 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Solution for Language-Enhanced Image New Category Discovery
Paper and Code
Jul 06, 2024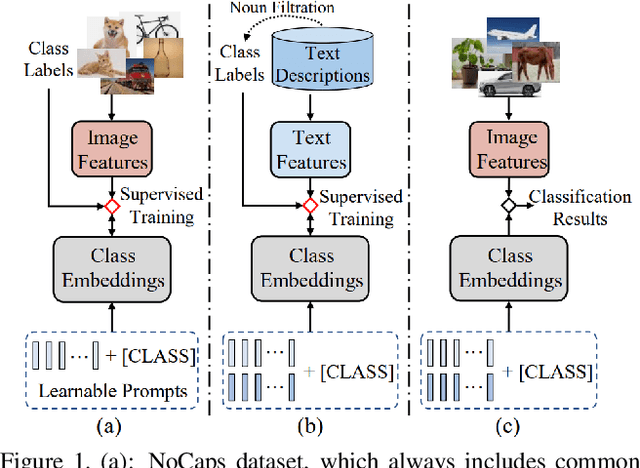
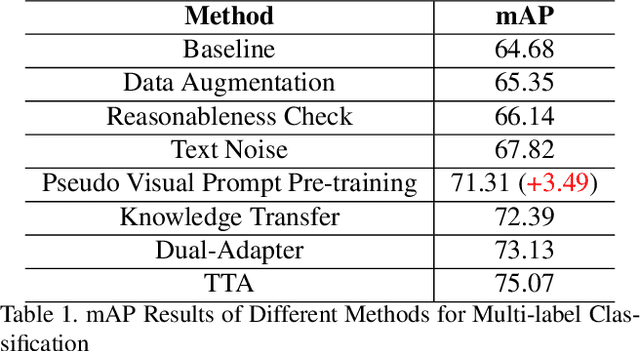
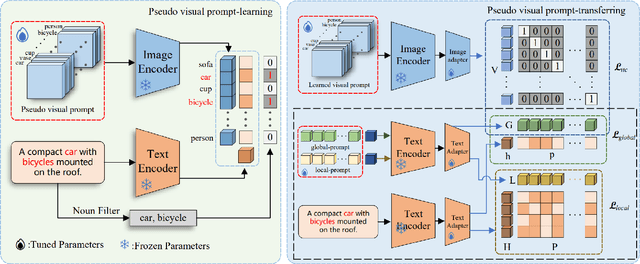
Treating texts as images, combining prompts with textual labels for prompt tuning, and leveraging the alignment properties of CLIP have been successfully applied in zero-shot multi-label image recognition. Nonetheless, relying solely on textual labels to store visual information is insufficient for representing the diversity of visual objects. In this paper, we propose reversing the training process of CLIP and introducing the concept of Pseudo Visual Prompts. These prompts are initialized for each object category and pre-trained on large-scale, low-cost sentence data generated by large language models. This process mines the aligned visual information in CLIP and stores it in class-specific visual prompts. We then employ contrastive learning to transfer the stored visual information to the textual labels, enhancing their visual representation capacity. Additionally, we introduce a dual-adapter module that simultaneously leverages knowledge from the original CLIP and new learning knowledge derived from downstream datasets. Benefiting from the pseudo visual prompts, our method surpasses the state-of-the-art not only on clean annotated text data but also on pseudo text data generated by large language models.