 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoracamom: Joint 3D Detection and Occupancy Prediction with Multi-view 4D Radars and Cameras for Omnidirectional Perception
Jan 26, 2025



3D object detection and occupancy prediction are critical tasks in autonomous driving, attracting significant attention. Despite the potential of recent vision-based methods, they encounter challenges under adverse conditions. Thus, integrating cameras with next-generation 4D imaging radar to achieve unified multi-task perception is highly significant, though research in this domain remains limited. In this paper, we propose Doracamom, the first framework that fuses multi-view cameras and 4D radar for joint 3D object detection and semantic occupancy prediction, enabling comprehensive environmental perception. Specifically, we introduce a novel Coarse Voxel Queries Generator that integrates geometric priors from 4D radar with semantic features from images to initialize voxel queries, establishing a robust foundation for subsequent Transformer-based refinement. To leverage temporal information, we design a Dual-Branch Temporal Encoder that processes multi-modal temporal features in parallel across BEV and voxel spaces, enabling comprehensive spatio-temporal representation learning. Furthermore, we propose a Cross-Modal BEV-Voxel Fusion module that adaptively fuses complementary features through attention mechanisms while employing auxiliary tasks to enhance feature quality. Extensive experiments on the OmniHD-Scenes, View-of-Delft (VoD), and TJ4DRadSet datasets demonstrate that Doracamom achieves state-of-the-art performance in both tasks, establishing new benchmarks for multi-modal 3D perception. Code and models will be publicly available.
MetaOcc: Surround-View 4D Radar and Camera Fusion Framework for 3D Occupancy Prediction with Dual Training Strategies
Jan 26, 2025



3D occupancy prediction is crucial for autonomous driving perception. Fusion of 4D radar and camera provides a potential solution of robust occupancy prediction on serve weather with least cost. How to achieve effective multi-modal feature fusion and reduce annotation costs remains significant challenges. In this work, we propose MetaOcc, a novel multi-modal occupancy prediction framework that fuses surround-view cameras and 4D radar for comprehensive environmental perception. We first design a height self-attention module for effective 3D feature extraction from sparse radar points. Then, a local-global fusion mechanism is proposed to adaptively capture modality contributions while handling spatio-temporal misalignments. Temporal alignment and fusion module is employed to further aggregate historical feature. Furthermore, we develop a semi-supervised training procedure leveraging open-set segmentor and geometric constraints for pseudo-label generation, enabling robust perception with limited annotations. Extensive experiments on OmniHD-Scenes dataset demonstrate that MetaOcc achieves state-of-the-art performance, surpassing previous methods by significant margins. Notably, as the first semi-supervised 4D radar and camera fusion-based occupancy prediction approach, MetaOcc maintains 92.5% of the fully-supervised performance while using only 50% of ground truth annotations, establishing a new benchmark for multi-modal 3D occupancy prediction. Code and data are available at https://github.com/LucasYang567/MetaOcc.
OmniHD-Scenes: A Next-Generation Multimodal Dataset for Autonomous Driving
Dec 14, 2024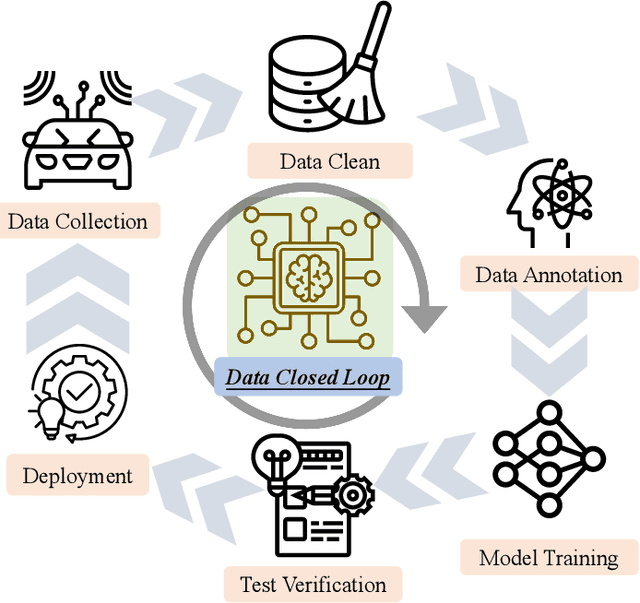

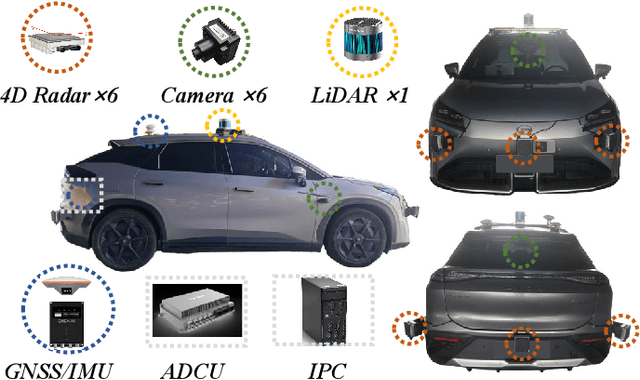

The rapid advancement of deep learning has intensified the need for comprehensive data for use by autonomous driving algorithms. High-quality datasets are crucial for the development of effective data-driven autonomous driving solutions. Next-generation autonomous driving datasets must be multimodal, incorporating data from advanced sensors that feature extensive data coverage, detailed annotations, and diverse scene representation. To address this need, we present OmniHD-Scenes, a large-scale multimodal dataset that provides comprehensive omnidirectional high-definition data. The OmniHD-Scenes dataset combines data from 128-beam LiDAR, six cameras, and six 4D imaging radar systems to achieve full environmental perception. The dataset comprises 1501 clips, each approximately 30-s long, totaling more than 450K synchronized frames and more than 5.85 million synchronized sensor data points. We also propose a novel 4D annotation pipeline. To date, we have annotated 200 clips with more than 514K precise 3D bounding boxes. These clips also include semantic segmentation annotations for static scene elements. Additionally, we introduce a novel automated pipeline for generation of the dense occupancy ground truth, which effectively leverages information from non-key frames. Alongside the proposed dataset, we establish comprehensive evaluation metrics, baseline models, and benchmarks for 3D detection and semantic occupancy prediction. These benchmarks utilize surround-view cameras and 4D imaging radar to explore cost-effective sensor solutions for autonomous driving applications. Extensive experiments demonstrate the effectiveness of our low-cost sensor configuration and its robustness under adverse conditions. Data will be released at https://www.2077ai.com/OmniHD-Scenes.
Cross-modality Attention Adapter: A Glioma Segmentation Fine-tuning Method for SAM Using Multimodal Brain MR Images
Jul 03, 2023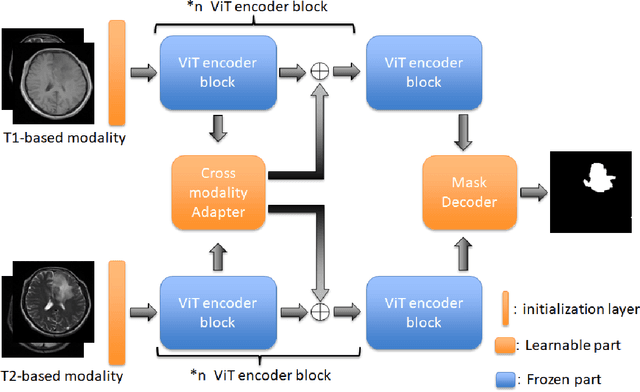
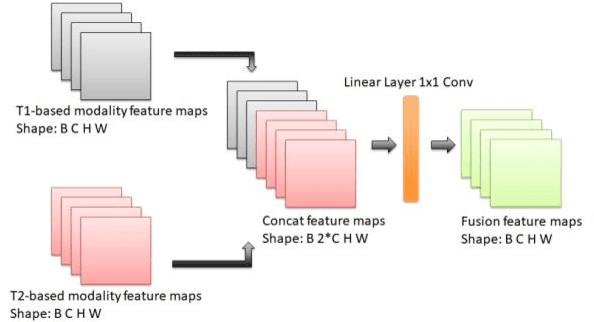

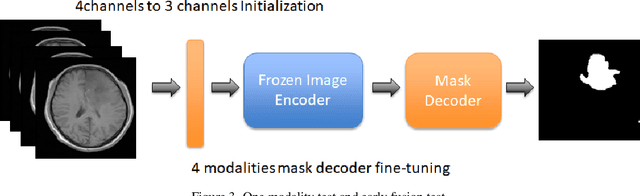
According to the 2021 World Health Organization (WHO) Classification scheme for gliomas, glioma segmentation is a very important basis for diagnosis and genotype prediction. In general, 3D multimodal brain MRI is an effective diagnostic tool. In the past decade, there has been an increase in the use of machine learning, particularly deep learning, for medical images processing. Thanks to the development of foundation models, models pre-trained with large-scale datasets have achieved better results on a variety of tasks. However, for medical images with small dataset sizes, deep learning methods struggle to achieve better results on real-world image datasets. In this paper, we propose a cross-modality attention adapter based on multimodal fusion to fine-tune the foundation model to accomplish the task of glioma segmentation in multimodal MRI brain images with better results. The effectiveness of the proposed method is validated via our private glioma data set from the First Affiliated Hospital of Zhengzhou University (FHZU) in Zhengzhou, China. Our proposed method is superior to current state-of-the-art methods with a Dice of 88.38% and Hausdorff distance of 10.64, thereby exhibiting a 4% increase in Dice to segment the glioma region for glioma treatment.
Deep Virtual-to-Real Distillation for Pedestrian Crossing Prediction
Nov 02, 2022Pedestrian crossing is one of the most typical behavior which conflicts with natural driving behavior of vehicles. Consequently, pedestrian crossing prediction is one of the primary task that influences the vehicle planning for safe driving. However, current methods that rely on the practically collected data in real driving scenes cannot depict and cover all kinds of scene condition in real traffic world. To this end, we formulate a deep virtual to real distillation framework by introducing the synthetic data that can be generated conveniently, and borrow the abundant information of pedestrian movement in synthetic videos for the pedestrian crossing prediction in real data with a simple and lightweight implementation. In order to verify this framework, we construct a benchmark with 4667 virtual videos owning about 745k frames (called Virtual-PedCross-4667), and evaluate the proposed method on two challenging datasets collected in real driving situations, i.e., JAAD and PIE datasets. State-of-the-art performance of this framework is demonstrated by exhaustive experiment analysis. The dataset and code can be downloaded from the website \url{http://www.lotvs.net/code_data/}.
TJ4DRadSet: A 4D Radar Dataset for Autonomous Driving
Apr 30, 2022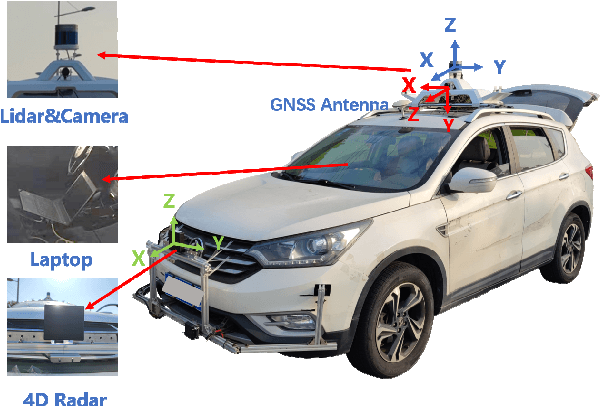
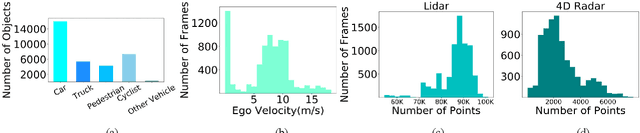

The new generation of 4D high-resolution imaging radar provides not only a huge amount of point cloud but also additional elevation measurement, which has a great potential of 3D sensing in autonomous driving. In this paper, we introduce an autonomous driving dataset named TJ4DRadSet, including multi-modal sensors that are 4D radar, lidar, camera and GNSS, with about 40K frames in total. 7757 frames within 44 consecutive sequences in various driving scenarios are well annotated with 3D bounding boxes and track id. We provide a 4D radar-based 3D object detection baseline for our dataset to demonstrate the effectiveness of deep learning methods for 4D radar point clouds.
Spread-gram: A spreading-activation schema of network structural learning
Sep 30, 2019


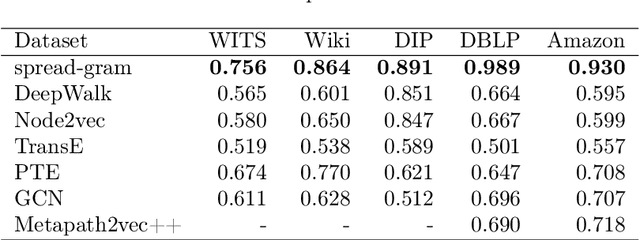
Network representation learning has exploded recently. However, existing studies usually reconstruct networks as sequences or matrices, which may cause information bias or sparsity problem during model training. Inspired by a cognitive model of human memory, we propose a network representation learning scheme. In this scheme, we learn node embeddings by adjusting the proximity of nodes traversing the spreading structure of the network. Our proposed method shows a significant improvement in multiple analysis tasks based on various real-world networks, ranging from semantic networks to protein interaction networks, international trade networks, human behavior networks, etc. In particular, our model can effectively discover the hierarchical structures in networks. The well-organized model training speeds up the convergence to only a small number of iterations, and the training time is linear with respect to the edge numbers.