 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTG-LLaVA: Text Guided LLaVA via Learnable Latent Embeddings
Sep 15, 2024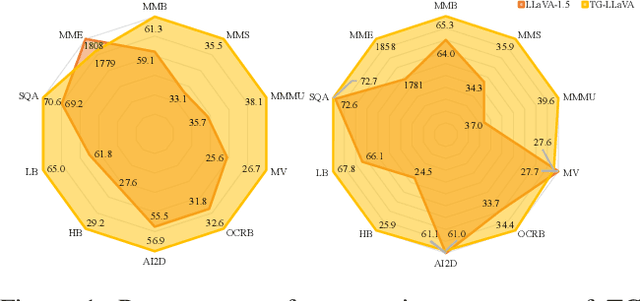
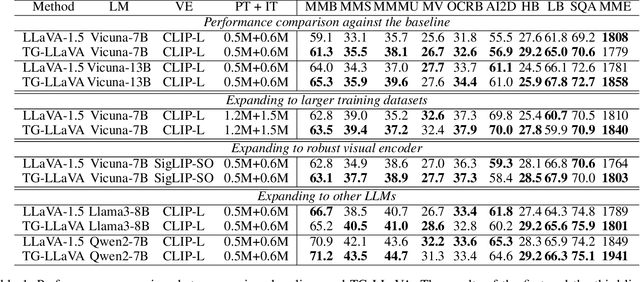
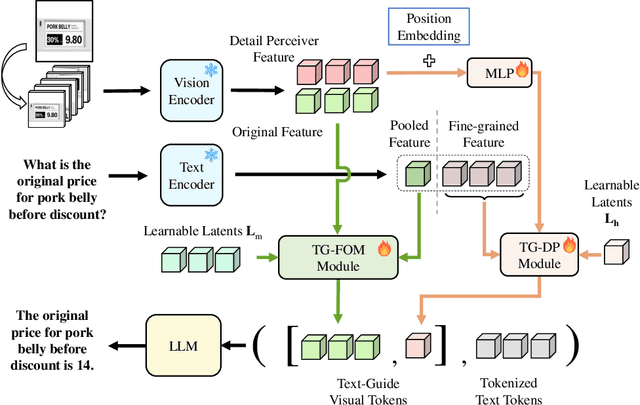

Currently, inspired by the success of vision-language models (VLMs), an increasing number of researchers are focusing on improving VLMs and have achieved promising results. However, most existing methods concentrate on optimizing the connector and enhancing the language model component, while neglecting improvements to the vision encoder itself. In contrast, we propose Text Guided LLaVA (TG-LLaVA) in this paper, which optimizes VLMs by guiding the vision encoder with text, offering a new and orthogonal optimization direction. Specifically, inspired by the purpose-driven logic inherent in human behavior, we use learnable latent embeddings as a bridge to analyze textual instruction and add the analysis results to the vision encoder as guidance, refining it. Subsequently, another set of latent embeddings extracts additional detailed text-guided information from high-resolution local patches as auxiliary information. Finally, with the guidance of text, the vision encoder can extract text-related features, similar to how humans focus on the most relevant parts of an image when considering a question. This results in generating better answers. Experiments on various datasets validate the effectiveness of the proposed method. Remarkably, without the need for additional training data, our propsoed method can bring more benefits to the baseline (LLaVA-1.5) compared with other concurrent methods. Furthermore, the proposed method consistently brings improvement in different settings.
BooW-VTON: Boosting In-the-Wild Virtual Try-On via Mask-Free Pseudo Data Training
Aug 12, 2024

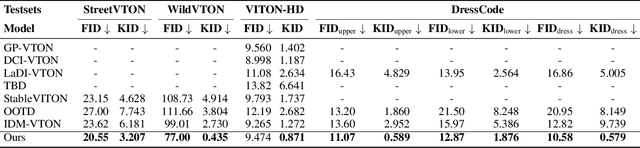
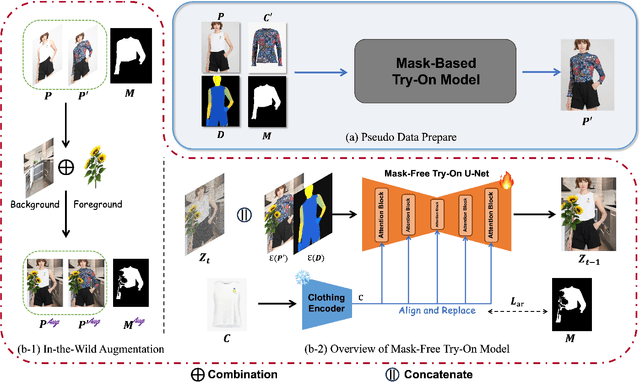
Image-based virtual try-on is an increasingly popular and important task to generate realistic try-on images of specific person. Existing methods always employ an accurate mask to remove the original garment in the source image, thus achieving realistic synthesized images in simple and conventional try-on scenarios based on powerful diffusion model. Therefore, acquiring suitable mask is vital to the try-on performance of these methods. However, obtaining precise inpainting masks, especially for complex wild try-on data containing diverse foreground occlusions and person poses, is not easy as Figure 1-Top shows. This difficulty often results in poor performance in more practical and challenging real-life scenarios, such as the selfie scene shown in Figure 1-Bottom. To this end, we propose a novel training paradigm combined with an efficient data augmentation method to acquire large-scale unpaired training data from wild scenarios, thereby significantly facilitating the try-on performance of our model without the need for additional inpainting masks. Besides, a try-on localization loss is designed to localize a more accurate try-on area to obtain more reasonable try-on results. It is noted that our method only needs the reference cloth image, source pose image and source person image as input, which is more cost-effective and user-friendly compared to existing methods. Extensive qualitative and quantitative experiments have demonstrated superior performance in wild scenarios with such a low-demand input.
The Solution for Temporal Sound Localisation Task of ICCV 1st Perception Test Challenge 2023
Jul 01, 2024

In this paper, we propose a solution for improving the quality of temporal sound localization. We employ a multimodal fusion approach to combine visual and audio features. High-quality visual features are extracted using a state-of-the-art self-supervised pre-training network, resulting in efficient video feature representations. At the same time, audio features serve as complementary information to help the model better localize the start and end of sounds. The fused features are trained in a multi-scale Transformer for training. In the final test dataset, we achieved a mean average precision (mAP) of 0.33, obtaining the second-best performance in this track.
The Solution for the CVPR2024 NICE Image Captioning Challenge
Apr 19, 2024This report introduces a solution to the Topic 1 Zero-shot Image Captioning of 2024 NICE : New frontiers for zero-shot Image Captioning Evaluation. In contrast to NICE 2023 datasets, this challenge involves new annotations by humans with significant differences in caption style and content. Therefore, we enhance image captions effectively through retrieval augmentation and caption grading methods. At the data level, we utilize high-quality captions generated by image caption models as training data to address the gap in text styles. At the model level, we employ OFA (a large-scale visual-language pre-training model based on handcrafted templates) to perform the image captioning task. Subsequently, we propose caption-level strategy for the high-quality caption data generated by the image caption models and integrate them with retrieval augmentation strategy into the template to compel the model to generate higher quality, more matching, and semantically enriched captions based on the retrieval augmentation prompts. Our approach ranks first on the leaderboard, achieving a CIDEr score of 234.11 and 1st in all other metrics.
Better Fit: Accommodate Variations in Clothing Types for Virtual Try-on
Mar 13, 2024

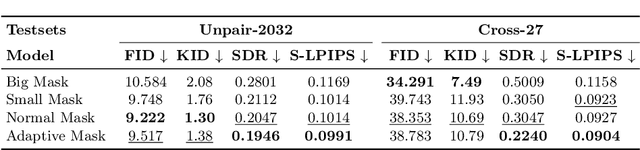
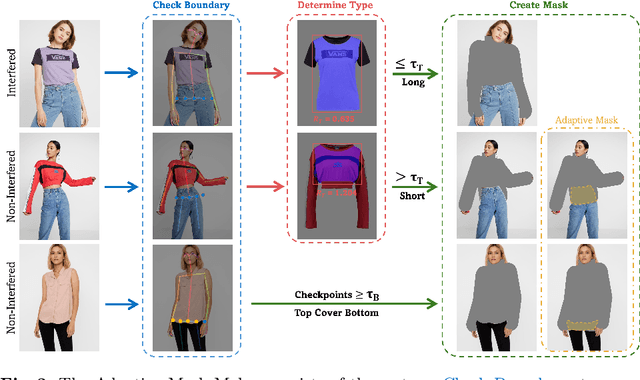
Image-based virtual try-on aims to transfer target in-shop clothing to a dressed model image, the objectives of which are totally taking off original clothing while preserving the contents outside of the try-on area, naturally wearing target clothing and correctly inpainting the gap between target clothing and original clothing. Tremendous efforts have been made to facilitate this popular research area, but cannot keep the type of target clothing with the try-on area affected by original clothing. In this paper, we focus on the unpaired virtual try-on situation where target clothing and original clothing on the model are different, i.e., the practical scenario. To break the correlation between the try-on area and the original clothing and make the model learn the correct information to inpaint, we propose an adaptive mask training paradigm that dynamically adjusts training masks. It not only improves the alignment and fit of clothing but also significantly enhances the fidelity of virtual try-on experience. Furthermore, we for the first time propose two metrics for unpaired try-on evaluation, the Semantic-Densepose-Ratio (SDR) and Skeleton-LPIPS (S-LPIPS), to evaluate the correctness of clothing type and the accuracy of clothing texture. For unpaired try-on validation, we construct a comprehensive cross-try-on benchmark (Cross-27) with distinctive clothing items and model physiques, covering a broad try-on scenarios. Experiments demonstrate the effectiveness of the proposed methods, contributing to the advancement of virtual try-on technology and offering new insights and tools for future research in the field. The code, model and benchmark will be publicly released.
Solution for SMART-101 Challenge of ICCV Multi-modal Algorithmic Reasoning Task 2023
Oct 10, 2023



In this paper, we present our solution to a Multi-modal Algorithmic Reasoning Task: SMART-101 Challenge. Different from the traditional visual question-answering datasets, this challenge evaluates the abstraction, deduction, and generalization abilities of neural networks in solving visuolinguistic puzzles designed specifically for children in the 6-8 age group. We employed a divide-and-conquer approach. At the data level, inspired by the challenge paper, we categorized the whole questions into eight types and utilized the llama-2-chat model to directly generate the type for each question in a zero-shot manner. Additionally, we trained a yolov7 model on the icon45 dataset for object detection and combined it with the OCR method to recognize and locate objects and text within the images. At the model level, we utilized the BLIP-2 model and added eight adapters to the image encoder VIT-G to adaptively extract visual features for different question types. We fed the pre-constructed question templates as input and generated answers using the flan-t5-xxl decoder. Under the puzzle splits configuration, we achieved an accuracy score of 26.5 on the validation set and 24.30 on the private test set.