 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Solution for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition
Jul 06, 2024
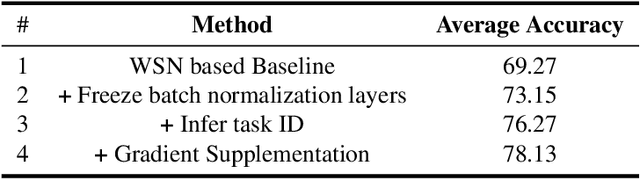
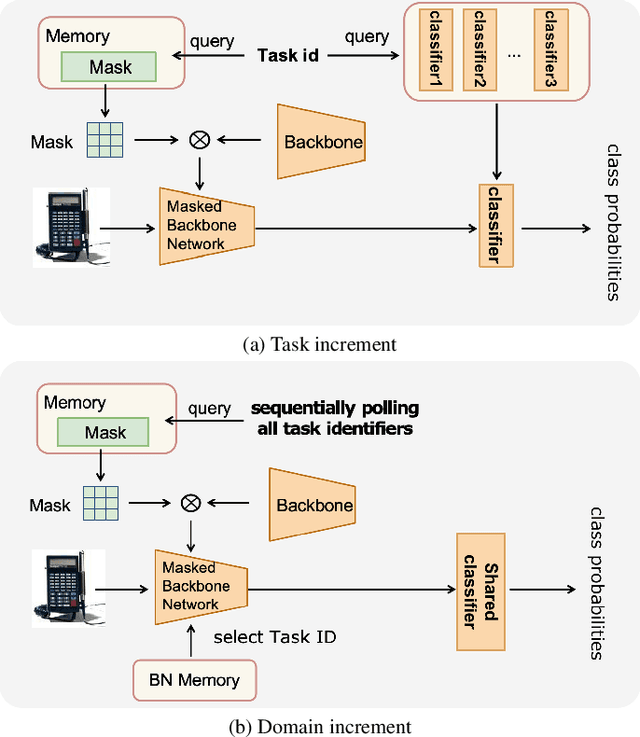
This paper presents a data-free, parameter-isolation-based continual learning algorithm we developed for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition. The method learns an independent parameter subspace for each task within the network's convolutional and linear layers and freezes the batch normalization layers after the first task. Specifically, for domain incremental setting where all domains share a classification head, we freeze the shared classification head after first task is completed, effectively solving the issue of catastrophic forgetting. Additionally, facing the challenge of domain incremental settings without providing a task identity, we designed an inference task identity strategy, selecting an appropriate mask matrix for each sample. Furthermore, we introduced a gradient supplementation strategy to enhance the importance of unselected parameters for the current task, facilitating learning for new tasks. We also implemented an adaptive importance scoring strategy that dynamically adjusts the amount of parameters to optimize single-task performance while reducing parameter usage. Moreover, considering the limitations of storage space and inference time, we designed a mask matrix compression strategy to save storage space and improve the speed of encryption and decryption of the mask matrix. Our approach does not require expanding the core network or using external auxiliary networks or data, and performs well under both task incremental and domain incremental settings. This solution ultimately won a second-place prize in the competition.
The Solution for the AIGC Inference Performance Optimization Competition
Jul 06, 2024In recent years, the rapid advancement of large-scale pre-trained language models based on transformer architectures has revolutionized natural language processing tasks. Among these, ChatGPT has gained widespread popularity, demonstrating human-level conversational abilities and attracting over 100 million monthly users by late 2022. Concurrently, Baidu's commercial deployment of the Ernie Wenxin model has significantly enhanced marketing effectiveness through AI-driven technologies. This paper focuses on optimizing high-performance inference for Ernie models, emphasizing GPU acceleration and leveraging the Paddle inference framework. We employ techniques such as Faster Transformer for efficient model processing, embedding layer pruning to reduce computational overhead, and FP16 half-precision inference for enhanced computational efficiency. Additionally, our approach integrates efficient data handling strategies using multi-process parallel processing to minimize latency. Experimental results demonstrate that our optimized solution achieves up to an 8.96x improvement in inference speed compared to standard methods, while maintaining competitive performance.
The Championship-Winning Solution for the 5th CLVISION Challenge 2024
Jun 24, 2024



In this paper, we introduce our approach to the 5th CLVision Challenge, which presents distinctive challenges beyond traditional class incremental learning. Unlike standard settings, this competition features the recurrence of previously encountered classes and includes unlabeled data that may contain Out-of-Distribution (OOD) categories. Our approach is based on Winning Subnetworks to allocate independent parameter spaces for each task addressing the catastrophic forgetting problem in class incremental learning and employ three training strategies: supervised classification learning, unsupervised contrastive learning, and pseudo-label classification learning to fully utilize the information in both labeled and unlabeled data, enhancing the classification performance of each subnetwork. Furthermore, during the inference stage, we have devised an interaction strategy between subnetworks, where the prediction for a specific class of a particular sample is the average logits across different subnetworks corresponding to that class, leveraging the knowledge learned from different subnetworks on recurring classes to improve classification accuracy. These strategies can be simultaneously applied to the three scenarios of the competition, effectively solving the difficulties in the competition scenarios. Experimentally, our method ranks first in both the pre-selection and final evaluation stages, with an average accuracy of 0.4535 during the preselection stage and an average accuracy of 0.4805 during the final evaluation stage.
The Solution for the CVPR 2023 1st foundation model challenge-Track2
Apr 02, 2024In this paper, we propose a solution for cross-modal transportation retrieval. Due to the cross-domain problem of traffic images, we divide the problem into two sub-tasks of pedestrian retrieval and vehicle retrieval through a simple strategy. In pedestrian retrieval tasks, we use IRRA as the base model and specifically design an Attribute Classification to mine the knowledge implied by attribute labels. More importantly, We use the strategy of Inclusion Relation Matching to make the image-text pairs with inclusion relation have similar representation in the feature space. For the vehicle retrieval task, we use BLIP as the base model. Since aligning the color attributes of vehicles is challenging, we introduce attribute-based object detection techniques to add color patch blocks to vehicle images for color data augmentation. This serves as strong prior information, helping the model perform the image-text alignment. At the same time, we incorporate labeled attributes into the image-text alignment loss to learn fine-grained alignment and prevent similar images and texts from being incorrectly separated. Our approach ranked first in the final B-board test with a score of 70.9.