 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolution for OOD-CV Workshop SSB Challenge 2024 (Open-Set Recognition Track)
Sep 30, 2024



This report provides a detailed description of the method we explored and proposed in the OSR Challenge at the OOD-CV Workshop during ECCV 2024. The challenge required identifying whether a test sample belonged to the semantic classes of a classifier's training set, a task known as open-set recognition (OSR). Using the Semantic Shift Benchmark (SSB) for evaluation, we focused on ImageNet1k as the in-distribution (ID) dataset and a subset of ImageNet21k as the out-of-distribution (OOD) dataset.To address this, we proposed a hybrid approach, experimenting with the fusion of various post-hoc OOD detection techniques and different Test-Time Augmentation (TTA) strategies. Additionally, we evaluated the impact of several base models on the final performance. Our best-performing method combined Test-Time Augmentation with the post-hoc OOD techniques, achieving a strong balance between AUROC and FPR95 scores. Our approach resulted in AUROC: 79.77 (ranked 5th) and FPR95: 61.44 (ranked 2nd), securing second place in the overall competition.
The Solution for Language-Enhanced Image New Category Discovery
Jul 06, 2024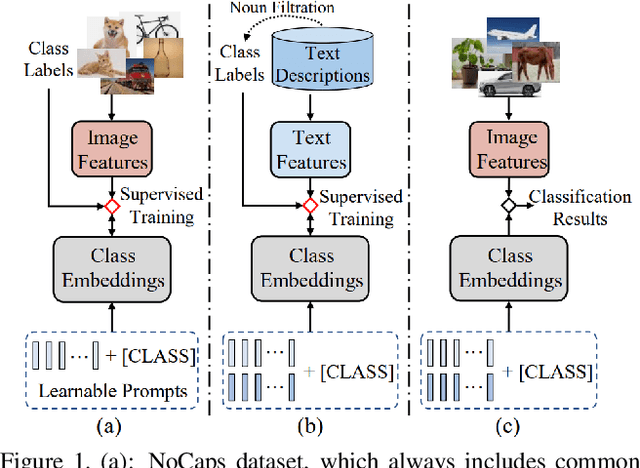
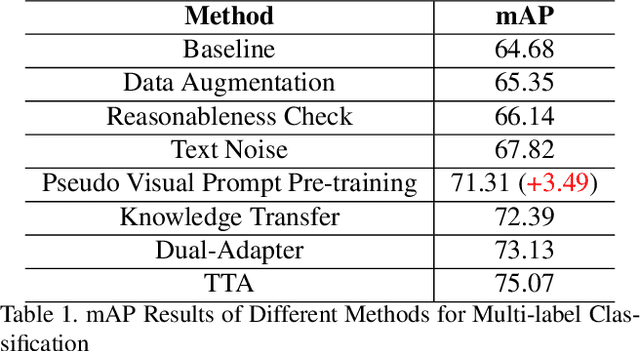
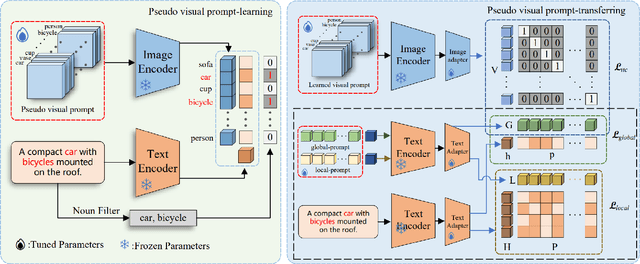
Treating texts as images, combining prompts with textual labels for prompt tuning, and leveraging the alignment properties of CLIP have been successfully applied in zero-shot multi-label image recognition. Nonetheless, relying solely on textual labels to store visual information is insufficient for representing the diversity of visual objects. In this paper, we propose reversing the training process of CLIP and introducing the concept of Pseudo Visual Prompts. These prompts are initialized for each object category and pre-trained on large-scale, low-cost sentence data generated by large language models. This process mines the aligned visual information in CLIP and stores it in class-specific visual prompts. We then employ contrastive learning to transfer the stored visual information to the textual labels, enhancing their visual representation capacity. Additionally, we introduce a dual-adapter module that simultaneously leverages knowledge from the original CLIP and new learning knowledge derived from downstream datasets. Benefiting from the pseudo visual prompts, our method surpasses the state-of-the-art not only on clean annotated text data but also on pseudo text data generated by large language models.
The Solution for the ICCV 2023 Perception Test Challenge 2023 -- Task 6 -- Grounded videoQA
Jul 02, 2024



In this paper, we introduce a grounded video question-answering solution. Our research reveals that the fixed official baseline method for video question answering involves two main steps: visual grounding and object tracking. However, a significant challenge emerges during the initial step, where selected frames may lack clearly identifiable target objects. Furthermore, single images cannot address questions like "Track the container from which the person pours the first time." To tackle this issue, we propose an alternative two-stage approach:(1) First, we leverage the VALOR model to answer questions based on video information.(2) concatenate the answered questions with their respective answers. Finally, we employ TubeDETR to generate bounding boxes for the targets.
High-Resolution Image Translation Model Based on Grayscale Redefinition
Apr 01, 2024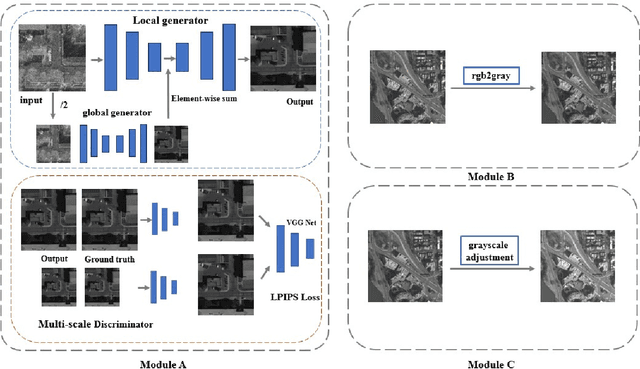
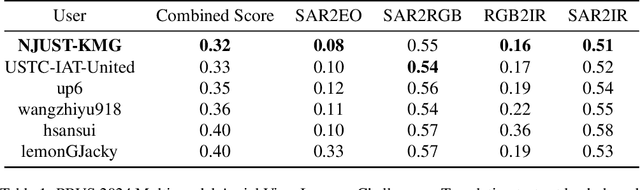

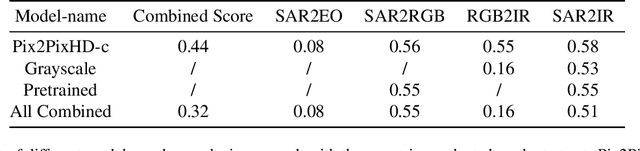
Image-to-image translation is a technique that focuses on transferring images from one domain to another while maintaining the essential content representations. In recent years, image-to-image translation has gained significant attention and achieved remarkable advancements due to its diverse applications in computer vision and image processing tasks. In this work, we propose an innovative method for image translation between different domains. For high-resolution image translation tasks, we use a grayscale adjustment method to achieve pixel-level translation. For other tasks, we utilize the Pix2PixHD model with a coarse-to-fine generator, multi-scale discriminator, and improved loss to enhance the image translation performance. On the other hand, to tackle the issue of sparse training data, we adopt model weight initialization from other task to optimize the performance of the current task.
The Solution for the ICCV 2023 1st Scientific Figure Captioning Challenge
Mar 26, 2024



In this paper, we propose a solution for improving the quality of captions generated for figures in papers. We adopt the approach of summarizing the textual content in the paper to generate image captions. Throughout our study, we encounter discrepancies in the OCR information provided in the official dataset. To rectify this, we employ the PaddleOCR toolkit to extract OCR information from all images. Moreover, we observe that certain textual content in the official paper pertains to images that are not relevant for captioning, thereby introducing noise during caption generation. To mitigate this issue, we leverage LLaMA to extract image-specific information by querying the textual content based on image mentions, effectively filtering out extraneous information. Additionally, we recognize a discrepancy between the primary use of maximum likelihood estimation during text generation and the evaluation metrics such as ROUGE employed to assess the quality of generated captions. To bridge this gap, we integrate the BRIO model framework, enabling a more coherent alignment between the generation and evaluation processes. Our approach ranked first in the final test with a score of 4.49.