 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modality Attention Adapter: A Glioma Segmentation Fine-tuning Method for SAM Using Multimodal Brain MR Images
Paper and Code
Jul 03, 2023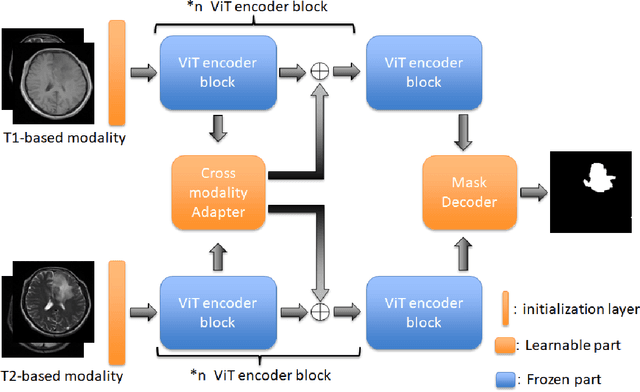
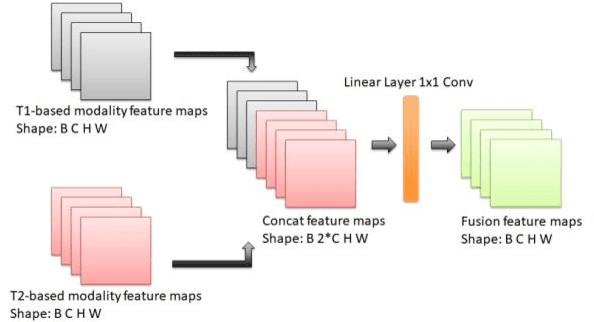

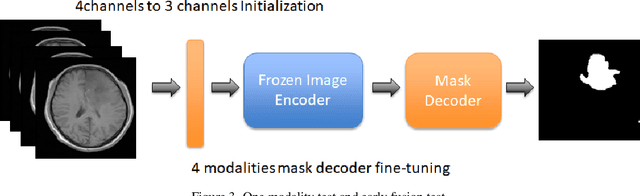
According to the 2021 World Health Organization (WHO) Classification scheme for gliomas, glioma segmentation is a very important basis for diagnosis and genotype prediction. In general, 3D multimodal brain MRI is an effective diagnostic tool. In the past decade, there has been an increase in the use of machine learning, particularly deep learning, for medical images processing. Thanks to the development of foundation models, models pre-trained with large-scale datasets have achieved better results on a variety of tasks. However, for medical images with small dataset sizes, deep learning methods struggle to achieve better results on real-world image datasets. In this paper, we propose a cross-modality attention adapter based on multimodal fusion to fine-tune the foundation model to accomplish the task of glioma segmentation in multimodal MRI brain images with better results. The effectiveness of the proposed method is validated via our private glioma data set from the First Affiliated Hospital of Zhengzhou University (FHZU) in Zhengzhou, China. Our proposed method is superior to current state-of-the-art methods with a Dice of 88.38% and Hausdorff distance of 10.64, thereby exhibiting a 4% increase in Dice to segment the glioma region for glioma treatment.