 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonized Tabular-Image Fusion via Gradient-Aligned Alternating Learning
Apr 02, 2026Multimodal tabular-image fusion is an emerging task that has received increasing attention in various domains. However, existing methods may be hindered by gradient conflicts between modalities, misleading the optimization of the unimodal learner. In this paper, we propose a novel Gradient-Aligned Alternating Learning (GAAL) paradigm to address this issue by aligning modality gradients. Specifically, GAAL adopts an alternating unimodal learning and shared classifier to decouple the multimodal gradient and facilitate interaction. Furthermore, we design uncertainty-based cross-modal gradient surgery to selectively align cross-modal gradients, thereby steering the shared parameters to benefit all modalities. As a result, GAAL can provide effective unimodal assistance and help boost the overall fusion performance. Empirical experiments on widely used datasets reveal the superiority of our method through comparison with various state-of-the-art (SoTA) tabular-image fusion baselines and test-time tabular missing baselines. The source code is available at https://github.com/njustkmg/ICME26-GAAL.
Rethinking Multimodal Learning from the Perspective of Mitigating Classification Ability Disproportion
Feb 27, 2025



Although multimodal learning~(MML) has garnered remarkable progress, the existence of modality imbalance hinders multimodal learning from achieving its expected superiority over unimodal models in practice. To overcome this issue, mainstream multimodal learning methods have placed greater emphasis on balancing the learning process. However, these approaches do not explicitly enhance the classification ability of weaker modalities, leading to limited performance promotion. By designing a sustained boosting algorithm, we propose a novel multimodal learning approach to dynamically balance the classification ability of weak and strong modalities. Concretely, we first propose a sustained boosting algorithm in multimodal learning by simultaneously optimizing the classification and residual errors using a designed configurable classifier module. Then, we propose an adaptive classifier assignment strategy to dynamically facilitate the classification performance of weak modality. To this end, the classification ability of strong and weak modalities is expected to be balanced, thereby mitigating the imbalance issue. Empirical experiments on widely used datasets reveal the superiority of our method through comparison with various state-of-the-art~(SoTA) multimodal learning baselines.
The Solution for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition
Jul 06, 2024
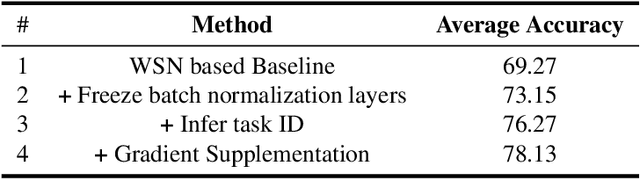
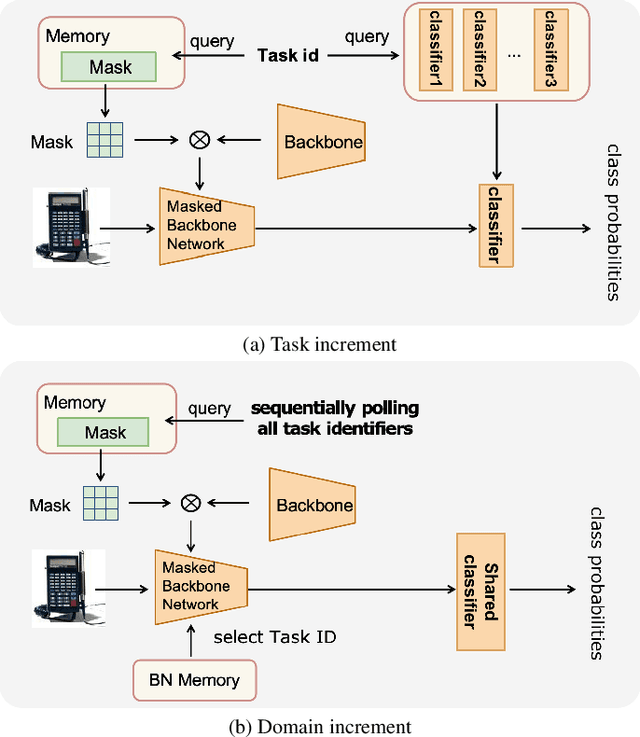
This paper presents a data-free, parameter-isolation-based continual learning algorithm we developed for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition. The method learns an independent parameter subspace for each task within the network's convolutional and linear layers and freezes the batch normalization layers after the first task. Specifically, for domain incremental setting where all domains share a classification head, we freeze the shared classification head after first task is completed, effectively solving the issue of catastrophic forgetting. Additionally, facing the challenge of domain incremental settings without providing a task identity, we designed an inference task identity strategy, selecting an appropriate mask matrix for each sample. Furthermore, we introduced a gradient supplementation strategy to enhance the importance of unselected parameters for the current task, facilitating learning for new tasks. We also implemented an adaptive importance scoring strategy that dynamically adjusts the amount of parameters to optimize single-task performance while reducing parameter usage. Moreover, considering the limitations of storage space and inference time, we designed a mask matrix compression strategy to save storage space and improve the speed of encryption and decryption of the mask matrix. Our approach does not require expanding the core network or using external auxiliary networks or data, and performs well under both task incremental and domain incremental settings. This solution ultimately won a second-place prize in the competition.
The Solution for the 5th GCAIAC Zero-shot Referring Expression Comprehension Challenge
Jul 06, 2024This report presents a solution for the zero-shot referring expression comprehension task. Visual-language multimodal base models (such as CLIP, SAM) have gained significant attention in recent years as a cornerstone of mainstream research. One of the key applications of multimodal base models lies in their ability to generalize to zero-shot downstream tasks. Unlike traditional referring expression comprehension, zero-shot referring expression comprehension aims to apply pre-trained visual-language models directly to the task without specific training. Recent studies have enhanced the zero-shot performance of multimodal base models in referring expression comprehension tasks by introducing visual prompts. To address the zero-shot referring expression comprehension challenge, we introduced a combination of visual prompts and considered the influence of textual prompts, employing joint prediction tailored to the data characteristics. Ultimately, our approach achieved accuracy rates of 84.825 on the A leaderboard and 71.460 on the B leaderboard, securing the first position.
The Solution for the GAIIC2024 RGB-TIR object detection Challenge
Jul 04, 2024This report introduces a solution to The task of RGB-TIR object detection from the perspective of unmanned aerial vehicles. Unlike traditional object detection methods, RGB-TIR object detection aims to utilize both RGB and TIR images for complementary information during detection. The challenges of RGB-TIR object detection from the perspective of unmanned aerial vehicles include highly complex image backgrounds, frequent changes in lighting, and uncalibrated RGB-TIR image pairs. To address these challenges at the model level, we utilized a lightweight YOLOv9 model with extended multi-level auxiliary branches that enhance the model's robustness, making it more suitable for practical applications in unmanned aerial vehicle scenarios. For image fusion in RGB-TIR detection, we incorporated a fusion module into the backbone network to fuse images at the feature level, implicitly addressing calibration issues. Our proposed method achieved an mAP score of 0.516 and 0.543 on A and B benchmarks respectively while maintaining the highest inference speed among all models.
The Solution for the CVPR2024 NICE Image Captioning Challenge
Apr 19, 2024This report introduces a solution to the Topic 1 Zero-shot Image Captioning of 2024 NICE : New frontiers for zero-shot Image Captioning Evaluation. In contrast to NICE 2023 datasets, this challenge involves new annotations by humans with significant differences in caption style and content. Therefore, we enhance image captions effectively through retrieval augmentation and caption grading methods. At the data level, we utilize high-quality captions generated by image caption models as training data to address the gap in text styles. At the model level, we employ OFA (a large-scale visual-language pre-training model based on handcrafted templates) to perform the image captioning task. Subsequently, we propose caption-level strategy for the high-quality caption data generated by the image caption models and integrate them with retrieval augmentation strategy into the template to compel the model to generate higher quality, more matching, and semantically enriched captions based on the retrieval augmentation prompts. Our approach ranks first on the leaderboard, achieving a CIDEr score of 234.11 and 1st in all other metrics.