 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-Resolution Based Patch-Free 3D Medical Image Segmentation with Self-Supervised Guidance
Oct 26, 2022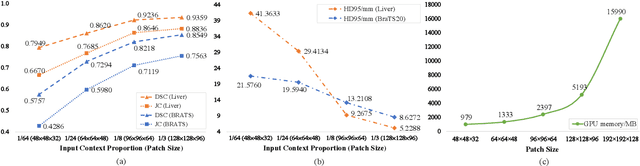
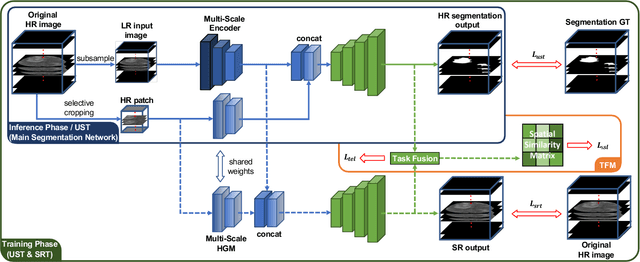
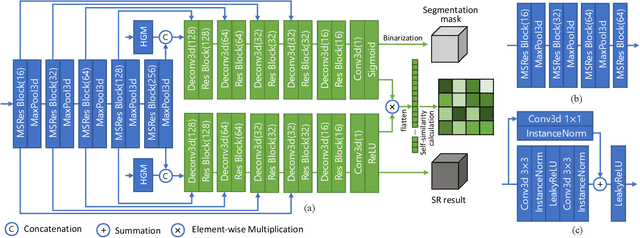
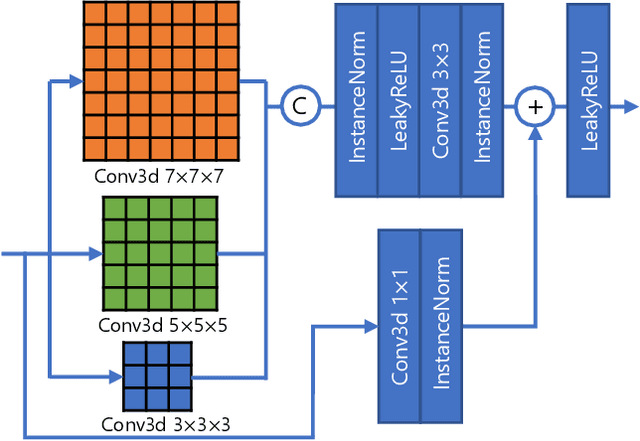
High resolution (HR) 3D medical image segmentation plays an important role in clinical diagnoses. However, HR images are difficult to be directly processed by mainstream graphical cards due to limited video memory. Therefore, most existing 3D medical image segmentation methods use patch-based models, which ignores global context information that is useful in accurate segmentation and has low inference efficiency. To address these problems, we propose a super-resolution (SR) guided patch-free 3D medical image segmentation framework that can realize HR segmentation with global information of low-resolution (LR) input. The framework contains two tasks: semantic segmentation (main task) and super resolution (auxiliary task). To balance the information loss with the LR input, we introduce a Self-Supervised Guidance Module (SGM), which employs a selective search method to crop a HR patch from the original image as restoration guidance. Multi-scale convolutional layers are used to mitigate the scale-inconsistency between the HR guidance features and the LR features. Moreover, we propose a Task-Fusion Module (TFM) to exploit the inter connections between segmentation and SR task. This module can also be used for Test Phase Fine-tuning (TPF), leading to a better model generalization ability. When predicting, only the main segmentation task is needed, while other modules can be removed to accelerate the inference. The experiments results on two different datasets show that our framework outperforms current patch-based and patch-free models. Our model also has a four times higher inference speed compared to traditional patch-based methods. Our codes are available at: https://github.com/Dootmaan/PFSeg-Full.
Mixed Transformer U-Net For Medical Image Segmentation
Nov 11, 2021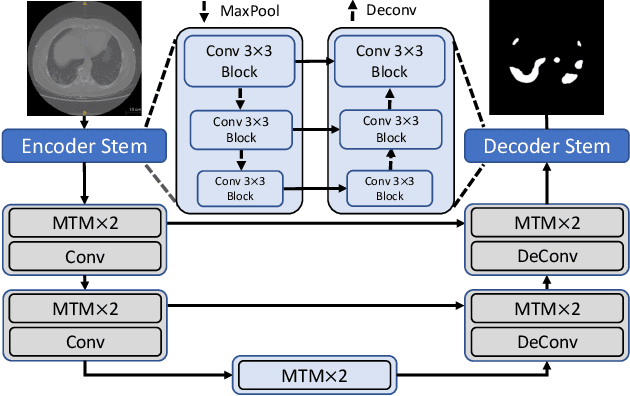

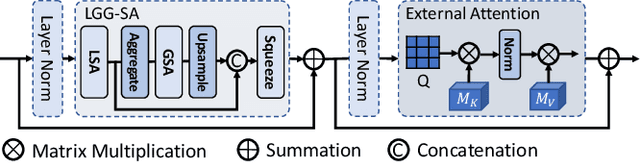
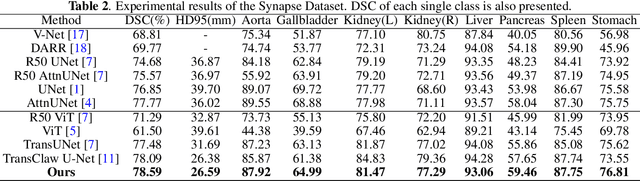
Though U-Net has achieved tremendous success in medical image segmentation tasks, it lacks the ability to explicitly model long-range dependencies. Therefore, Vision Transformers have emerged as alternative segmentation structures recently, for their innate ability of capturing long-range correlations through Self-Attention (SA). However, Transformers usually rely on large-scale pre-training and have high computational complexity. Furthermore, SA can only model self-affinities within a single sample, ignoring the potential correlations of the overall dataset. To address these problems, we propose a novel Transformer module named Mixed Transformer Module (MTM) for simultaneous inter- and intra- affinities learning. MTM first calculates self-affinities efficiently through our well-designed Local-Global Gaussian-Weighted Self-Attention (LGG-SA). Then, it mines inter-connections between data samples through External Attention (EA). By using MTM, we construct a U-shaped model named Mixed Transformer U-Net (MT-UNet) for accurate medical image segmentation. We test our method on two different public datasets, and the experimental results show that the proposed method achieves better performance over other state-of-the-art methods. The code is available at: https://github.com/Dootmaan/MT-UNet.
Genotype-Guided Radiomics Signatures for Recurrence Prediction of Non-Small-Cell Lung Cancer
Apr 29, 2021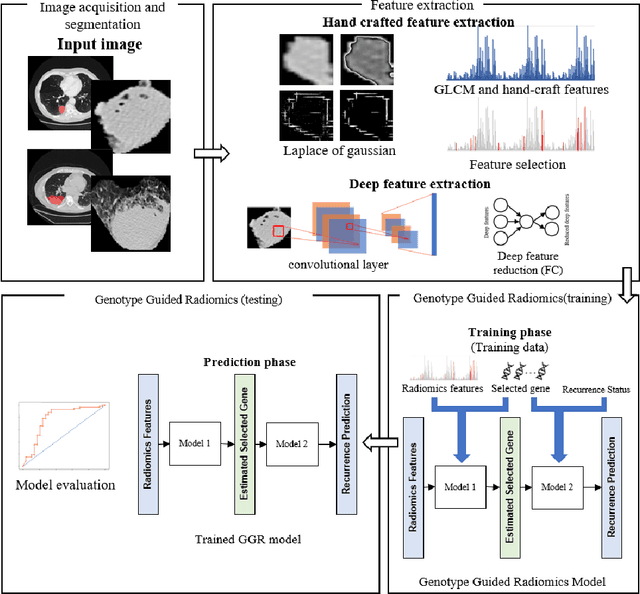
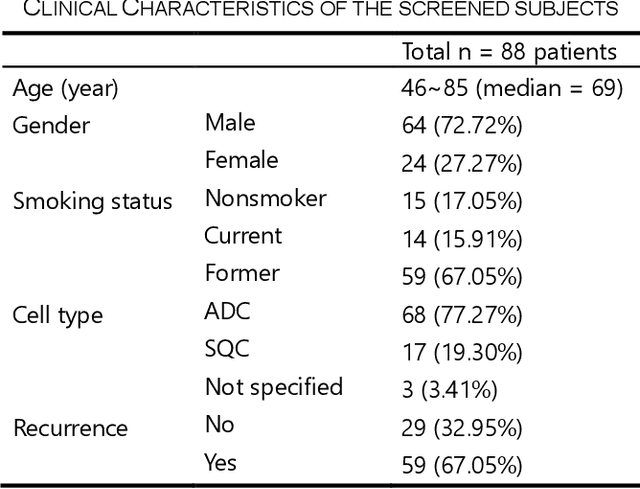

Non-small cell lung cancer (NSCLC) is a serious disease and has a high recurrence rate after the surgery. Recently, many machine learning methods have been proposed for recurrence prediction. The methods using gene data have high prediction accuracy but require high cost. Although the radiomics signatures using only CT image are not expensive, its accuracy is relatively low. In this paper, we propose a genotype-guided radiomics method (GGR) for obtaining high prediction accuracy with low cost. We used a public radiogenomics dataset of NSCLC, which includes CT images and gene data. The proposed method is a two-step method, which consists of two models. The first model is a gene estimation model, which is used to estimate the gene expression from radiomics features and deep features extracted from computer tomography (CT) image. The second model is used to predict the recurrence using the estimated gene expression data. The proposed GGR method designed based on hybrid features which is combination of handcrafted-based and deep learning-based. The experiments demonstrated that the prediction accuracy can be improved significantly from 78.61% (existing radiomics method) and 79.14% (deep learning method) to 83.28% by the proposed GGR.
Graph-based Pyramid Global Context Reasoning with a Saliency-aware Projection for COVID-19 Lung Infections Segmentation
Mar 07, 2021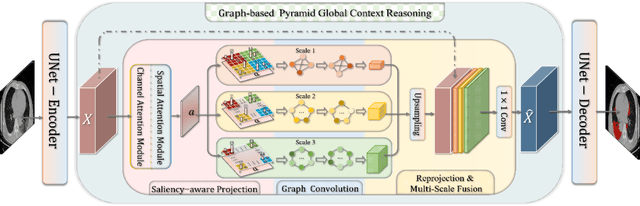
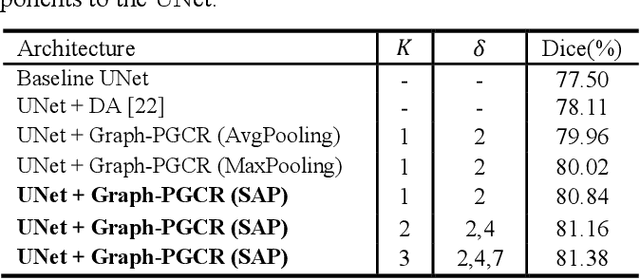
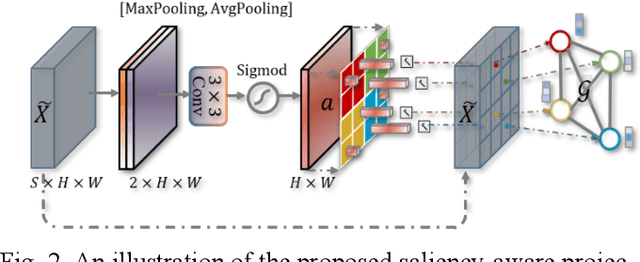
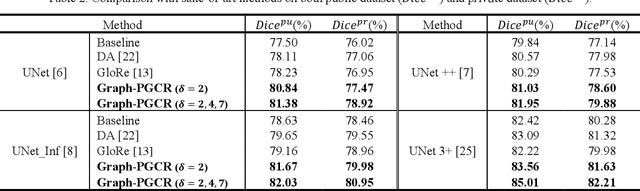
Coronavirus Disease 2019 (COVID-19) has rapidly spread in 2020, emerging a mass of studies for lung infection segmentation from CT images. Though many methods have been proposed for this issue, it is a challenging task because of infections of various size appearing in different lobe zones. To tackle these issues, we propose a Graph-based Pyramid Global Context Reasoning (Graph-PGCR) module, which is capable of modeling long-range dependencies among disjoint infections as well as adapt size variation. We first incorporate graph convolution to exploit long-term contextual information from multiple lobe zones. Different from previous average pooling or maximum object probability, we propose a saliency-aware projection mechanism to pick up infection-related pixels as a set of graph nodes. After graph reasoning, the relation-aware features are reversed back to the original coordinate space for the down-stream tasks. We further construct multiple graphs with different sampling rates to handle the size variation problem. To this end, distinct multi-scale long-range contextual patterns can be captured. Our Graph-PGCR module is plug-and-play, which can be integrated into any architecture to improve its performance. Experiments demonstrated that the proposed method consistently boost the performance of state-of-the-art backbone architectures on both of public and our private COVID-19 datasets.
PA-ResSeg: A Phase Attention Residual Network for Liver Tumor Segmentation from Multi-phase CT Images
Feb 27, 2021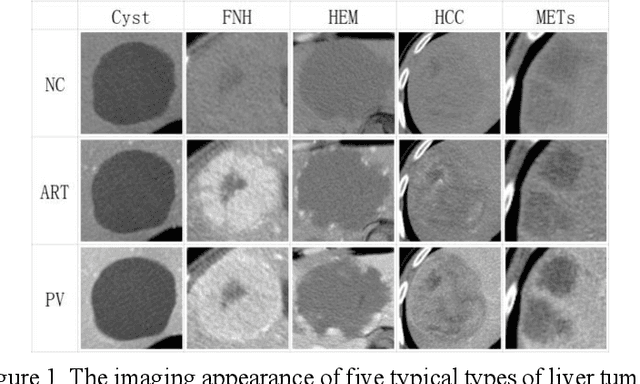
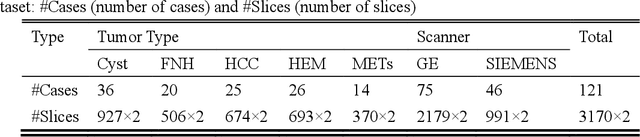
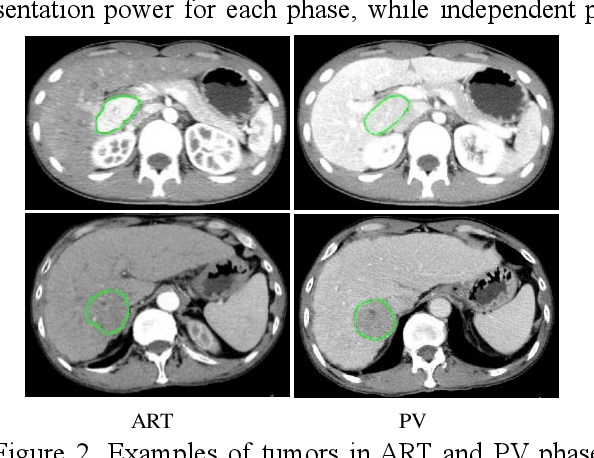
In this paper, we propose a phase attention residual network (PA-ResSeg) to model multi-phase features for accurate liver tumor segmentation, in which a phase attention (PA) is newly proposed to additionally exploit the images of arterial (ART) phase to facilitate the segmentation of portal venous (PV) phase. The PA block consists of an intra-phase attention (Intra-PA) module and an inter-phase attention (Inter-PA) module to capture channel-wise self-dependencies and cross-phase interdependencies, respectively. Thus it enables the network to learn more representative multi-phase features by refining the PV features according to the channel dependencies and recalibrating the ART features based on the learned interdependencies between phases. We propose a PA-based multi-scale fusion (MSF) architecture to embed the PA blocks in the network at multiple levels along the encoding path to fuse multi-scale features from multi-phase images. Moreover, a 3D boundary-enhanced loss (BE-loss) is proposed for training to make the network more sensitive to boundaries. To evaluate the performance of our proposed PA-ResSeg, we conducted experiments on a multi-phase CT dataset of focal liver lesions (MPCT-FLLs). Experimental results show the effectiveness of the proposed method by achieving a dice per case (DPC) of 0.77.87, a dice global (DG) of 0.8682, a volumetric overlap error (VOE) of 0.3328 and a relative volume difference (RVD) of 0.0443 on the MPCT-FLLs. Furthermore, to validate the effectiveness and robustness of PA-ResSeg, we conducted extra experiments on another multi-phase liver tumor dataset and obtained a DPC of 0.8290, a DG of 0.9132, a VOE of 0.2637 and a RVD of 0.0163. The proposed method shows its robustness and generalization capability in different datasets and different backbones.
MCGKT-Net: Multi-level Context Gating Knowledge Transfer Network for Single Image Deraining
Oct 19, 2020
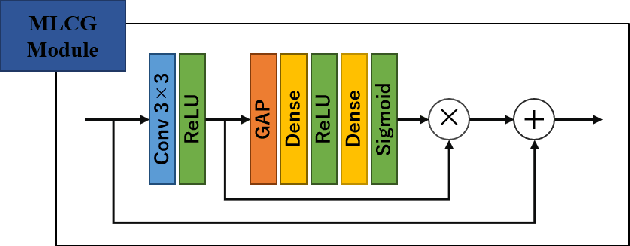
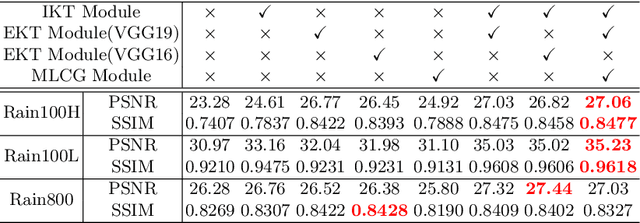

Rain streak removal in a single image is a very challenging task due to its ill-posed nature in essence. Recently, the end-to-end learning techniques with deep convolutional neural networks (DCNN) have made great progress in this task. However, the conventional DCNN-based deraining methods have struggled to exploit deeper and more complex network architectures for pursuing better performance. This study proposes a novel MCGKT-Net for boosting deraining performance, which is a naturally multi-scale learning framework being capable of exploring multi-scale attributes of rain streaks and different semantic structures of the clear images. In order to obtain high representative features inside MCGKT-Net, we explore internal knowledge transfer module using ConvLSTM unit for conducting interaction learning between different layers and investigate external knowledge transfer module for leveraging the knowledge already learned in other task domains. Furthermore, to dynamically select useful features in learning procedure, we propose a multi-scale context gating module in the MCGKT-Net using squeeze-and-excitation block. Experiments on three benchmark datasets: Rain100H, Rain100L, and Rain800, manifest impressive performance compared with state-of-the-art methods.