 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLCAD: Reinforcement Learning Training Gym for Revolution Involved CAD Command Sequence Generation
Mar 24, 2025A CAD command sequence is a typical parametric design paradigm in 3D CAD systems where a model is constructed by overlaying 2D sketches with operations such as extrusion, revolution, and Boolean operations. Although there is growing academic interest in the automatic generation of command sequences, existing methods and datasets only support operations such as 2D sketching, extrusion,and Boolean operations. This limitation makes it challenging to represent more complex geometries. In this paper, we present a reinforcement learning (RL) training environment (gym) built on a CAD geometric engine. Given an input boundary representation (B-Rep) geometry, the policy network in the RL algorithm generates an action. This action, along with previously generated actions, is processed within the gym to produce the corresponding CAD geometry, which is then fed back into the policy network. The rewards, determined by the difference between the generated and target geometries within the gym, are used to update the RL network. Our method supports operations beyond sketches, Boolean, and extrusion, including revolution operations. With this training gym, we achieve state-of-the-art (SOTA) quality in generating command sequences from B-Rep geometries. In addition, our method can significantly improve the efficiency of command sequence generation by a factor of 39X compared with the previous training gym.
Deep Self-cleansing for Medical Image Segmentation with Noisy Labels
Sep 08, 2024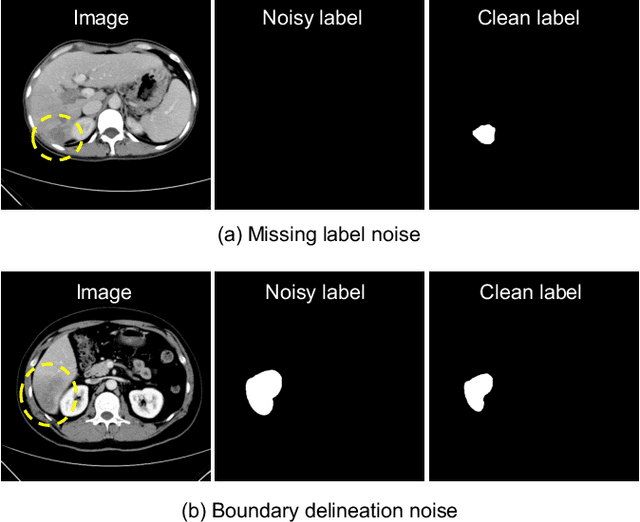
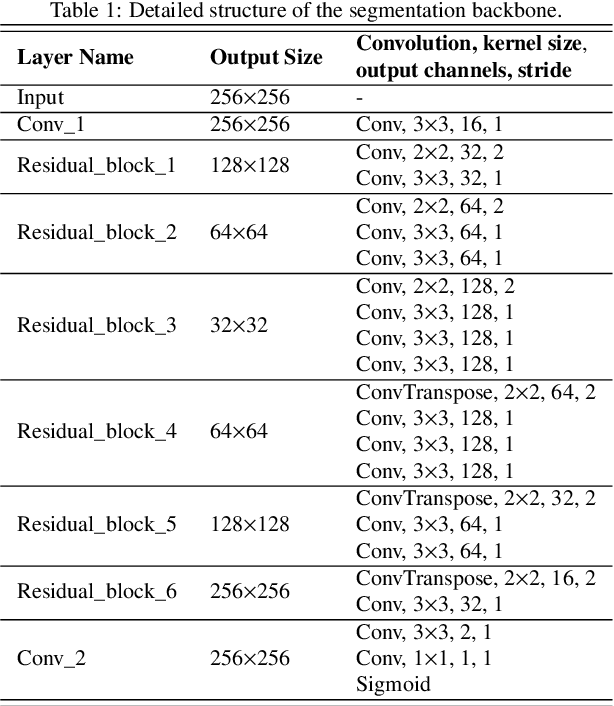
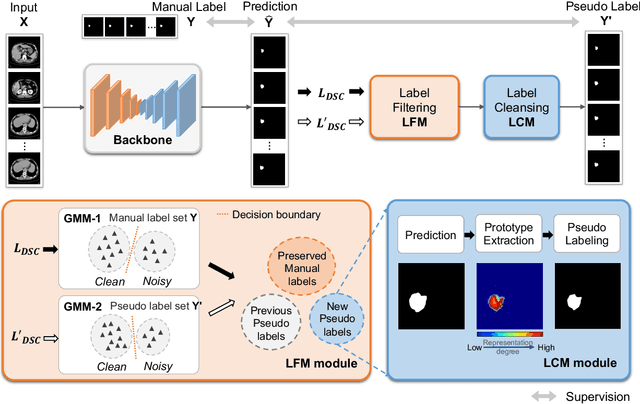
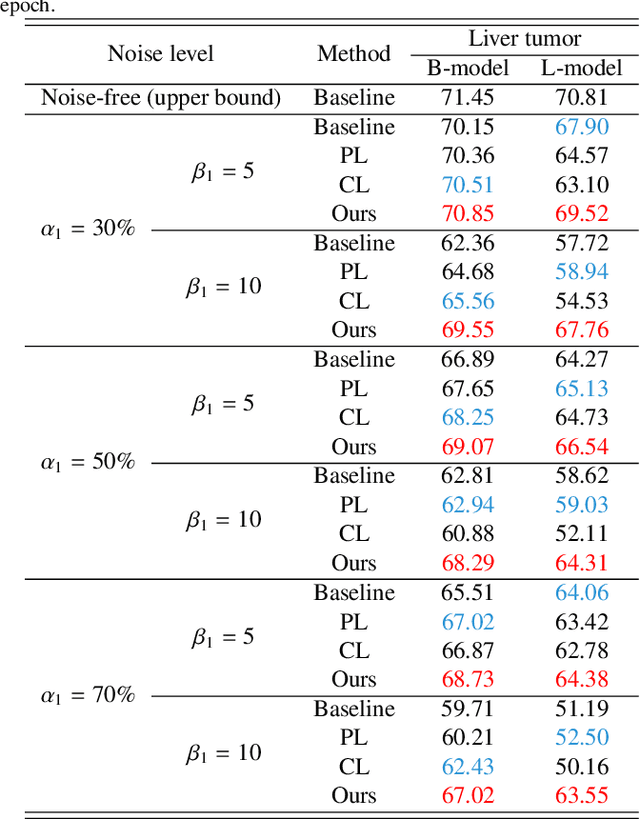
Medical image segmentation is crucial in the field of medical imaging, aiding in disease diagnosis and surgical planning. Most established segmentation methods rely on supervised deep learning, in which clean and precise labels are essential for supervision and significantly impact the performance of models. However, manually delineated labels often contain noise, such as missing labels and inaccurate boundary delineation, which can hinder networks from correctly modeling target characteristics. In this paper, we propose a deep self-cleansing segmentation framework that can preserve clean labels while cleansing noisy ones in the training phase. To achieve this, we devise a gaussian mixture model-based label filtering module that distinguishes noisy labels from clean labels. Additionally, we develop a label cleansing module to generate pseudo low-noise labels for identified noisy samples. The preserved clean labels and pseudo-labels are then used jointly to supervise the network. Validated on a clinical liver tumor dataset and a public cardiac diagnosis dataset, our method can effectively suppress the interference from noisy labels and achieve prominent segmentation performance.
HSVLT: Hierarchical Scale-Aware Vision-Language Transformer for Multi-Label Image Classification
Jul 23, 2024
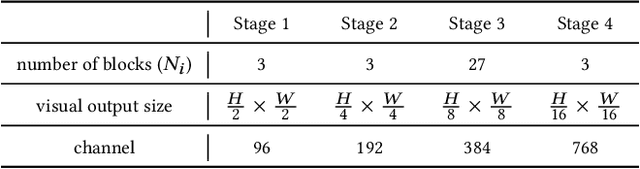
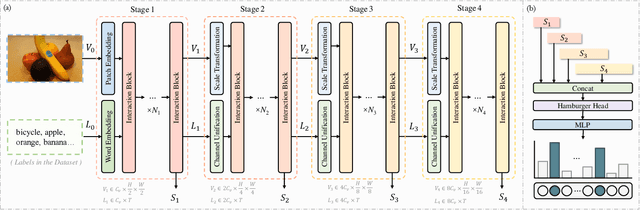
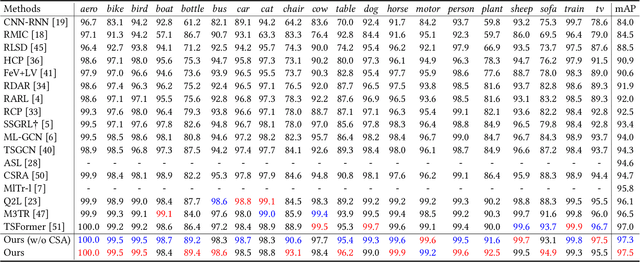
The task of multi-label image classification involves recognizing multiple objects within a single image. Considering both valuable semantic information contained in the labels and essential visual features presented in the image, tight visual-linguistic interactions play a vital role in improving classification performance. Moreover, given the potential variance in object size and appearance within a single image, attention to features of different scales can help to discover possible objects in the image. Recently, Transformer-based methods have achieved great success in multi-label image classification by leveraging the advantage of modeling long-range dependencies, but they have several limitations. Firstly, existing methods treat visual feature extraction and cross-modal fusion as separate steps, resulting in insufficient visual-linguistic alignment in the joint semantic space. Additionally, they only extract visual features and perform cross-modal fusion at a single scale, neglecting objects with different characteristics. To address these issues, we propose a Hierarchical Scale-Aware Vision-Language Transformer (HSVLT) with two appealing designs: (1)~A hierarchical multi-scale architecture that involves a Cross-Scale Aggregation module, which leverages joint multi-modal features extracted from multiple scales to recognize objects of varying sizes and appearances in images. (2)~Interactive Visual-Linguistic Attention, a novel attention mechanism module that tightly integrates cross-modal interaction, enabling the joint updating of visual, linguistic and multi-modal features. We have evaluated our method on three benchmark datasets. The experimental results demonstrate that HSVLT surpasses state-of-the-art methods with lower computational cost.
* 10 pages, 6 figures
Rethinking Multiple Instance Learning for Whole Slide Image Classification: A Bag-Level Classifier is a Good Instance-Level Teacher
Dec 02, 2023Multiple Instance Learning (MIL) has demonstrated promise in Whole Slide Image (WSI) classification. However, a major challenge persists due to the high computational cost associated with processing these gigapixel images. Existing methods generally adopt a two-stage approach, comprising a non-learnable feature embedding stage and a classifier training stage. Though it can greatly reduce the memory consumption by using a fixed feature embedder pre-trained on other domains, such scheme also results in a disparity between the two stages, leading to suboptimal classification accuracy. To address this issue, we propose that a bag-level classifier can be a good instance-level teacher. Based on this idea, we design Iteratively Coupled Multiple Instance Learning (ICMIL) to couple the embedder and the bag classifier at a low cost. ICMIL initially fix the patch embedder to train the bag classifier, followed by fixing the bag classifier to fine-tune the patch embedder. The refined embedder can then generate better representations in return, leading to a more accurate classifier for the next iteration. To realize more flexible and more effective embedder fine-tuning, we also introduce a teacher-student framework to efficiently distill the category knowledge in the bag classifier to help the instance-level embedder fine-tuning. Thorough experiments were conducted on four distinct datasets to validate the effectiveness of ICMIL. The experimental results consistently demonstrate that our method significantly improves the performance of existing MIL backbones, achieving state-of-the-art results. The code is available at: https://github.com/Dootmaan/ICMIL/tree/confidence_based
Image-Based Virtual Try-On: A Survey
Nov 08, 2023Image-based virtual try-on aims to synthesize a naturally dressed person image with a clothing image, which revolutionizes online shopping and inspires related topics within image generation, showing both research significance and commercial potentials. However, there is a great gap between current research progress and commercial applications and an absence of comprehensive overview towards this field to accelerate the development. In this survey, we provide a comprehensive analysis of the state-of-the-art techniques and methodologies in aspects of pipeline architecture, person representation and key modules such as try-on indication, clothing warping and try-on stage. We propose a new semantic criteria with CLIP, and evaluate representative methods with uniformly implemented evaluation metrics on the same dataset. In addition to quantitative and qualitative evaluation of current open-source methods, we also utilize ControlNet to fine-tune a recent large image generation model (PBE) to show future potentials of large-scale models on image-based virtual try-on task. Finally, unresolved issues are revealed and future research directions are prospected to identify key trends and inspire further exploration. The uniformly implemented evaluation metrics, dataset and collected methods will be made public available at https://github.com/little-misfit/Survey-Of-Virtual-Try-On.
CTSN: Predicting Cloth Deformation for Skeleton-based Characters with a Two-stream Skinning Network
May 30, 2023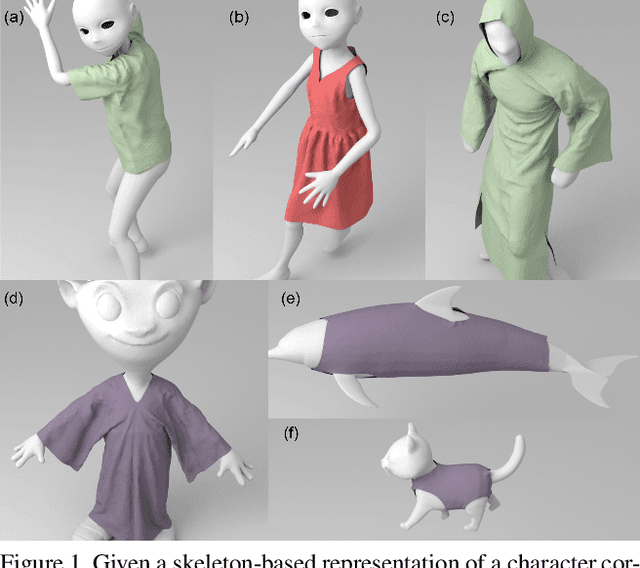

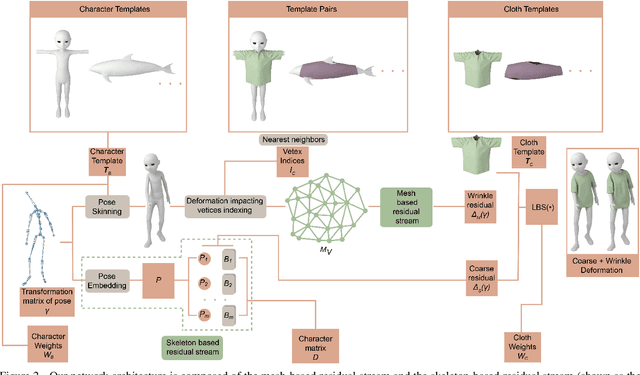
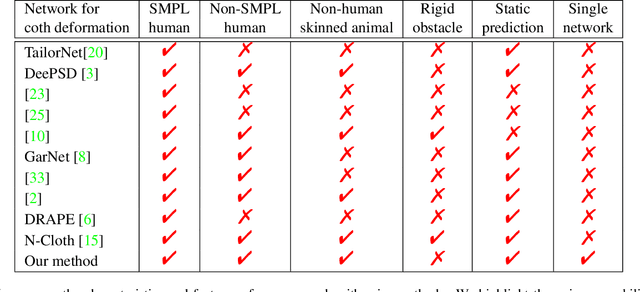
We present a novel learning method to predict the cloth deformation for skeleton-based characters with a two-stream network. The characters processed in our approach are not limited to humans, and can be other skeletal-based representations of non-human targets such as fish or pets. We use a novel network architecture which consists of skeleton-based and mesh-based residual networks to learn the coarse and wrinkle features as the overall residual from the template cloth mesh. Our network is used to predict the deformation for loose or tight-fitting clothing or dresses. We ensure that the memory footprint of our network is low, and thereby result in reduced storage and computational requirements. In practice, our prediction for a single cloth mesh for the skeleton-based character takes about 7 milliseconds on an NVIDIA GeForce RTX 3090 GPU. Compared with prior methods, our network can generate fine deformation results with details and wrinkles.
Tailored Multi-Organ Segmentation with Model Adaptation and Ensemble
Apr 14, 2023



Multi-organ segmentation, which identifies and separates different organs in medical images, is a fundamental task in medical image analysis. Recently, the immense success of deep learning motivated its wide adoption in multi-organ segmentation tasks. However, due to expensive labor costs and expertise, the availability of multi-organ annotations is usually limited and hence poses a challenge in obtaining sufficient training data for deep learning-based methods. In this paper, we aim to address this issue by combining off-the-shelf single-organ segmentation models to develop a multi-organ segmentation model on the target dataset, which helps get rid of the dependence on annotated data for multi-organ segmentation. To this end, we propose a novel dual-stage method that consists of a Model Adaptation stage and a Model Ensemble stage. The first stage enhances the generalization of each off-the-shelf segmentation model on the target domain, while the second stage distills and integrates knowledge from multiple adapted single-organ segmentation models. Extensive experiments on four abdomen datasets demonstrate that our proposed method can effectively leverage off-the-shelf single-organ segmentation models to obtain a tailored model for multi-organ segmentation with high accuracy.
Iteratively Coupled Multiple Instance Learning from Instance to Bag Classifier for Whole Slide Image Classification
Mar 28, 2023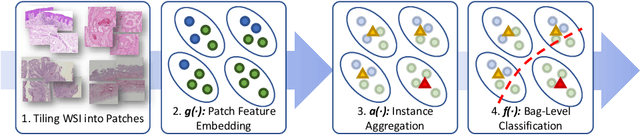

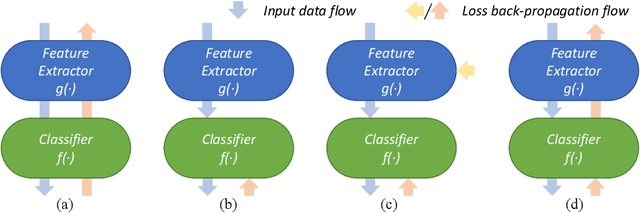
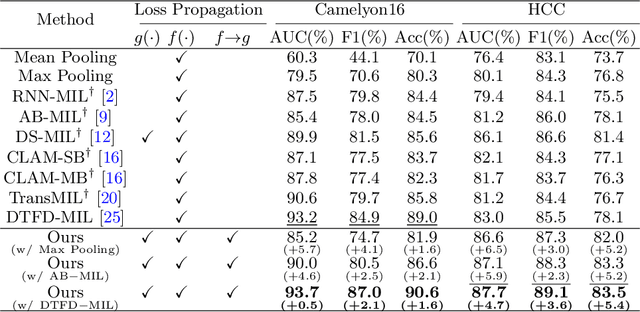
Whole Slide Image (WSI) classification remains a challenge due to their extremely high resolution and the absence of fine-grained labels. Presently, WSIs are usually classified as a Multiple Instance Learning (MIL) problem when only slide-level labels are available. MIL methods involve a patch embedding process and a bag-level classification process, but they are prohibitively expensive to be trained end-to-end. Therefore, existing methods usually train them separately, or directly skip the training of the embedder. Such schemes hinder the patch embedder's access to slide-level labels, resulting in inconsistencies within the entire MIL pipeline. To overcome this issue, we propose a novel framework called Iteratively Coupled MIL (ICMIL), which bridges the loss back-propagation process from the bag-level classifier to the patch embedder. In ICMIL, we use category information in the bag-level classifier to guide the patch-level fine-tuning of the patch feature extractor. The refined embedder then generates better instance representations for achieving a more accurate bag-level classifier. By coupling the patch embedder and bag classifier at a low cost, our proposed framework enables information exchange between the two processes, benefiting the entire MIL classification model. We tested our framework on two datasets using three different backbones, and our experimental results demonstrate consistent performance improvements over state-of-the-art MIL methods. Code will be made available upon acceptance.
Super-Resolution Based Patch-Free 3D Medical Image Segmentation with Self-Supervised Guidance
Oct 26, 2022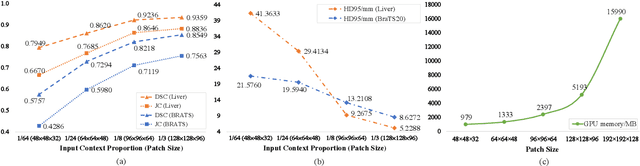
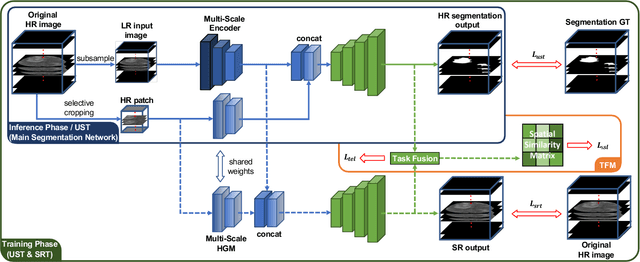
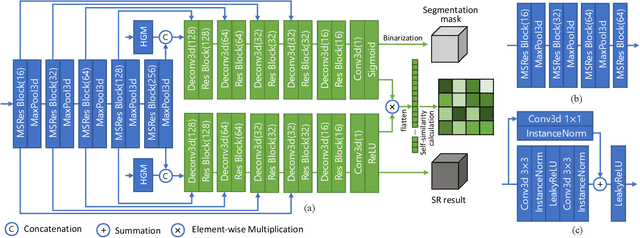
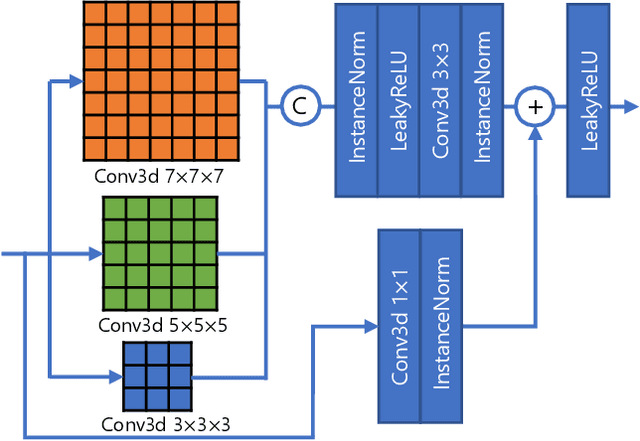
High resolution (HR) 3D medical image segmentation plays an important role in clinical diagnoses. However, HR images are difficult to be directly processed by mainstream graphical cards due to limited video memory. Therefore, most existing 3D medical image segmentation methods use patch-based models, which ignores global context information that is useful in accurate segmentation and has low inference efficiency. To address these problems, we propose a super-resolution (SR) guided patch-free 3D medical image segmentation framework that can realize HR segmentation with global information of low-resolution (LR) input. The framework contains two tasks: semantic segmentation (main task) and super resolution (auxiliary task). To balance the information loss with the LR input, we introduce a Self-Supervised Guidance Module (SGM), which employs a selective search method to crop a HR patch from the original image as restoration guidance. Multi-scale convolutional layers are used to mitigate the scale-inconsistency between the HR guidance features and the LR features. Moreover, we propose a Task-Fusion Module (TFM) to exploit the inter connections between segmentation and SR task. This module can also be used for Test Phase Fine-tuning (TPF), leading to a better model generalization ability. When predicting, only the main segmentation task is needed, while other modules can be removed to accelerate the inference. The experiments results on two different datasets show that our framework outperforms current patch-based and patch-free models. Our model also has a four times higher inference speed compared to traditional patch-based methods. Our codes are available at: https://github.com/Dootmaan/PFSeg-Full.
ScaleFormer: Revisiting the Transformer-based Backbones from a Scale-wise Perspective for Medical Image Segmentation
Jul 29, 2022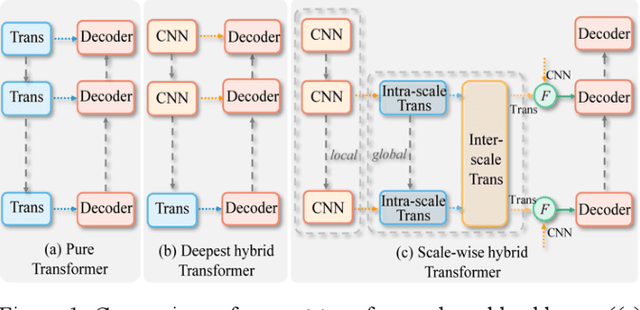
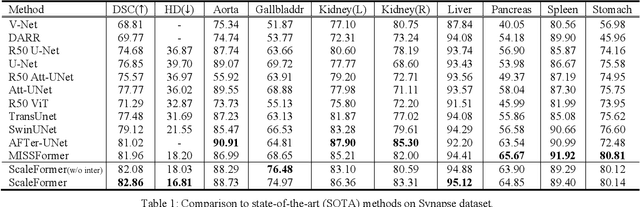

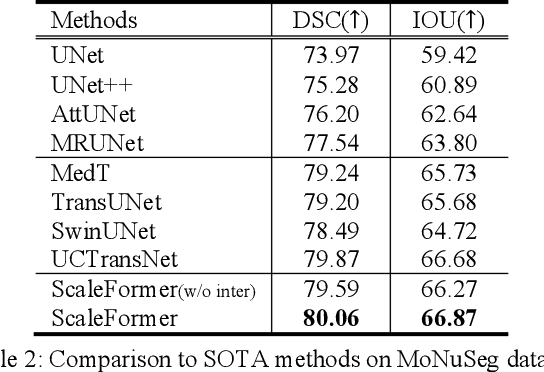
Recently, a variety of vision transformers have been developed as their capability of modeling long-range dependency. In current transformer-based backbones for medical image segmentation, convolutional layers were replaced with pure transformers, or transformers were added to the deepest encoder to learn global context. However, there are mainly two challenges in a scale-wise perspective: (1) intra-scale problem: the existing methods lacked in extracting local-global cues in each scale, which may impact the signal propagation of small objects; (2) inter-scale problem: the existing methods failed to explore distinctive information from multiple scales, which may hinder the representation learning from objects with widely variable size, shape and location. To address these limitations, we propose a novel backbone, namely ScaleFormer, with two appealing designs: (1) A scale-wise intra-scale transformer is designed to couple the CNN-based local features with the transformer-based global cues in each scale, where the row-wise and column-wise global dependencies can be extracted by a lightweight Dual-Axis MSA. (2) A simple and effective spatial-aware inter-scale transformer is designed to interact among consensual regions in multiple scales, which can highlight the cross-scale dependency and resolve the complex scale variations. Experimental results on different benchmarks demonstrate that our Scale-Former outperforms the current state-of-the-art methods. The code is publicly available at: https://github.com/ZJUGiveLab/ScaleFormer.