 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Tracking of Arabidopsis Root Cortex Cell Nuclei in 3D Time-Lapse Microscopy Images Based on Genetic Algorithm
Apr 17, 2025Arabidopsis is a widely used model plant to gain basic knowledge on plant physiology and development. Live imaging is an important technique to visualize and quantify elemental processes in plant development. To uncover novel theories underlying plant growth and cell division, accurate cell tracking on live imaging is of utmost importance. The commonly used cell tracking software, TrackMate, adopts tracking-by-detection fashion, which applies Laplacian of Gaussian (LoG) for blob detection, and Linear Assignment Problem (LAP) tracker for tracking. However, they do not perform sufficiently when cells are densely arranged. To alleviate the problems mentioned above, we propose an accurate tracking method based on Genetic algorithm (GA) using knowledge of Arabidopsis root cellular patterns and spatial relationship among volumes. Our method can be described as a coarse-to-fine method, in which we first conducted relatively easy line-level tracking of cell nuclei, then performed complicated nuclear tracking based on known linear arrangement of cell files and their spatial relationship between nuclei. Our method has been evaluated on a long-time live imaging dataset of Arabidopsis root tips, and with minor manual rectification, it accurately tracks nuclei. To the best of our knowledge, this research represents the first successful attempt to address a long-standing problem in the field of time-lapse microscopy in the root meristem by proposing an accurate tracking method for Arabidopsis root nuclei.
A Circular Construction Product Ontology for End-of-Life Decision-Making
Mar 17, 2025Efficient management of end-of-life (EoL) products is critical for advancing circularity in supply chains, particularly within the construction industry where EoL strategies are hindered by heterogenous lifecycle data and data silos. Current tools like Environmental Product Declarations (EPDs) and Digital Product Passports (DPPs) are limited by their dependency on seamless data integration and interoperability which remain significant challenges. To address these, we present the Circular Construction Product Ontology (CCPO), an applied framework designed to overcome semantic and data heterogeneity challenges in EoL decision-making for construction products. CCPO standardises vocabulary and facilitates data integration across supply chain stakeholders enabling lifecycle assessments (LCA) and robust decision-making. By aggregating disparate data into a unified product provenance, CCPO enables automated EoL recommendations through customisable SWRL rules aligned with European standards and stakeholder-specific circularity SLAs, demonstrating its scalability and integration capabilities. The adopted circular product scenario depicts CCPO's application while competency question evaluations show its superior performance in generating accurate EoL suggestions highlighting its potential to greatly improve decision-making in circular supply chains and its applicability in real-world construction environments.
Cross-modality Attention Adapter: A Glioma Segmentation Fine-tuning Method for SAM Using Multimodal Brain MR Images
Jul 03, 2023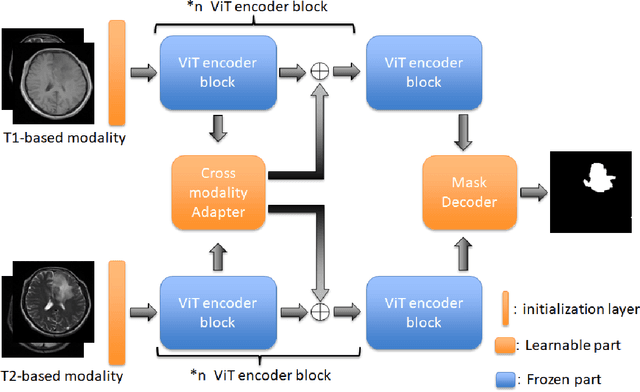
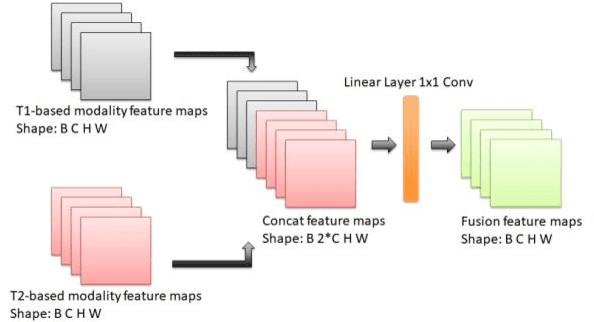

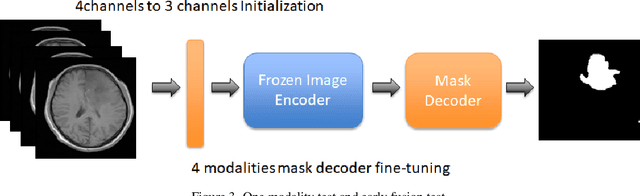
According to the 2021 World Health Organization (WHO) Classification scheme for gliomas, glioma segmentation is a very important basis for diagnosis and genotype prediction. In general, 3D multimodal brain MRI is an effective diagnostic tool. In the past decade, there has been an increase in the use of machine learning, particularly deep learning, for medical images processing. Thanks to the development of foundation models, models pre-trained with large-scale datasets have achieved better results on a variety of tasks. However, for medical images with small dataset sizes, deep learning methods struggle to achieve better results on real-world image datasets. In this paper, we propose a cross-modality attention adapter based on multimodal fusion to fine-tune the foundation model to accomplish the task of glioma segmentation in multimodal MRI brain images with better results. The effectiveness of the proposed method is validated via our private glioma data set from the First Affiliated Hospital of Zhengzhou University (FHZU) in Zhengzhou, China. Our proposed method is superior to current state-of-the-art methods with a Dice of 88.38% and Hausdorff distance of 10.64, thereby exhibiting a 4% increase in Dice to segment the glioma region for glioma treatment.
Ladder Fine-tuning approach for SAM integrating complementary network
Jun 22, 2023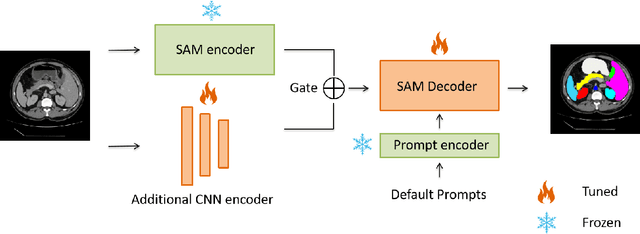
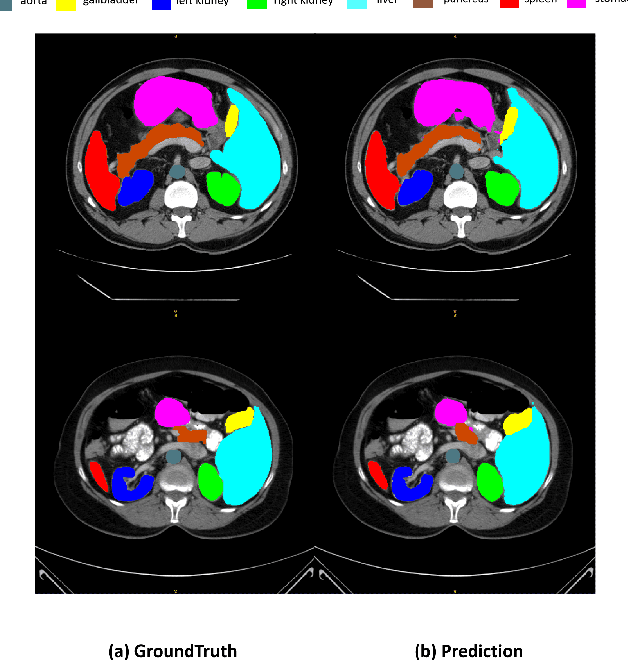
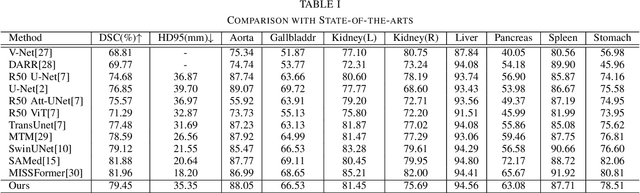

Recently, foundation models have been introduced demonstrating various tasks in the field of computer vision. These models such as Segment Anything Model (SAM) are generalized models trained using huge datasets. Currently, ongoing research focuses on exploring the effective utilization of these generalized models for specific domains, such as medical imaging. However, in medical imaging, the lack of training samples due to privacy concerns and other factors presents a major challenge for applying these generalized models to medical image segmentation task. To address this issue, the effective fine tuning of these models is crucial to ensure their optimal utilization. In this study, we propose to combine a complementary Convolutional Neural Network (CNN) along with the standard SAM network for medical image segmentation. To reduce the burden of fine tuning large foundation model and implement cost-efficient trainnig scheme, we focus only on fine-tuning the additional CNN network and SAM decoder part. This strategy significantly reduces trainnig time and achieves competitive results on publicly available dataset. The code is available at https://github.com/11yxk/SAM-LST.
BEVStereo++: Accurate Depth Estimation in Multi-view 3D Object Detection via Dynamic Temporal Stereo
Apr 09, 2023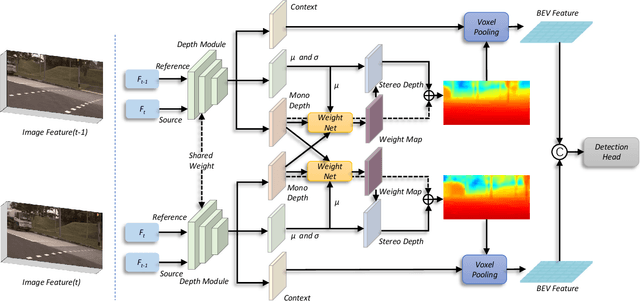

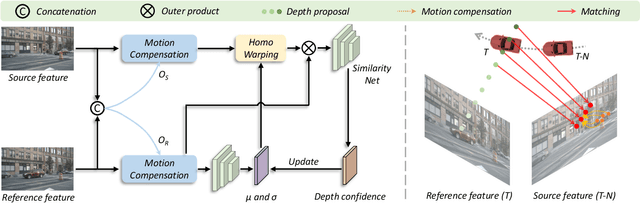
Bounded by the inherent ambiguity of depth perception, contemporary multi-view 3D object detection methods fall into the performance bottleneck. Intuitively, leveraging temporal multi-view stereo (MVS) technology is the natural knowledge for tackling this ambiguity. However, traditional attempts of MVS has two limitations when applying to 3D object detection scenes: 1) The affinity measurement among all views suffers expensive computational cost; 2) It is difficult to deal with outdoor scenarios where objects are often mobile. To this end, we propose BEVStereo++: by introducing a dynamic temporal stereo strategy, BEVStereo++ is able to cut down the harm that is brought by introducing temporal stereo when dealing with those two scenarios. Going one step further, we apply Motion Compensation Module and long sequence Frame Fusion to BEVStereo++, which shows further performance boosting and error reduction. Without bells and whistles, BEVStereo++ achieves state-of-the-art(SOTA) on both Waymo and nuScenes dataset.
Super-Resolution Based Patch-Free 3D Medical Image Segmentation with Self-Supervised Guidance
Oct 26, 2022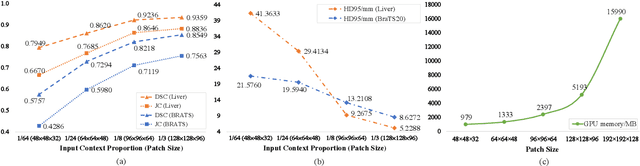
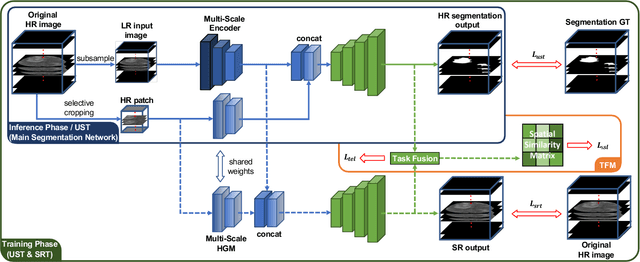
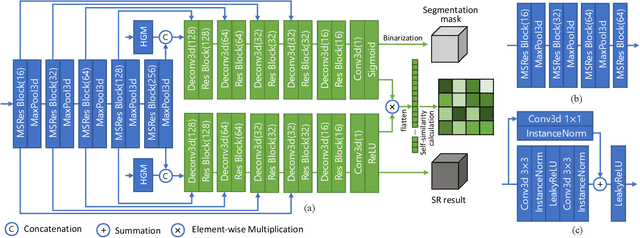
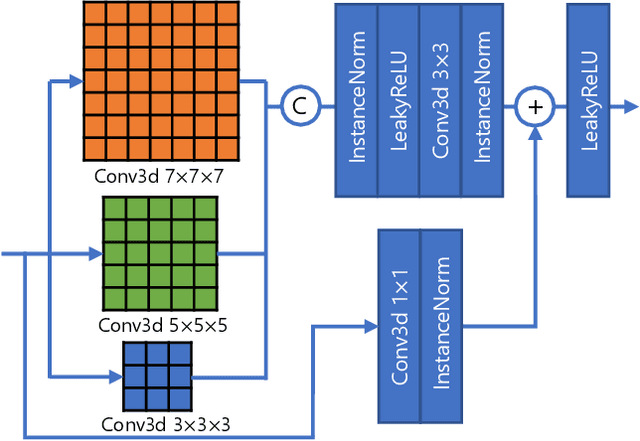
High resolution (HR) 3D medical image segmentation plays an important role in clinical diagnoses. However, HR images are difficult to be directly processed by mainstream graphical cards due to limited video memory. Therefore, most existing 3D medical image segmentation methods use patch-based models, which ignores global context information that is useful in accurate segmentation and has low inference efficiency. To address these problems, we propose a super-resolution (SR) guided patch-free 3D medical image segmentation framework that can realize HR segmentation with global information of low-resolution (LR) input. The framework contains two tasks: semantic segmentation (main task) and super resolution (auxiliary task). To balance the information loss with the LR input, we introduce a Self-Supervised Guidance Module (SGM), which employs a selective search method to crop a HR patch from the original image as restoration guidance. Multi-scale convolutional layers are used to mitigate the scale-inconsistency between the HR guidance features and the LR features. Moreover, we propose a Task-Fusion Module (TFM) to exploit the inter connections between segmentation and SR task. This module can also be used for Test Phase Fine-tuning (TPF), leading to a better model generalization ability. When predicting, only the main segmentation task is needed, while other modules can be removed to accelerate the inference. The experiments results on two different datasets show that our framework outperforms current patch-based and patch-free models. Our model also has a four times higher inference speed compared to traditional patch-based methods. Our codes are available at: https://github.com/Dootmaan/PFSeg-Full.
BEVStereo: Enhancing Depth Estimation in Multi-view 3D Object Detection with Dynamic Temporal Stereo
Sep 21, 2022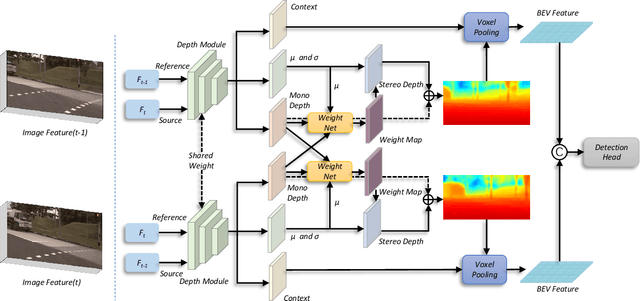



Bounded by the inherent ambiguity of depth perception, contemporary camera-based 3D object detection methods fall into the performance bottleneck. Intuitively, leveraging temporal multi-view stereo (MVS) technology is the natural knowledge for tackling this ambiguity. However, traditional attempts of MVS are flawed in two aspects when applying to 3D object detection scenes: 1) The affinity measurement among all views suffers expensive computation cost; 2) It is difficult to deal with outdoor scenarios where objects are often mobile. To this end, we introduce an effective temporal stereo method to dynamically select the scale of matching candidates, enable to significantly reduce computation overhead. Going one step further, we design an iterative algorithm to update more valuable candidates, making it adaptive to moving candidates. We instantiate our proposed method to multi-view 3D detector, namely BEVStereo. BEVStereo achieves the new state-of-the-art performance (i.e., 52.5% mAP and 61.0% NDS) on the camera-only track of nuScenes dataset. Meanwhile, extensive experiments reflect our method can deal with complex outdoor scenarios better than contemporary MVS approaches. Codes have been released at https://github.com/Megvii-BaseDetection/BEVStereo.
STS: Surround-view Temporal Stereo for Multi-view 3D Detection
Aug 22, 2022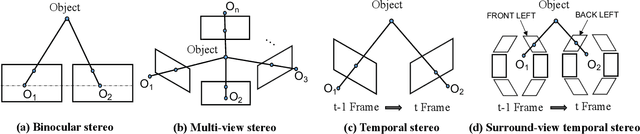
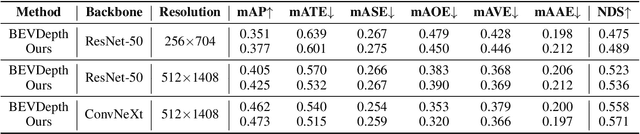
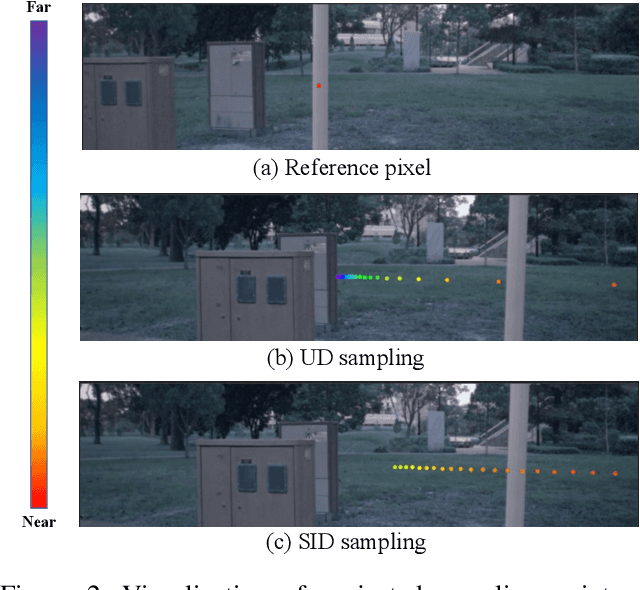
Learning accurate depth is essential to multi-view 3D object detection. Recent approaches mainly learn depth from monocular images, which confront inherent difficulties due to the ill-posed nature of monocular depth learning. Instead of using a sole monocular depth method, in this work, we propose a novel Surround-view Temporal Stereo (STS) technique that leverages the geometry correspondence between frames across time to facilitate accurate depth learning. Specifically, we regard the field of views from all cameras around the ego vehicle as a unified view, namely surroundview, and conduct temporal stereo matching on it. The resulting geometrical correspondence between different frames from STS is utilized and combined with the monocular depth to yield final depth prediction. Comprehensive experiments on nuScenes show that STS greatly boosts 3D detection ability, notably for medium and long distance objects. On BEVDepth with ResNet-50 backbone, STS improves mAP and NDS by 2.6% and 1.4%, respectively. Consistent improvements are observed when using a larger backbone and a larger image resolution, demonstrating its effectiveness
BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection
Jun 21, 2022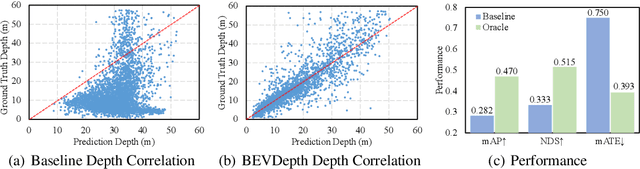
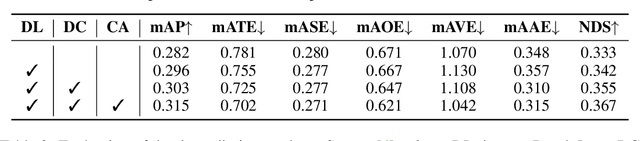
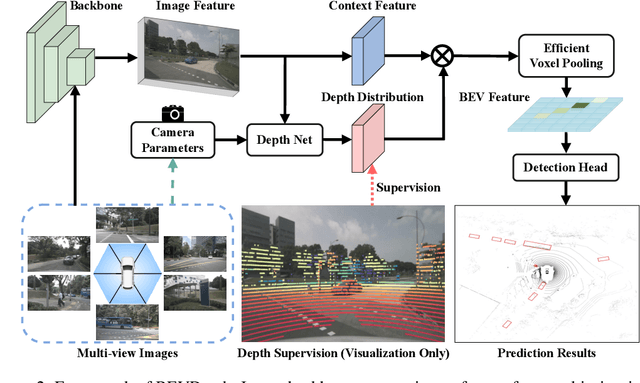
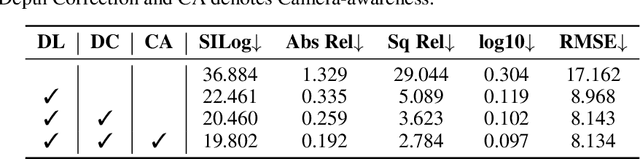
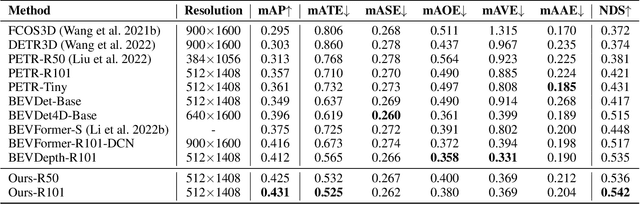
In this research, we propose a new 3D object detector with a trustworthy depth estimation, dubbed BEVDepth, for camera-based Bird's-Eye-View (BEV) 3D object detection. By a thorough analysis of recent approaches, we discover that the depth estimation is implicitly learned without camera information, making it the de-facto fake-depth for creating the following pseudo point cloud. BEVDepth gets explicit depth supervision utilizing encoded intrinsic and extrinsic parameters. A depth correction sub-network is further introduced to counteract projecting-induced disturbances in depth ground truth. To reduce the speed bottleneck while projecting features from image-view into BEV using estimated depth, a quick view-transform operation is also proposed. Besides, our BEVDepth can be easily extended with input from multi-frame. Without any bells and whistles, BEVDepth achieves the new state-of-the-art 60.0% NDS on the challenging nuScenes test set while maintaining high efficiency. For the first time, the performance gap between the camera and LiDAR is largely reduced within 10% NDS.
Pathological Image Segmentation with Noisy Labels
Mar 20, 2021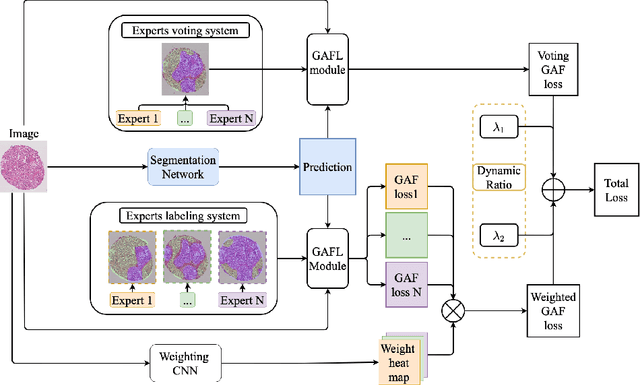
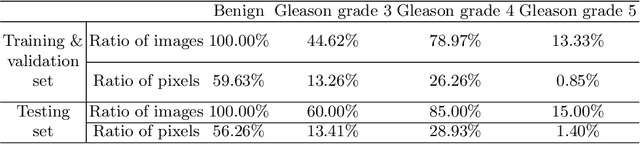
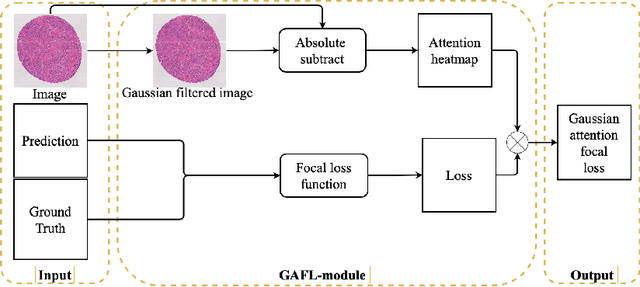
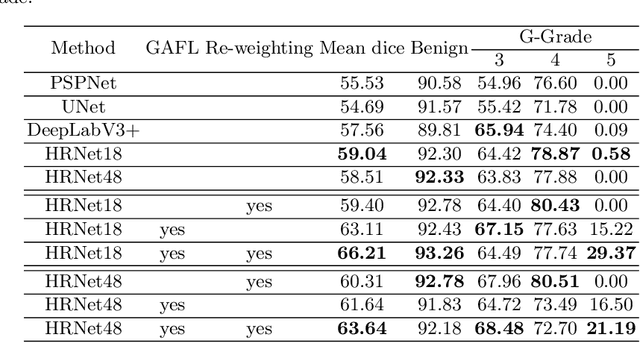
Segmentation of pathological images is essential for accurate disease diagnosis. The quality of manual labels plays a critical role in segmentation accuracy; yet, in practice, the labels between pathologists could be inconsistent, thus confusing the training process. In this work, we propose a novel label re-weighting framework to account for the reliability of different experts' labels on each pixel according to its surrounding features. We further devise a new attention heatmap, which takes roughness as prior knowledge to guide the model to focus on important regions. Our approach is evaluated on the public Gleason 2019 datasets. The results show that our approach effectively improves the model's robustness against noisy labels and outperforms state-of-the-art approaches.