 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUI-ReWalk: Massive Data Generation for GUI Agent via Stochastic Exploration and Intent-Aware Reasoning
Sep 19, 2025Graphical User Interface (GUI) Agents, powered by large language and vision-language models, hold promise for enabling end-to-end automation in digital environments. However, their progress is fundamentally constrained by the scarcity of scalable, high-quality trajectory data. Existing data collection strategies either rely on costly and inconsistent manual annotations or on synthetic generation methods that trade off between diversity and meaningful task coverage. To bridge this gap, we present GUI-ReWalk: a reasoning-enhanced, multi-stage framework for synthesizing realistic and diverse GUI trajectories. GUI-ReWalk begins with a stochastic exploration phase that emulates human trial-and-error behaviors, and progressively transitions into a reasoning-guided phase where inferred goals drive coherent and purposeful interactions. Moreover, it supports multi-stride task generation, enabling the construction of long-horizon workflows across multiple applications. By combining randomness for diversity with goal-aware reasoning for structure, GUI-ReWalk produces data that better reflects the intent-aware, adaptive nature of human-computer interaction. We further train Qwen2.5-VL-7B on the GUI-ReWalk dataset and evaluate it across multiple benchmarks, including Screenspot-Pro, OSWorld-G, UI-Vision, AndroidControl, and GUI-Odyssey. Results demonstrate that GUI-ReWalk enables superior coverage of diverse interaction flows, higher trajectory entropy, and more realistic user intent. These findings establish GUI-ReWalk as a scalable and data-efficient framework for advancing GUI agent research and enabling robust real-world automation.
Improving DeFi Accessibility through Efficient Liquidity Provisioning with Deep Reinforcement Learning
Jan 13, 2025This paper applies deep reinforcement learning (DRL) to optimize liquidity provisioning in Uniswap v3, a decentralized finance (DeFi) protocol implementing an automated market maker (AMM) model with concentrated liquidity. We model the liquidity provision task as a Markov Decision Process (MDP) and train an active liquidity provider (LP) agent using the Proximal Policy Optimization (PPO) algorithm. The agent dynamically adjusts liquidity positions by using information about price dynamics to balance fee maximization and impermanent loss mitigation. We use a rolling window approach for training and testing, reflecting realistic market conditions and regime shifts. This study compares the data-driven performance of the DRL-based strategy against common heuristics adopted by small retail LP actors that do not systematically modify their liquidity positions. By promoting more efficient liquidity management, this work aims to make DeFi markets more accessible and inclusive for a broader range of participants. Through a data-driven approach to liquidity management, this work seeks to contribute to the ongoing development of more efficient and user-friendly DeFi markets.
ITP: Instance-Aware Test Pruning for Out-of-Distribution Detection
Dec 17, 2024Out-of-distribution (OOD) detection is crucial for ensuring the reliable deployment of deep models in real-world scenarios. Recently, from the perspective of over-parameterization, a series of methods leveraging weight sparsification techniques have shown promising performance. These methods typically focus on selecting important parameters for in-distribution (ID) data to reduce the negative impact of redundant parameters on OOD detection. However, we empirically find that these selected parameters may behave overconfidently toward OOD data and hurt OOD detection. To address this issue, we propose a simple yet effective post-hoc method called Instance-aware Test Pruning (ITP), which performs OOD detection by considering both coarse-grained and fine-grained levels of parameter pruning. Specifically, ITP first estimates the class-specific parameter contribution distribution by exploring the ID data. By using the contribution distribution, ITP conducts coarse-grained pruning to eliminate redundant parameters. More importantly, ITP further adopts a fine-grained test pruning process based on the right-tailed Z-score test, which can adaptively remove instance-level overconfident parameters. Finally, ITP derives OOD scores from the pruned model to achieve more reliable predictions. Extensive experiments on widely adopted benchmarks verify the effectiveness of ITP, demonstrating its competitive performance.
The Solution for Language-Enhanced Image New Category Discovery
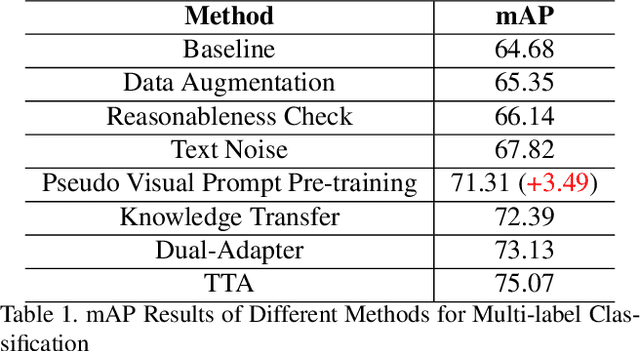
Jul 06, 2024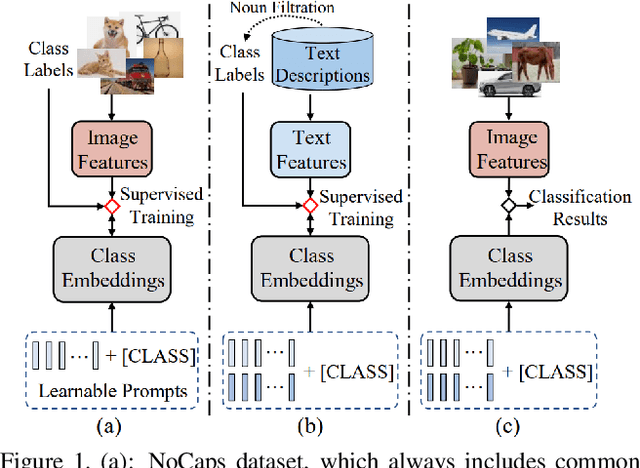
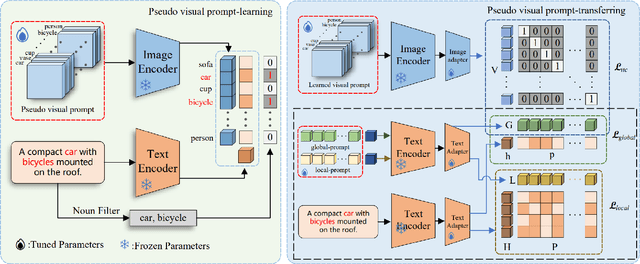
Treating texts as images, combining prompts with textual labels for prompt tuning, and leveraging the alignment properties of CLIP have been successfully applied in zero-shot multi-label image recognition. Nonetheless, relying solely on textual labels to store visual information is insufficient for representing the diversity of visual objects. In this paper, we propose reversing the training process of CLIP and introducing the concept of Pseudo Visual Prompts. These prompts are initialized for each object category and pre-trained on large-scale, low-cost sentence data generated by large language models. This process mines the aligned visual information in CLIP and stores it in class-specific visual prompts. We then employ contrastive learning to transfer the stored visual information to the textual labels, enhancing their visual representation capacity. Additionally, we introduce a dual-adapter module that simultaneously leverages knowledge from the original CLIP and new learning knowledge derived from downstream datasets. Benefiting from the pseudo visual prompts, our method surpasses the state-of-the-art not only on clean annotated text data but also on pseudo text data generated by large language models.
The Solution for the AIGC Inference Performance Optimization Competition
Jul 06, 2024In recent years, the rapid advancement of large-scale pre-trained language models based on transformer architectures has revolutionized natural language processing tasks. Among these, ChatGPT has gained widespread popularity, demonstrating human-level conversational abilities and attracting over 100 million monthly users by late 2022. Concurrently, Baidu's commercial deployment of the Ernie Wenxin model has significantly enhanced marketing effectiveness through AI-driven technologies. This paper focuses on optimizing high-performance inference for Ernie models, emphasizing GPU acceleration and leveraging the Paddle inference framework. We employ techniques such as Faster Transformer for efficient model processing, embedding layer pruning to reduce computational overhead, and FP16 half-precision inference for enhanced computational efficiency. Additionally, our approach integrates efficient data handling strategies using multi-process parallel processing to minimize latency. Experimental results demonstrate that our optimized solution achieves up to an 8.96x improvement in inference speed compared to standard methods, while maintaining competitive performance.
On the Convergence Rates of Set Membership Estimation of Linear Systems with Disturbances Bounded by General Convex Sets
Jun 01, 2024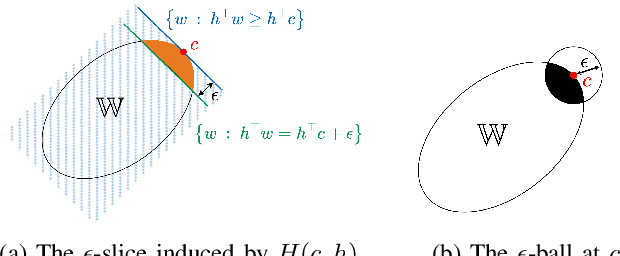
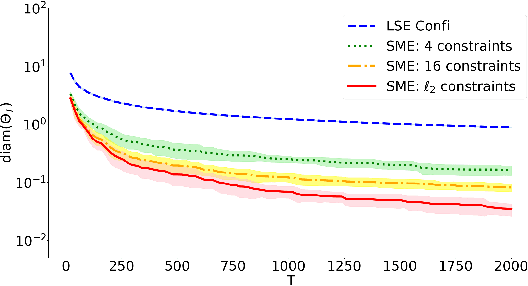
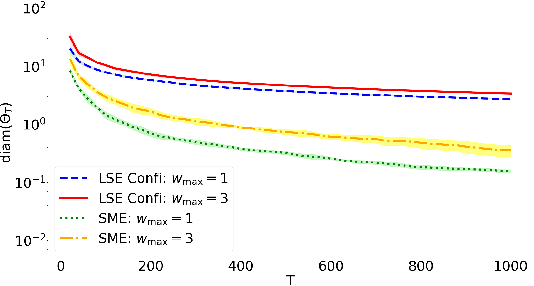
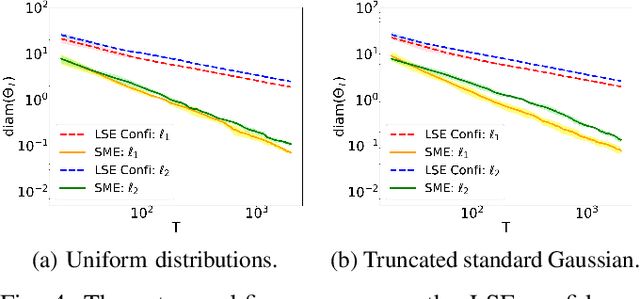
This paper studies the uncertainty set estimation of system parameters of linear dynamical systems with bounded disturbances, which is motivated by robust (adaptive) constrained control. Departing from the confidence bounds of least square estimation from the machine-learning literature, this paper focuses on a method commonly used in (robust constrained) control literature: set membership estimation (SME). SME tends to enjoy better empirical performance than LSE's confidence bounds when the system disturbances are bounded. However, the theoretical guarantees of SME are not fully addressed even for i.i.d. bounded disturbances. In the literature, SME's convergence has been proved for general convex supports of the disturbances, but SME's convergence rate assumes a special type of disturbance support: $l_\infty$ ball. The main contribution of this paper is relaxing the assumption on the disturbance support and establishing the convergence rates of SME for general convex supports, which closes the gap on the applicability of the convergence and convergence rates results. Numerical experiments on SME and LSE's confidence bounds are also provided for different disturbance supports.
Evaluating the External and Parametric Knowledge Fusion of Large Language Models
May 29, 2024



Integrating external knowledge into large language models (LLMs) presents a promising solution to overcome the limitations imposed by their antiquated and static parametric memory. Prior studies, however, have tended to over-reliance on external knowledge, underestimating the valuable contributions of an LLMs' intrinsic parametric knowledge. The efficacy of LLMs in blending external and parametric knowledge remains largely unexplored, especially in cases where external knowledge is incomplete and necessitates supplementation by their parametric knowledge. We propose to deconstruct knowledge fusion into four distinct scenarios, offering the first thorough investigation of LLM behavior across each. We develop a systematic pipeline for data construction and knowledge infusion to simulate these fusion scenarios, facilitating a series of controlled experiments. Our investigation reveals that enhancing parametric knowledge within LLMs can significantly bolster their capability for knowledge integration. Nonetheless, we identify persistent challenges in memorizing and eliciting parametric knowledge, and determining parametric knowledge boundaries. Our findings aim to steer future explorations on harmonizing external and parametric knowledge within LLMs.
Technical report on target classification in SAR track
May 03, 2024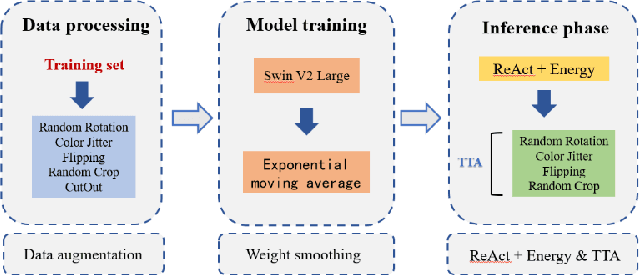

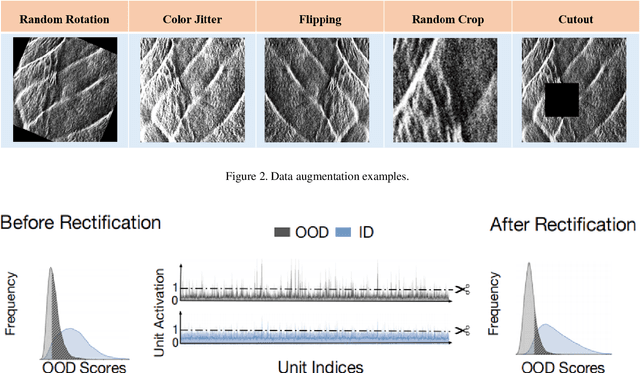
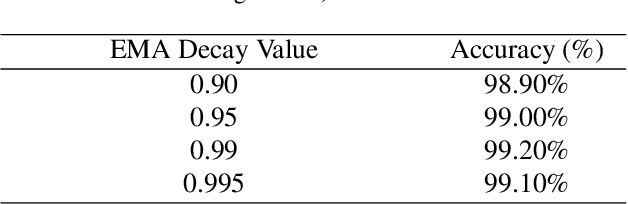
This report proposes a robust method for classifying oceanic and atmospheric phenomena using synthetic aperture radar (SAR) imagery. Our proposed method leverages the powerful pre-trained model Swin Transformer v2 Large as the backbone and employs carefully designed data augmentation and exponential moving average during training to enhance the model's generalization capability and stability. In the testing stage, a method called ReAct is utilized to rectify activation values and utilize Energy Score for more accurate measurement of model uncertainty, significantly improving out-of-distribution detection performance. Furthermore, test time augmentation is employed to enhance classification accuracy and prediction stability. Comprehensive experimental results demonstrate that each additional technique significantly improves classification accuracy, confirming their effectiveness in classifying maritime and atmospheric phenomena in SAR imagery.
The Solution for the CVPR 2023 1st foundation model challenge-Track2
Apr 02, 2024In this paper, we propose a solution for cross-modal transportation retrieval. Due to the cross-domain problem of traffic images, we divide the problem into two sub-tasks of pedestrian retrieval and vehicle retrieval through a simple strategy. In pedestrian retrieval tasks, we use IRRA as the base model and specifically design an Attribute Classification to mine the knowledge implied by attribute labels. More importantly, We use the strategy of Inclusion Relation Matching to make the image-text pairs with inclusion relation have similar representation in the feature space. For the vehicle retrieval task, we use BLIP as the base model. Since aligning the color attributes of vehicles is challenging, we introduce attribute-based object detection techniques to add color patch blocks to vehicle images for color data augmentation. This serves as strong prior information, helping the model perform the image-text alignment. At the same time, we incorporate labeled attributes into the image-text alignment loss to learn fine-grained alignment and prevent similar images and texts from being incorrectly separated. Our approach ranked first in the final B-board test with a score of 70.9.
Rethinking Boundary Discontinuity Problem for Oriented Object Detection
May 17, 2023



Oriented object detection has been developed rapidly in the past few years, where rotation equivariant is crucial for detectors to predict rotated bounding boxes. It is expected that the prediction can maintain the corresponding rotation when objects rotate, but severe mutational in angular prediction is sometimes observed when objects rotate near the boundary angle, which is well-known boundary discontinuity problem. The problem has been long believed to be caused by the sharp loss increase at the angular boundary during training, and widely used IoU-like loss generally deal with this problem by loss-smoothing. However, we experimentally find that even state-of-the-art IoU-like methods do not actually solve the problem. On further analysis, we find the essential cause of the problem lies at discontinuous angular ground-truth(box), not just discontinuous loss. There always exists an irreparable gap between continuous model ouput and discontinuous angular ground-truth, so angular prediction near the breakpoints becomes highly unstable, which cannot be eliminated just by loss-smoothing in IoU-like methods. To thoroughly solve this problem, we propose a simple and effective Angle Correct Module (ACM) based on polar coordinate decomposition. ACM can be easily plugged into the workflow of oriented object detectors to repair angular prediction. It converts the smooth value of the model output into sawtooth angular value, and then IoU-like loss can fully release their potential. Extensive experiments on multiple datasets show that whether Gaussian-based or SkewIoU methods are improved to the same performance of AP50 and AP75 with the enhancement of ACM.