 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDongYuan: An LLM-Based Framework for Integrative Chinese and Western Medicine Spleen-Stomach Disorders Diagnosis
Mar 30, 2026The clinical burden of spleen-stomach disorders is substantial. While large language models (LLMs) offer new potential for medical applications, they face three major challenges in the context of integrative Chinese and Western medicine (ICWM): a lack of high-quality data, the absence of models capable of effectively integrating the reasoning logic of traditional Chinese medicine (TCM) syndrome differentiation with that of Western medical (WM) disease diagnosis, and the shortage of a standardized evaluation benchmark. To address these interrelated challenges, we propose DongYuan, an ICWM spleen-stomach diagnostic framework. Specifically, three ICWM datasets (SSDF-Syndrome, SSDF-Dialogue, and SSDF-PD) were curated to fill the gap in high-quality data for spleen-stomach disorders. We then developed SSDF-Core, a core diagnostic LLM that acquires robust ICWM reasoning capabilities through a two-stage training regimen of supervised fine-tuning. tuning (SFT) and direct preference optimization (DPO), and complemented it with SSDF-Navigator, a pluggable consultation navigation model designed to optimize clinical inquiry strategies. Additionally, we established SSDF-Bench, a comprehensive evaluation benchmark focused on ICWM diagnosis of spleen-stomach disorders. Experimental results demonstrate that SSDF-Core significantly outperforms 12 mainstream baselines on SSDF-Bench. DongYuan lays a solid methodological foundation and provides practical technical references for the future development of intelligent ICWM diagnostic systems.
MVHOI: Bridge Multi-view Condition to Complex Human-Object Interaction Video Reenactment via 3D Foundation Model
Mar 16, 2026Human-Object Interaction (HOI) video reenactment with realistic motion remains a frontier in expressive digital human creation. Existing approaches primarily handle simple image-plane motion (e.g., in-plane translations), struggling with complex non-planar manipulations like out-of-plane reorientation. In this paper, we propose MVHOI, a two-stage HOI video reenactment framework that bridges multi-view reference conditions and video foundation models via a 3D Foundation Model (3DFM). The 3DFM first produces view-consistent object priors conditioned on implicit motion dynamics across novel viewpoints. A controllable video generation model then synthesizes high-fidelity object texture by incorporating multi-view reference images, ensuring appearance consistency via a reasonable retrieval mechanism. By enabling these two stages to mutually reinforce one another during the inference phase, our framework shows superior performance in generating long-duration HOI videos with intricate object manipulations. Extensive experiments show substantial improvements over prior approaches, especially for HOI with complex 3D object manipulations.
FreeOrbit4D: Training-Free Arbitrary Camera Redirection for Monocular Videos via Geometry-Complete 4D Reconstruction
Jan 26, 2026Camera redirection aims to replay a dynamic scene from a single monocular video under a user-specified camera trajectory. However, large-angle redirection is inherently ill-posed: a monocular video captures only a narrow spatio-temporal view of a dynamic 3D scene, providing highly partial observations of the underlying 4D world. The key challenge is therefore to recover a complete and coherent representation from this limited input, with consistent geometry and motion. While recent diffusion-based methods achieve impressive results, they often break down under large-angle viewpoint changes far from the original trajectory, where missing visual grounding leads to severe geometric ambiguity and temporal inconsistency. To address this, we present FreeOrbit4D, an effective training-free framework that tackles this geometric ambiguity by recovering a geometry-complete 4D proxy as structural grounding for video generation. We obtain this proxy by decoupling foreground and background reconstructions: we unproject the monocular video into a static background and geometry-incomplete foreground point clouds in a unified global space, then leverage an object-centric multi-view diffusion model to synthesize multi-view images and reconstruct geometry-complete foreground point clouds in canonical object space. By aligning the canonical foreground point cloud to the global scene space via dense pixel-synchronized 3D--3D correspondences and projecting the geometry-complete 4D proxy onto target camera viewpoints, we provide geometric scaffolds that guide a conditional video diffusion model. Extensive experiments show that FreeOrbit4D produces more faithful redirected videos under challenging large-angle trajectories, and our geometry-complete 4D proxy further opens a potential avenue for practical applications such as edit propagation and 4D data generation. Project page and code will be released soon.
A Multi-Level Framework for Multi-Objective Hypergraph Partitioning: Combining Minimum Spanning Tree and Proximal Gradient
Sep 26, 2025
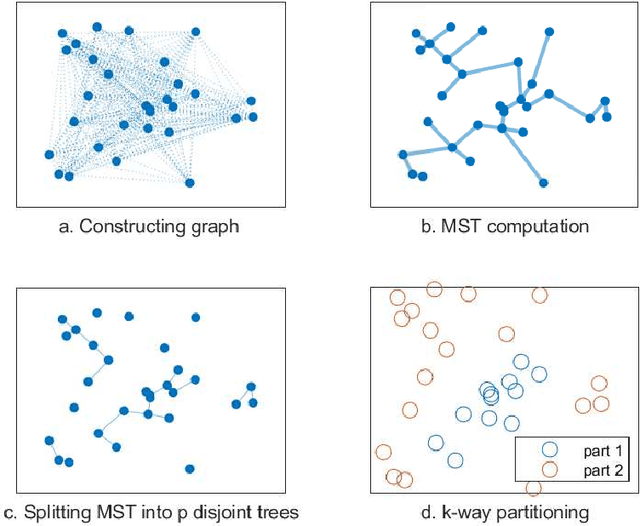

This paper proposes an efficient hypergraph partitioning framework based on a novel multi-objective non-convex constrained relaxation model. A modified accelerated proximal gradient algorithm is employed to generate diverse $k$-dimensional vertex features to avoid local optima and enhance partition quality. Two MST-based strategies are designed for different data scales: for small-scale data, the Prim algorithm constructs a minimum spanning tree followed by pruning and clustering; for large-scale data, a subset of representative nodes is selected to build a smaller MST, while the remaining nodes are assigned accordingly to reduce complexity. To further improve partitioning results, refinement strategies including greedy migration, swapping, and recursive MST-based clustering are introduced for partitions. Experimental results on public benchmark sets demonstrate that the proposed algorithm achieves reductions in cut size of approximately 2\%--5\% on average compared to KaHyPar in 2, 3, and 4-way partitioning, with improvements of up to 35\% on specific instances. Particularly on weighted vertex sets, our algorithm outperforms state-of-the-art partitioners including KaHyPar, hMetis, Mt-KaHyPar, and K-SpecPart, highlighting its superior partitioning quality and competitiveness. Furthermore, the proposed refinement strategy improves hMetis partitions by up to 16\%. A comprehensive evaluation based on virtual instance methodology and parameter sensitivity analysis validates the algorithm's competitiveness and characterizes its performance trade-offs.
iDiT-HOI: Inpainting-based Hand Object Interaction Reenactment via Video Diffusion Transformer
Jun 15, 2025Digital human video generation is gaining traction in fields like education and e-commerce, driven by advancements in head-body animation and lip-syncing technologies. However, realistic Hand-Object Interaction (HOI) - the complex dynamics between human hands and objects - continues to pose challenges. Generating natural and believable HOI reenactments is difficult due to issues such as occlusion between hands and objects, variations in object shapes and orientations, and the necessity for precise physical interactions, and importantly, the ability to generalize to unseen humans and objects. This paper presents a novel framework iDiT-HOI that enables in-the-wild HOI reenactment generation. Specifically, we propose a unified inpainting-based token process method, called Inp-TPU, with a two-stage video diffusion transformer (DiT) model. The first stage generates a key frame by inserting the designated object into the hand region, providing a reference for subsequent frames. The second stage ensures temporal coherence and fluidity in hand-object interactions. The key contribution of our method is to reuse the pretrained model's context perception capabilities without introducing additional parameters, enabling strong generalization to unseen objects and scenarios, and our proposed paradigm naturally supports long video generation. Comprehensive evaluations demonstrate that our approach outperforms existing methods, particularly in challenging real-world scenes, offering enhanced realism and more seamless hand-object interactions.
AudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Mar 25, 2025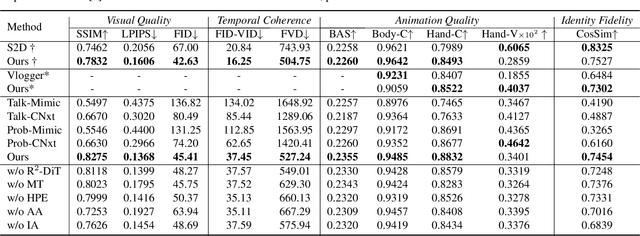
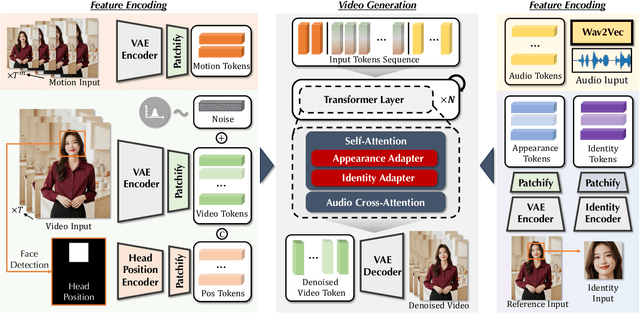
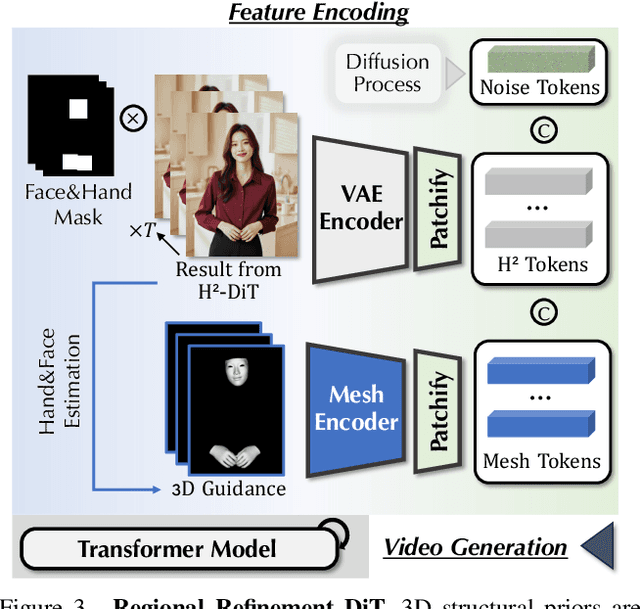

Despite the recent progress of audio-driven video generation, existing methods mostly focus on driving facial movements, leading to non-coherent head and body dynamics. Moving forward, it is desirable yet challenging to generate holistic human videos with both accurate lip-sync and delicate co-speech gestures w.r.t. given audio. In this work, we propose AudCast, a generalized audio-driven human video generation framework adopting a cascade Diffusion-Transformers (DiTs) paradigm, which synthesizes holistic human videos based on a reference image and a given audio. 1) Firstly, an audio-conditioned Holistic Human DiT architecture is proposed to directly drive the movements of any human body with vivid gesture dynamics. 2) Then to enhance hand and face details that are well-knownly difficult to handle, a Regional Refinement DiT leverages regional 3D fitting as the bridge to reform the signals, producing the final results. Extensive experiments demonstrate that our framework generates high-fidelity audio-driven holistic human videos with temporal coherence and fine facial and hand details. Resources can be found at https://guanjz20.github.io/projects/AudCast.
Cosh-DiT: Co-Speech Gesture Video Synthesis via Hybrid Audio-Visual Diffusion Transformers
Mar 13, 2025Co-speech gesture video synthesis is a challenging task that requires both probabilistic modeling of human gestures and the synthesis of realistic images that align with the rhythmic nuances of speech. To address these challenges, we propose Cosh-DiT, a Co-speech gesture video system with hybrid Diffusion Transformers that perform audio-to-motion and motion-to-video synthesis using discrete and continuous diffusion modeling, respectively. First, we introduce an audio Diffusion Transformer (Cosh-DiT-A) to synthesize expressive gesture dynamics synchronized with speech rhythms. To capture upper body, facial, and hand movement priors, we employ vector-quantized variational autoencoders (VQ-VAEs) to jointly learn their dependencies within a discrete latent space. Then, for realistic video synthesis conditioned on the generated speech-driven motion, we design a visual Diffusion Transformer (Cosh-DiT-V) that effectively integrates spatial and temporal contexts. Extensive experiments demonstrate that our framework consistently generates lifelike videos with expressive facial expressions and natural, smooth gestures that align seamlessly with speech.
TopoSD: Topology-Enhanced Lane Segment Perception with SDMap Prior
Nov 22, 2024



Recent advances in autonomous driving systems have shifted towards reducing reliance on high-definition maps (HDMaps) due to the huge costs of annotation and maintenance. Instead, researchers are focusing on online vectorized HDMap construction using on-board sensors. However, sensor-only approaches still face challenges in long-range perception due to the restricted views imposed by the mounting angles of onboard cameras, just as human drivers also rely on bird's-eye-view navigation maps for a comprehensive understanding of road structures. To address these issues, we propose to train the perception model to "see" standard definition maps (SDMaps). We encode SDMap elements into neural spatial map representations and instance tokens, and then incorporate such complementary features as prior information to improve the bird's eye view (BEV) feature for lane geometry and topology decoding. Based on the lane segment representation framework, the model simultaneously predicts lanes, centrelines and their topology. To further enhance the ability of geometry prediction and topology reasoning, we also use a topology-guided decoder to refine the predictions by exploiting the mutual relationships between topological and geometric features. We perform extensive experiments on OpenLane-V2 datasets to validate the proposed method. The results show that our model outperforms state-of-the-art methods by a large margin, with gains of +6.7 and +9.1 on the mAP and topology metrics. Our analysis also reveals that models trained with SDMap noise augmentation exhibit enhanced robustness.
MGMapNet: Multi-Granularity Representation Learning for End-to-End Vectorized HD Map Construction
Oct 10, 2024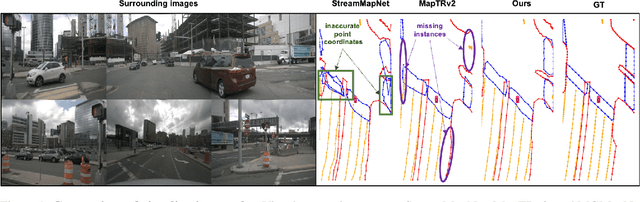
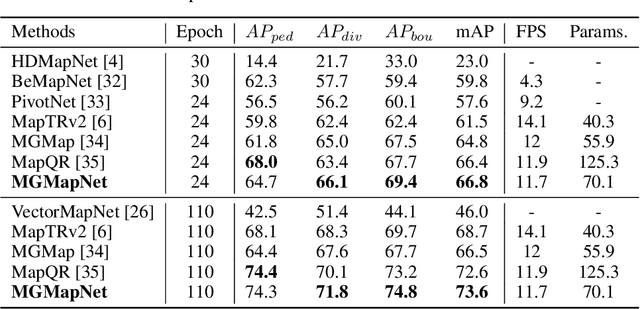
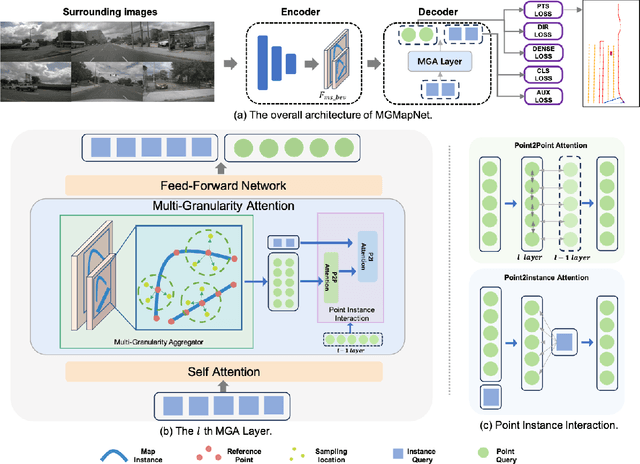

The construction of Vectorized High-Definition (HD) map typically requires capturing both category and geometry information of map elements. Current state-of-the-art methods often adopt solely either point-level or instance-level representation, overlooking the strong intrinsic relationships between points and instances. In this work, we propose a simple yet efficient framework named MGMapNet (Multi-Granularity Map Network) to model map element with a multi-granularity representation, integrating both coarse-grained instance-level and fine-grained point-level queries. Specifically, these two granularities of queries are generated from the multi-scale bird's eye view (BEV) features using a proposed Multi-Granularity Aggregator. In this module, instance-level query aggregates features over the entire scope covered by an instance, and the point-level query aggregates features locally. Furthermore, a Point Instance Interaction module is designed to encourage information exchange between instance-level and point-level queries. Experimental results demonstrate that the proposed MGMapNet achieves state-of-the-art performance, surpassing MapTRv2 by 5.3 mAP on nuScenes and 4.4 mAP on Argoverse2 respectively.
On the Convergence Rates of Set Membership Estimation of Linear Systems with Disturbances Bounded by General Convex Sets
Jun 01, 2024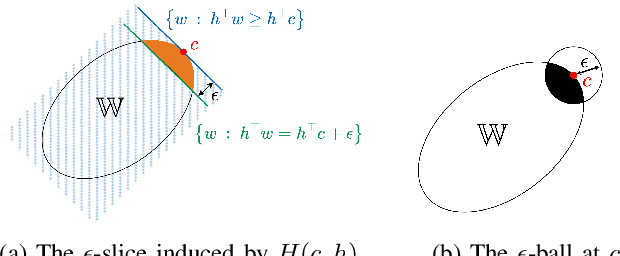
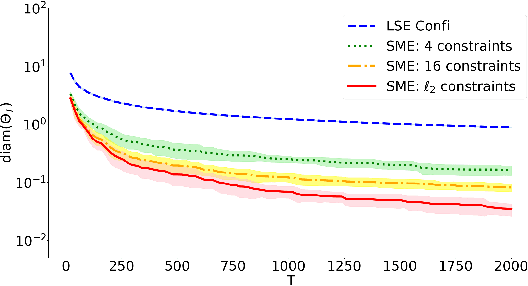
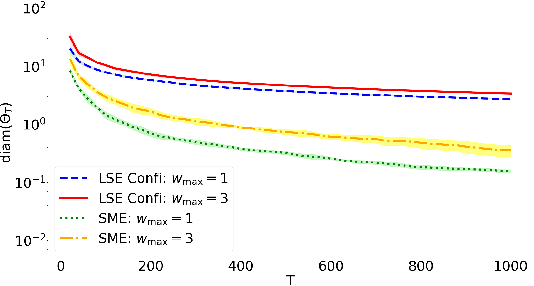
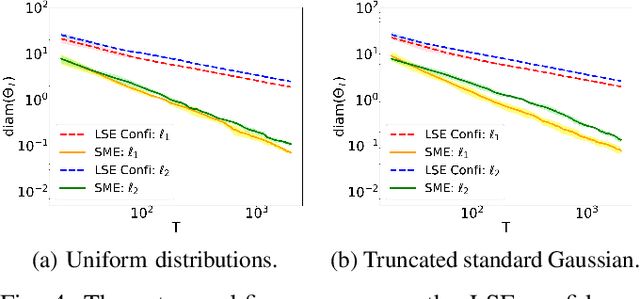
This paper studies the uncertainty set estimation of system parameters of linear dynamical systems with bounded disturbances, which is motivated by robust (adaptive) constrained control. Departing from the confidence bounds of least square estimation from the machine-learning literature, this paper focuses on a method commonly used in (robust constrained) control literature: set membership estimation (SME). SME tends to enjoy better empirical performance than LSE's confidence bounds when the system disturbances are bounded. However, the theoretical guarantees of SME are not fully addressed even for i.i.d. bounded disturbances. In the literature, SME's convergence has been proved for general convex supports of the disturbances, but SME's convergence rate assumes a special type of disturbance support: $l_\infty$ ball. The main contribution of this paper is relaxing the assumption on the disturbance support and establishing the convergence rates of SME for general convex supports, which closes the gap on the applicability of the convergence and convergence rates results. Numerical experiments on SME and LSE's confidence bounds are also provided for different disturbance supports.