 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSVLT: Hierarchical Scale-Aware Vision-Language Transformer for Multi-Label Image Classification
Paper and Code
Jul 23, 2024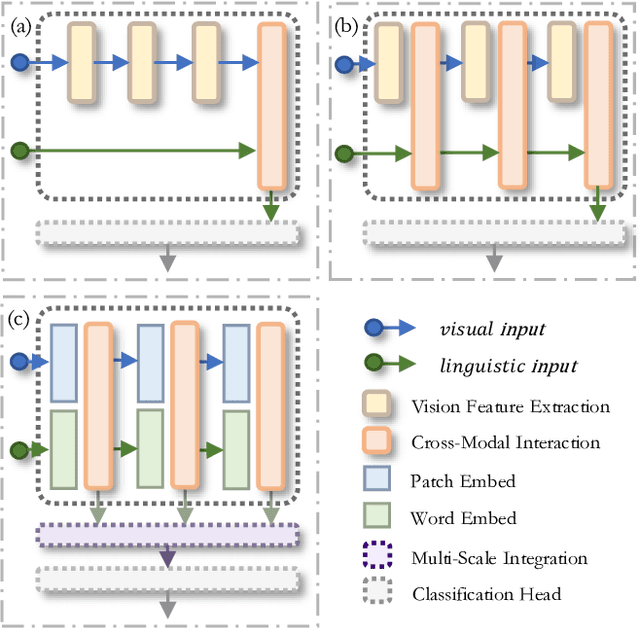
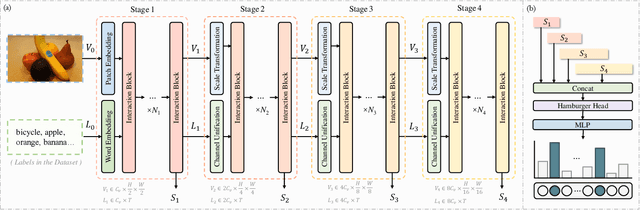
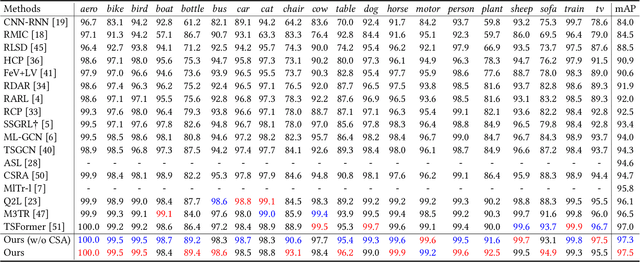
The task of multi-label image classification involves recognizing multiple objects within a single image. Considering both valuable semantic information contained in the labels and essential visual features presented in the image, tight visual-linguistic interactions play a vital role in improving classification performance. Moreover, given the potential variance in object size and appearance within a single image, attention to features of different scales can help to discover possible objects in the image. Recently, Transformer-based methods have achieved great success in multi-label image classification by leveraging the advantage of modeling long-range dependencies, but they have several limitations. Firstly, existing methods treat visual feature extraction and cross-modal fusion as separate steps, resulting in insufficient visual-linguistic alignment in the joint semantic space. Additionally, they only extract visual features and perform cross-modal fusion at a single scale, neglecting objects with different characteristics. To address these issues, we propose a Hierarchical Scale-Aware Vision-Language Transformer (HSVLT) with two appealing designs: (1)~A hierarchical multi-scale architecture that involves a Cross-Scale Aggregation module, which leverages joint multi-modal features extracted from multiple scales to recognize objects of varying sizes and appearances in images. (2)~Interactive Visual-Linguistic Attention, a novel attention mechanism module that tightly integrates cross-modal interaction, enabling the joint updating of visual, linguistic and multi-modal features. We have evaluated our method on three benchmark datasets. The experimental results demonstrate that HSVLT surpasses state-of-the-art methods with lower computational cost.