 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving VQA Reliability: A Dual-Assessment Approach with Self-Reflection and Cross-Model Verification
Dec 16, 2025Vision-language models (VLMs) have demonstrated significant potential in Visual Question Answering (VQA). However, the susceptibility of VLMs to hallucinations can lead to overconfident yet incorrect answers, severely undermining answer reliability. To address this, we propose Dual-Assessment for VLM Reliability (DAVR), a novel framework that integrates Self-Reflection and Cross-Model Verification for comprehensive uncertainty estimation. The DAVR framework features a dual-pathway architecture: one pathway leverages dual selector modules to assess response reliability by fusing VLM latent features with QA embeddings, while the other deploys external reference models for factual cross-checking to mitigate hallucinations. Evaluated in the Reliable VQA Challenge at ICCV-CLVL 2025, DAVR achieves a leading $Φ_{100}$ score of 39.64 and a 100-AUC of 97.22, securing first place and demonstrating its effectiveness in enhancing the trustworthiness of VLM responses.
The Solution for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition
Jul 06, 2024
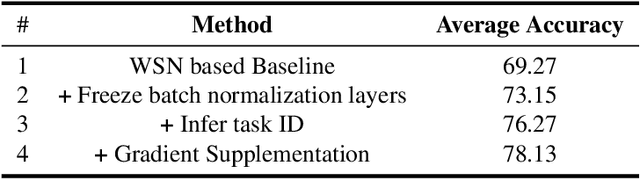
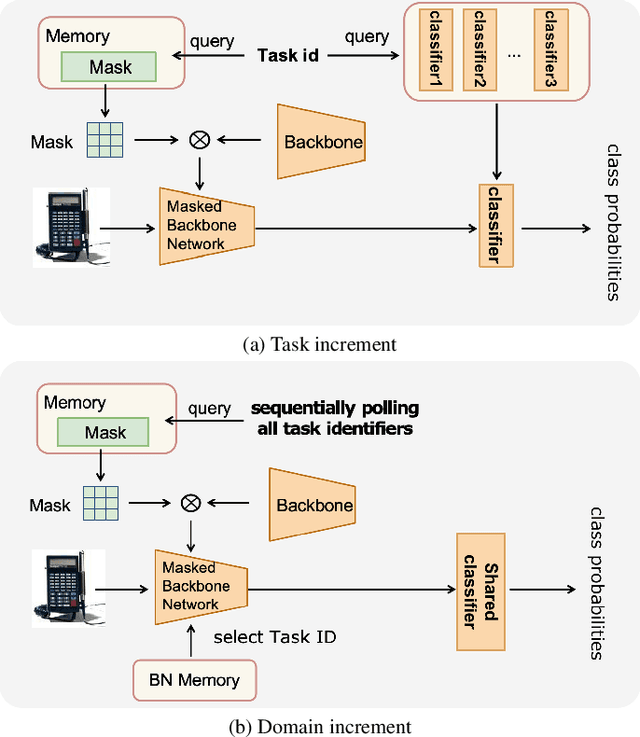
This paper presents a data-free, parameter-isolation-based continual learning algorithm we developed for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition. The method learns an independent parameter subspace for each task within the network's convolutional and linear layers and freezes the batch normalization layers after the first task. Specifically, for domain incremental setting where all domains share a classification head, we freeze the shared classification head after first task is completed, effectively solving the issue of catastrophic forgetting. Additionally, facing the challenge of domain incremental settings without providing a task identity, we designed an inference task identity strategy, selecting an appropriate mask matrix for each sample. Furthermore, we introduced a gradient supplementation strategy to enhance the importance of unselected parameters for the current task, facilitating learning for new tasks. We also implemented an adaptive importance scoring strategy that dynamically adjusts the amount of parameters to optimize single-task performance while reducing parameter usage. Moreover, considering the limitations of storage space and inference time, we designed a mask matrix compression strategy to save storage space and improve the speed of encryption and decryption of the mask matrix. Our approach does not require expanding the core network or using external auxiliary networks or data, and performs well under both task incremental and domain incremental settings. This solution ultimately won a second-place prize in the competition.
High-Resolution Image Translation Model Based on Grayscale Redefinition
Apr 01, 2024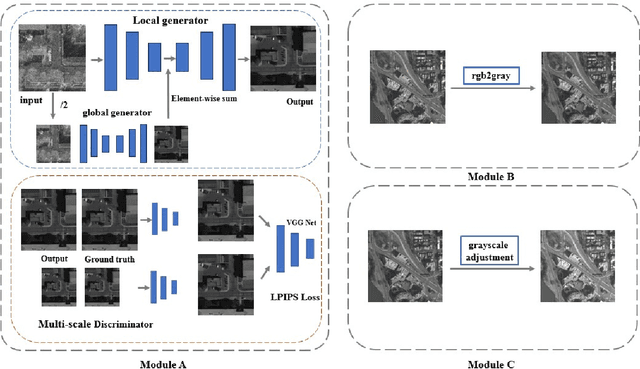

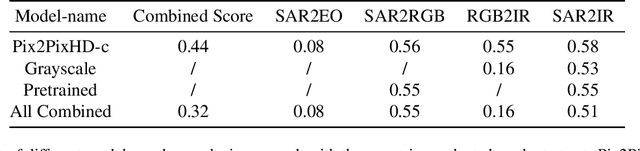
Image-to-image translation is a technique that focuses on transferring images from one domain to another while maintaining the essential content representations. In recent years, image-to-image translation has gained significant attention and achieved remarkable advancements due to its diverse applications in computer vision and image processing tasks. In this work, we propose an innovative method for image translation between different domains. For high-resolution image translation tasks, we use a grayscale adjustment method to achieve pixel-level translation. For other tasks, we utilize the Pix2PixHD model with a coarse-to-fine generator, multi-scale discriminator, and improved loss to enhance the image translation performance. On the other hand, to tackle the issue of sparse training data, we adopt model weight initialization from other task to optimize the performance of the current task.