based bokeh effect rendering approach that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The runtime of the resulting models was evaluated on the Kirin 9000's Mali GPU that provides excellent acceleration results for the majority of common deep learning ops. A detailed description of all models developed in this challenge is provided in this paper.
Coherent Loss: A Generic Framework for Stable Video Segmentation
Oct 25, 2020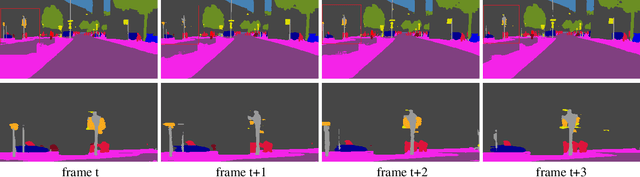

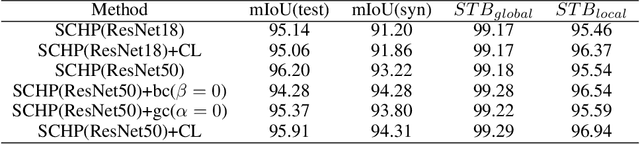
Video segmentation approaches are of great importance for numerous vision tasks especially in video manipulation for entertainment. Due to the challenges associated with acquiring high-quality per-frame segmentation annotations and large video datasets with different environments at scale, learning approaches shows overall higher accuracy on test dataset but lack strict temporal constraints to self-correct jittering artifacts in most practical applications. We investigate how this jittering artifact degrades the visual quality of video segmentation results and proposed a metric of temporal stability to numerically evaluate it. In particular, we propose a Coherent Loss with a generic framework to enhance the performance of a neural network against jittering artifacts, which combines with high accuracy and high consistency. Equipped with our method, existing video object/semantic segmentation approaches achieve a significant improvement in term of more satisfactory visual quality on video human dataset, which we provide for further research in this field, and also on DAVIS and Cityscape.
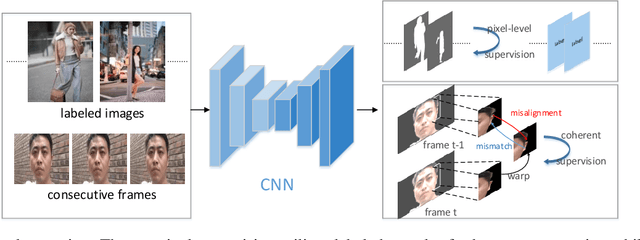
Multi-source weak supervision for saliency detection
Apr 01, 2019

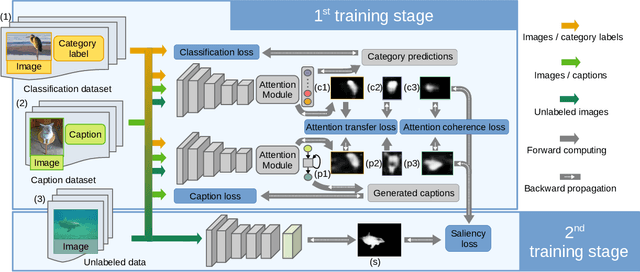
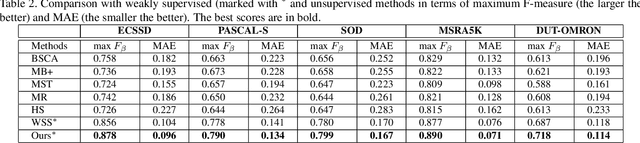
The high cost of pixel-level annotations makes it appealing to train saliency detection models with weak supervision. However, a single weak supervision source usually does not contain enough information to train a well-performing model. To this end, we propose a unified framework to train saliency detection models with diverse weak supervision sources. In this paper, we use category labels, captions, and unlabelled data for training, yet other supervision sources can also be plugged into this flexible framework. We design a classification network (CNet) and a caption generation network (PNet), which learn to predict object categories and generate captions, respectively, meanwhile highlight the most important regions for corresponding tasks. An attention transfer loss is designed to transmit supervision signal between networks, such that the network designed to be trained with one supervision source can benefit from another. An attention coherence loss is defined on unlabelled data to encourage the networks to detect generally salient regions instead of task-specific regions. We use CNet and PNet to generate pixel-level pseudo labels to train a saliency prediction network (SNet). During the testing phases, we only need SNet to predict saliency maps. Experiments demonstrate the performance of our method compares favourably against unsupervised and weakly supervised methods and even some supervised methods.