 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible 3D Lane Detection by Hierarchical Shape MatchingFlexible 3D Lane Detection by Hierarchical Shape Matching
Aug 13, 2024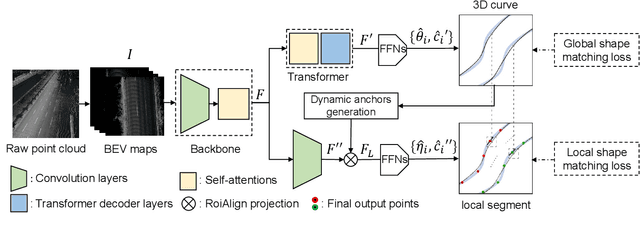
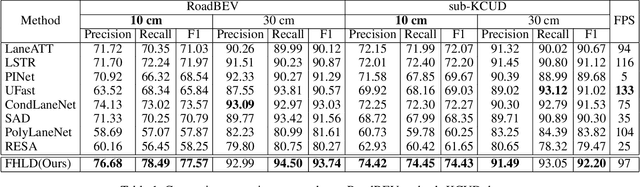
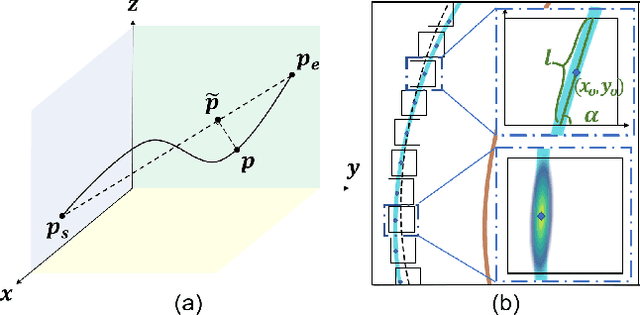
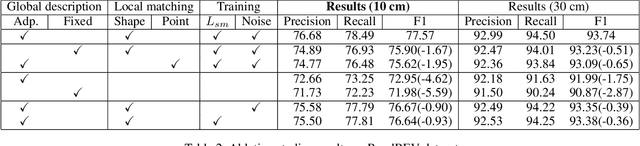
As one of the basic while vital technologies for HD map construction, 3D lane detection is still an open problem due to varying visual conditions, complex typologies, and strict demands for precision. In this paper, an end-to-end flexible and hierarchical lane detector is proposed to precisely predict 3D lane lines from point clouds. Specifically, we design a hierarchical network predicting flexible representations of lane shapes at different levels, simultaneously collecting global instance semantics and avoiding local errors. In the global scope, we propose to regress parametric curves w.r.t adaptive axes that help to make more robust predictions towards complex scenes, while in the local vision the structure of lane segment is detected in each of the dynamic anchor cells sampled along the global predicted curves. Moreover, corresponding global and local shape matching losses and anchor cell generation strategies are designed. Experiments on two datasets show that we overwhelm current top methods under high precision standards, and full ablation studies also verify each part of our method. Our codes will be released at https://github.com/Doo-do/FHLD.
The Solution for the 5th GCAIAC Zero-shot Referring Expression Comprehension Challenge
Jul 06, 2024This report presents a solution for the zero-shot referring expression comprehension task. Visual-language multimodal base models (such as CLIP, SAM) have gained significant attention in recent years as a cornerstone of mainstream research. One of the key applications of multimodal base models lies in their ability to generalize to zero-shot downstream tasks. Unlike traditional referring expression comprehension, zero-shot referring expression comprehension aims to apply pre-trained visual-language models directly to the task without specific training. Recent studies have enhanced the zero-shot performance of multimodal base models in referring expression comprehension tasks by introducing visual prompts. To address the zero-shot referring expression comprehension challenge, we introduced a combination of visual prompts and considered the influence of textual prompts, employing joint prediction tailored to the data characteristics. Ultimately, our approach achieved accuracy rates of 84.825 on the A leaderboard and 71.460 on the B leaderboard, securing the first position.
The Solution for the ICCV 2023 Perception Test Challenge 2023 -- Task 6 -- Grounded videoQA
Jul 02, 2024



In this paper, we introduce a grounded video question-answering solution. Our research reveals that the fixed official baseline method for video question answering involves two main steps: visual grounding and object tracking. However, a significant challenge emerges during the initial step, where selected frames may lack clearly identifiable target objects. Furthermore, single images cannot address questions like "Track the container from which the person pours the first time." To tackle this issue, we propose an alternative two-stage approach:(1) First, we leverage the VALOR model to answer questions based on video information.(2) concatenate the answered questions with their respective answers. Finally, we employ TubeDETR to generate bounding boxes for the targets.
JobFormer: Skill-Aware Job Recommendation with Semantic-Enhanced Transformer
Apr 05, 2024Job recommendation aims to provide potential talents with suitable job descriptions (JDs) consistent with their career trajectory, which plays an essential role in proactive talent recruitment. In real-world management scenarios, the available JD-user records always consist of JDs, user profiles, and click data, in which the user profiles are typically summarized as the user's skill distribution for privacy reasons. Although existing sophisticated recommendation methods can be directly employed, effective recommendation still has challenges considering the information deficit of JD itself and the natural heterogeneous gap between JD and user profile. To address these challenges, we proposed a novel skill-aware recommendation model based on the designed semantic-enhanced transformer to parse JDs and complete personalized job recommendation. Specifically, we first model the relative items of each JD and then adopt an encoder with the local-global attention mechanism to better mine the intra-job and inter-job dependencies from JD tuples. Moreover, we adopt a two-stage learning strategy for skill-aware recommendation, in which we utilize the skill distribution to guide JD representation learning in the recall stage, and then combine the user profiles for final prediction in the ranking stage. Consequently, we can embed rich contextual semantic representations for learning JDs, while skill-aware recommendation provides effective JD-user joint representation for click-through rate (CTR) prediction. To validate the superior performance of our method for job recommendation, we present a thorough empirical analysis of large-scale real-world and public datasets to demonstrate its effectiveness and interpretability.
The Solution for the CVPR 2023 1st foundation model challenge-Track2
Apr 02, 2024In this paper, we propose a solution for cross-modal transportation retrieval. Due to the cross-domain problem of traffic images, we divide the problem into two sub-tasks of pedestrian retrieval and vehicle retrieval through a simple strategy. In pedestrian retrieval tasks, we use IRRA as the base model and specifically design an Attribute Classification to mine the knowledge implied by attribute labels. More importantly, We use the strategy of Inclusion Relation Matching to make the image-text pairs with inclusion relation have similar representation in the feature space. For the vehicle retrieval task, we use BLIP as the base model. Since aligning the color attributes of vehicles is challenging, we introduce attribute-based object detection techniques to add color patch blocks to vehicle images for color data augmentation. This serves as strong prior information, helping the model perform the image-text alignment. At the same time, we incorporate labeled attributes into the image-text alignment loss to learn fine-grained alignment and prevent similar images and texts from being incorrectly separated. Our approach ranked first in the final B-board test with a score of 70.9.