 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEMF-VVTO: Point-Enhanced Video Virtual Try-on via Mask-free Paradigm
Dec 05, 2024



Video Virtual Try-on aims to fluently transfer the garment image to a semantically aligned try-on area in the source person video. Previous methods leveraged the inpainting mask to remove the original garment in the source video, thus achieving accurate garment transfer on simple model videos. However, when these methods are applied to realistic video data with more complex scene changes and posture movements, the overly large and incoherent agnostic masks will destroy the essential spatial-temporal information of the original video, thereby inhibiting the fidelity and coherence of the try-on video. To alleviate this problem, we propose a novel point-enhanced mask-free video virtual try-on framework (PEMF-VVTO). Specifically, we first leverage the pre-trained mask-based try-on model to construct large-scale paired training data (pseudo-person samples). Training on these mask-free data enables our model to perceive the original spatial-temporal information while realizing accurate garment transfer. Then, based on the pre-acquired sparse frame-cloth and frame-frame point alignments, we design the point-enhanced spatial attention (PSA) and point-enhanced temporal attention (PTA) to further improve the try-on accuracy and video coherence of the mask-free model. Concretely, PSA explicitly guides the garment transfer to desirable locations through the sparse semantic alignments of video frames and cloth. PTA exploits the temporal attention on sparse point correspondences to enhance the smoothness of generated videos. Extensive qualitative and quantitative experiments clearly illustrate that our PEMF-VVTO can generate more natural and coherent try-on videos than existing state-of-the-art methods.
Deep Self-cleansing for Medical Image Segmentation with Noisy Labels
Sep 08, 2024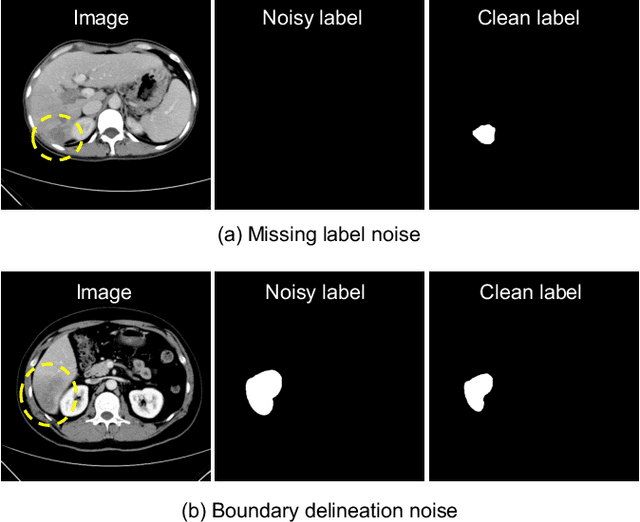
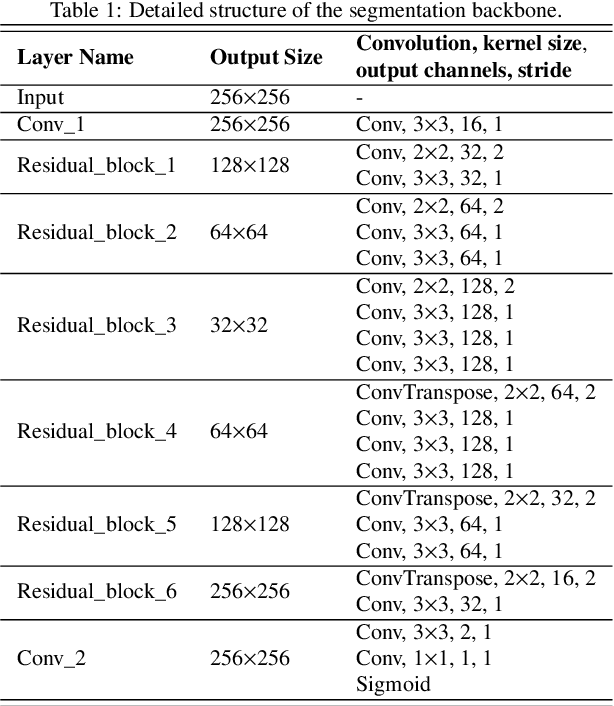
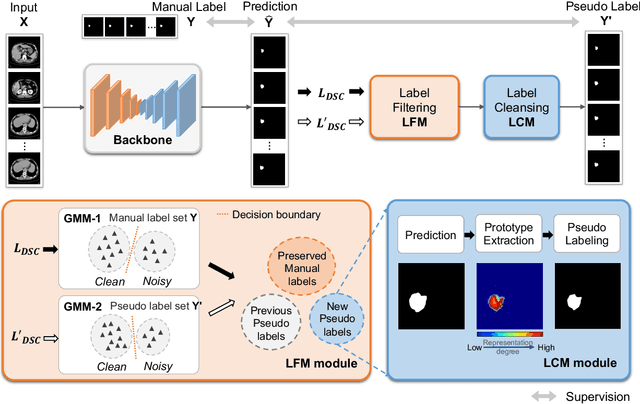
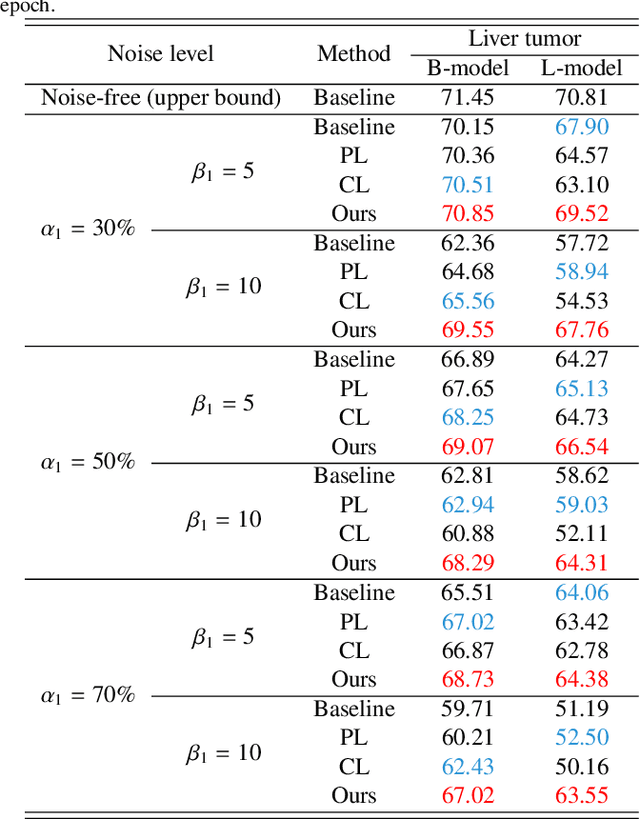
Medical image segmentation is crucial in the field of medical imaging, aiding in disease diagnosis and surgical planning. Most established segmentation methods rely on supervised deep learning, in which clean and precise labels are essential for supervision and significantly impact the performance of models. However, manually delineated labels often contain noise, such as missing labels and inaccurate boundary delineation, which can hinder networks from correctly modeling target characteristics. In this paper, we propose a deep self-cleansing segmentation framework that can preserve clean labels while cleansing noisy ones in the training phase. To achieve this, we devise a gaussian mixture model-based label filtering module that distinguishes noisy labels from clean labels. Additionally, we develop a label cleansing module to generate pseudo low-noise labels for identified noisy samples. The preserved clean labels and pseudo-labels are then used jointly to supervise the network. Validated on a clinical liver tumor dataset and a public cardiac diagnosis dataset, our method can effectively suppress the interference from noisy labels and achieve prominent segmentation performance.
BooW-VTON: Boosting In-the-Wild Virtual Try-On via Mask-Free Pseudo Data Training
Aug 12, 2024

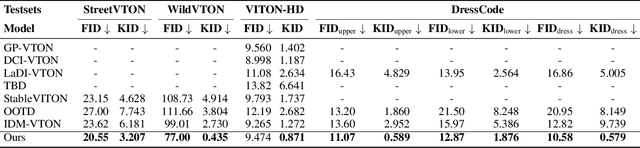
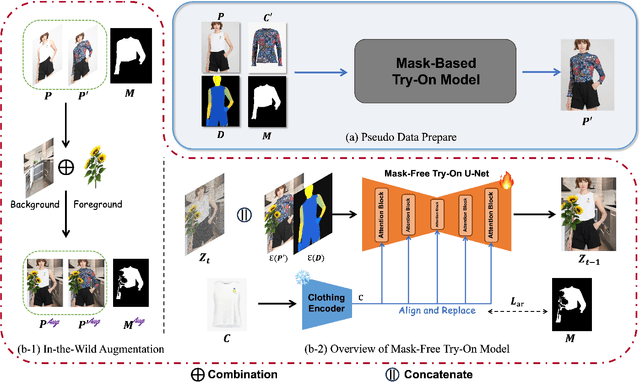
Image-based virtual try-on is an increasingly popular and important task to generate realistic try-on images of specific person. Existing methods always employ an accurate mask to remove the original garment in the source image, thus achieving realistic synthesized images in simple and conventional try-on scenarios based on powerful diffusion model. Therefore, acquiring suitable mask is vital to the try-on performance of these methods. However, obtaining precise inpainting masks, especially for complex wild try-on data containing diverse foreground occlusions and person poses, is not easy as Figure 1-Top shows. This difficulty often results in poor performance in more practical and challenging real-life scenarios, such as the selfie scene shown in Figure 1-Bottom. To this end, we propose a novel training paradigm combined with an efficient data augmentation method to acquire large-scale unpaired training data from wild scenarios, thereby significantly facilitating the try-on performance of our model without the need for additional inpainting masks. Besides, a try-on localization loss is designed to localize a more accurate try-on area to obtain more reasonable try-on results. It is noted that our method only needs the reference cloth image, source pose image and source person image as input, which is more cost-effective and user-friendly compared to existing methods. Extensive qualitative and quantitative experiments have demonstrated superior performance in wild scenarios with such a low-demand input.
Better Fit: Accommodate Variations in Clothing Types for Virtual Try-on
Mar 13, 2024

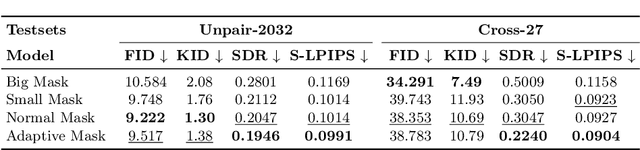
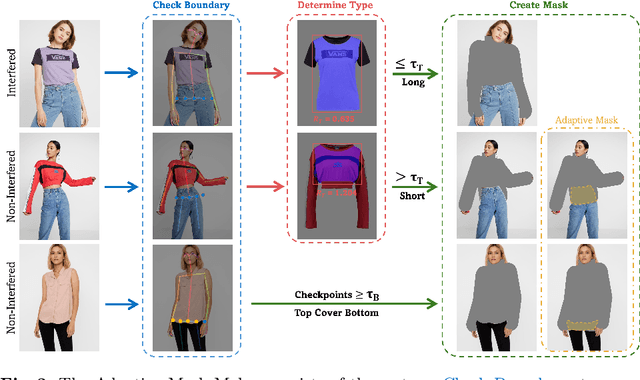
Image-based virtual try-on aims to transfer target in-shop clothing to a dressed model image, the objectives of which are totally taking off original clothing while preserving the contents outside of the try-on area, naturally wearing target clothing and correctly inpainting the gap between target clothing and original clothing. Tremendous efforts have been made to facilitate this popular research area, but cannot keep the type of target clothing with the try-on area affected by original clothing. In this paper, we focus on the unpaired virtual try-on situation where target clothing and original clothing on the model are different, i.e., the practical scenario. To break the correlation between the try-on area and the original clothing and make the model learn the correct information to inpaint, we propose an adaptive mask training paradigm that dynamically adjusts training masks. It not only improves the alignment and fit of clothing but also significantly enhances the fidelity of virtual try-on experience. Furthermore, we for the first time propose two metrics for unpaired try-on evaluation, the Semantic-Densepose-Ratio (SDR) and Skeleton-LPIPS (S-LPIPS), to evaluate the correctness of clothing type and the accuracy of clothing texture. For unpaired try-on validation, we construct a comprehensive cross-try-on benchmark (Cross-27) with distinctive clothing items and model physiques, covering a broad try-on scenarios. Experiments demonstrate the effectiveness of the proposed methods, contributing to the advancement of virtual try-on technology and offering new insights and tools for future research in the field. The code, model and benchmark will be publicly released.
Image-Based Virtual Try-On: A Survey
Nov 08, 2023Image-based virtual try-on aims to synthesize a naturally dressed person image with a clothing image, which revolutionizes online shopping and inspires related topics within image generation, showing both research significance and commercial potentials. However, there is a great gap between current research progress and commercial applications and an absence of comprehensive overview towards this field to accelerate the development. In this survey, we provide a comprehensive analysis of the state-of-the-art techniques and methodologies in aspects of pipeline architecture, person representation and key modules such as try-on indication, clothing warping and try-on stage. We propose a new semantic criteria with CLIP, and evaluate representative methods with uniformly implemented evaluation metrics on the same dataset. In addition to quantitative and qualitative evaluation of current open-source methods, we also utilize ControlNet to fine-tune a recent large image generation model (PBE) to show future potentials of large-scale models on image-based virtual try-on task. Finally, unresolved issues are revealed and future research directions are prospected to identify key trends and inspire further exploration. The uniformly implemented evaluation metrics, dataset and collected methods will be made public available at https://github.com/little-misfit/Survey-Of-Virtual-Try-On.