 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Anomalous Sound Detection with Attribute-aware Representation from Domain-adaptive Pre-training
Sep 16, 2025Anomalous Sound Detection (ASD) is often formulated as a machine attribute classification task, a strategy necessitated by the common scenario where only normal data is available for training. However, the exhaustive collection of machine attribute labels is laborious and impractical. To address the challenge of missing attribute labels, this paper proposes an agglomerative hierarchical clustering method for the assignment of pseudo-attribute labels using representations derived from a domain-adaptive pre-trained model, which are expected to capture machine attribute characteristics. We then apply model adaptation to this pre-trained model through supervised fine-tuning for machine attribute classification, resulting in a new state-of-the-art performance. Evaluation on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2025 Challenge dataset demonstrates that our proposed approach yields significant performance gains, ultimately outperforming our previous top-ranking system in the challenge.
BOASF: A Unified Framework for Speeding up Automatic Machine Learning via Adaptive Successive Filtering
Jul 28, 2025Machine learning has been making great success in many application areas. However, for the non-expert practitioners, it is always very challenging to address a machine learning task successfully and efficiently. Finding the optimal machine learning model or the hyperparameter combination set from a large number of possible alternatives usually requires considerable expert knowledge and experience. To tackle this problem, we propose a combined Bayesian Optimization and Adaptive Successive Filtering algorithm (BOASF) under a unified multi-armed bandit framework to automate the model selection or the hyperparameter optimization. Specifically, BOASF consists of multiple evaluation rounds in each of which we select promising configurations for each arm using the Bayesian optimization. Then, ASF can early discard the poor-performed arms adaptively using a Gaussian UCB-based probabilistic model. Furthermore, a Softmax model is employed to adaptively allocate available resources for each promising arm that advances to the next round. The arm with a higher probability of advancing will be allocated more resources. Experimental results show that BOASF is effective for speeding up the model selection and hyperparameter optimization processes while achieving robust and better prediction performance than the existing state-of-the-art automatic machine learning methods. Moreover, BOASF achieves better anytime performance under various time budgets.
PaMMA-Net: Plasmas magnetic measurement evolution based on data-driven incremental accumulative prediction
Jan 23, 2025



An accurate evolution model is crucial for effective control and in-depth study of fusion plasmas. Evolution methods based on physical models often encounter challenges such as insufficient robustness or excessive computational costs. Given the proven strong fitting capabilities of deep learning methods across various fields, including plasma research, this paper introduces a deep learning-based magnetic measurement evolution method named PaMMA-Net (Plasma Magnetic Measurements Incremental Accumulative Prediction Network). This network is capable of evolving magnetic measurements in tokamak discharge experiments over extended periods or, in conjunction with equilibrium reconstruction algorithms, evolving macroscopic parameters such as plasma shape. Leveraging a incremental prediction approach and data augmentation techniques tailored for magnetic measurements, PaMMA-Net achieves superior evolution results compared to existing studies. The tests conducted on real experimental data from EAST validate the high generalization capability of the proposed method.
MVANet: Multi-Stage Video Attention Network for Sound Event Localization and Detection with Source Distance Estimation
Nov 21, 2024Sound event localization and detection with source distance estimation (3D SELD) involves not only identifying the sound category and its direction-of-arrival (DOA) but also predicting the source's distance, aiming to provide full information about the sound position. This paper proposes a multi-stage video attention network (MVANet) for audio-visual (AV) 3D SELD. Multi-stage audio features are used to adaptively capture the spatial information of sound sources in videos. We propose a novel output representation that combines the DOA with distance of sound sources by calculating the real Cartesian coordinates to address the newly introduced source distance estimation (SDE) task in the Detection and Classification of Acoustic Scenes and Events (DCASE) 2024 Challenge. We also employ a variety of effective data augmentation and pre-training methods. Experimental results on the STARSS23 dataset have proven the effectiveness of our proposed MVANet. By integrating the aforementioned techniques, our system outperforms the top-ranked method we used in the AV 3D SELD task of the DCASE 2024 Challenge without model ensemble. The code will be made publicly available in the future.
The USTC-NERCSLIP Systems for The ICMC-ASR Challenge
Jul 02, 2024


This report describes the submitted system to the In-Car Multi-Channel Automatic Speech Recognition (ICMC-ASR) challenge, which considers the ASR task with multi-speaker overlapping and Mandarin accent dynamics in the ICMC case. We implement the front-end speaker diarization using the self-supervised learning representation based multi-speaker embedding and beamforming using the speaker position, respectively. For ASR, we employ an iterative pseudo-label generation method based on fusion model to obtain text labels of unsupervised data. To mitigate the impact of accent, an Accent-ASR framework is proposed, which captures pronunciation-related accent features at a fine-grained level and linguistic information at a coarse-grained level. On the ICMC-ASR eval set, the proposed system achieves a CER of 13.16% on track 1 and a cpCER of 21.48% on track 2, which significantly outperforms the official baseline system and obtains the first rank on both tracks.
Exploring Audio-Visual Information Fusion for Sound Event Localization and Detection In Low-Resource Realistic Scenarios
Jun 21, 2024This study presents an audio-visual information fusion approach to sound event localization and detection (SELD) in low-resource scenarios. We aim at utilizing audio and video modality information through cross-modal learning and multi-modal fusion. First, we propose a cross-modal teacher-student learning (TSL) framework to transfer information from an audio-only teacher model, trained on a rich collection of audio data with multiple data augmentation techniques, to an audio-visual student model trained with only a limited set of multi-modal data. Next, we propose a two-stage audio-visual fusion strategy, consisting of an early feature fusion and a late video-guided decision fusion to exploit synergies between audio and video modalities. Finally, we introduce an innovative video pixel swapping (VPS) technique to extend an audio channel swapping (ACS) method to an audio-visual joint augmentation. Evaluation results on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge data set demonstrate significant improvements in SELD performances. Furthermore, our submission to the SELD task of the DCASE 2023 Challenge ranks first place by effectively integrating the proposed techniques into a model ensemble.
Multitask frame-level learning for few-shot sound event detection
Mar 17, 2024This paper focuses on few-shot Sound Event Detection (SED), which aims to automatically recognize and classify sound events with limited samples. However, prevailing methods methods in few-shot SED predominantly rely on segment-level predictions, which often providing detailed, fine-grained predictions, particularly for events of brief duration. Although frame-level prediction strategies have been proposed to overcome these limitations, these strategies commonly face difficulties with prediction truncation caused by background noise. To alleviate this issue, we introduces an innovative multitask frame-level SED framework. In addition, we introduce TimeFilterAug, a linear timing mask for data augmentation, to increase the model's robustness and adaptability to diverse acoustic environments. The proposed method achieves a F-score of 63.8%, securing the 1st rank in the few-shot bioacoustic event detection category of the Detection and Classification of Acoustic Scenes and Events Challenge 2023.
SegRap2023: A Benchmark of Organs-at-Risk and Gross Tumor Volume Segmentation for Radiotherapy Planning of Nasopharyngeal Carcinoma
Dec 15, 2023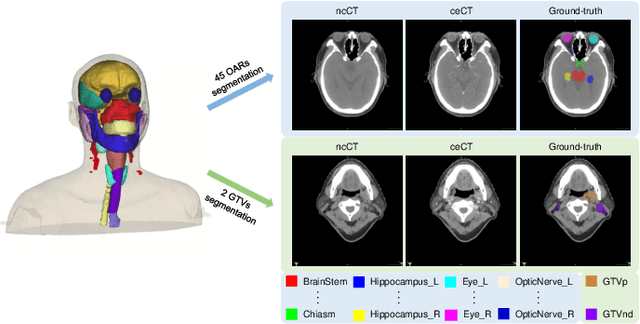

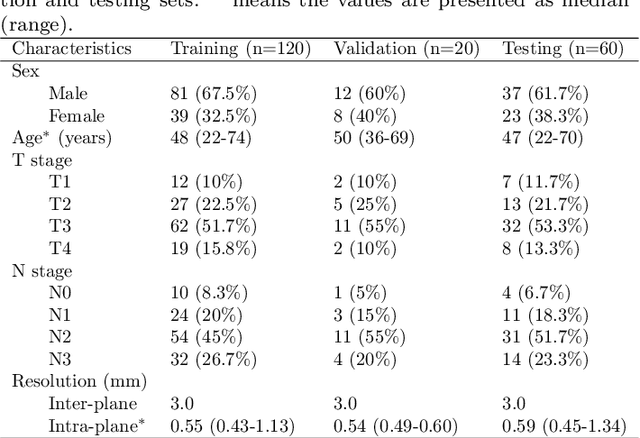
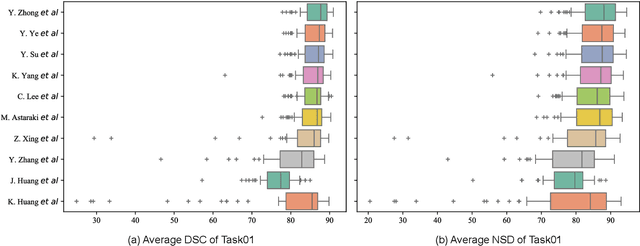
Radiation therapy is a primary and effective NasoPharyngeal Carcinoma (NPC) treatment strategy. The precise delineation of Gross Tumor Volumes (GTVs) and Organs-At-Risk (OARs) is crucial in radiation treatment, directly impacting patient prognosis. Previously, the delineation of GTVs and OARs was performed by experienced radiation oncologists. Recently, deep learning has achieved promising results in many medical image segmentation tasks. However, for NPC OARs and GTVs segmentation, few public datasets are available for model development and evaluation. To alleviate this problem, the SegRap2023 challenge was organized in conjunction with MICCAI2023 and presented a large-scale benchmark for OAR and GTV segmentation with 400 Computed Tomography (CT) scans from 200 NPC patients, each with a pair of pre-aligned non-contrast and contrast-enhanced CT scans. The challenge's goal was to segment 45 OARs and 2 GTVs from the paired CT scans. In this paper, we detail the challenge and analyze the solutions of all participants. The average Dice similarity coefficient scores for all submissions ranged from 76.68\% to 86.70\%, and 70.42\% to 73.44\% for OARs and GTVs, respectively. We conclude that the segmentation of large-size OARs is well-addressed, and more efforts are needed for GTVs and small-size or thin-structure OARs. The benchmark will remain publicly available here: https://segrap2023.grand-challenge.org
AST-SED: An Effective Sound Event Detection Method Based on Audio Spectrogram Transformer
Mar 07, 2023



In this paper, we propose an effective sound event detection (SED) method based on the audio spectrogram transformer (AST) model, pretrained on the large-scale AudioSet for audio tagging (AT) task, termed AST-SED. Pretrained AST models have recently shown promise on DCASE2022 challenge task4 where they help mitigate a lack of sufficient real annotated data. However, mainly due to differences between the AT and SED tasks, it is suboptimal to directly utilize outputs from a pretrained AST model. Hence the proposed AST-SED adopts an encoder-decoder architecture to enable effective and efficient fine-tuning without needing to redesign or retrain the AST model. Specifically, the Frequency-wise Transformer Encoder (FTE) consists of transformers with self attention along the frequency axis to address multiple overlapped audio events issue in a single clip. The Local Gated Recurrent Units Decoder (LGD) consists of nearest-neighbor interpolation (NNI) and Bidirectional Gated Recurrent Units (Bi-GRU) to compensate for temporal resolution loss in the pretrained AST model output. Experimental results on DCASE2022 task4 development set have demonstrated the superiority of the proposed AST-SED with FTE-LGD architecture. Specifically, the Event-Based F1-score (EB-F1) of 59.60% and Polyphonic Sound detection Score scenario1 (PSDS1) score of 0.5140 significantly outperform CRNN and other pretrained AST-based systems.
Deep Virtual-to-Real Distillation for Pedestrian Crossing Prediction
Nov 02, 2022Pedestrian crossing is one of the most typical behavior which conflicts with natural driving behavior of vehicles. Consequently, pedestrian crossing prediction is one of the primary task that influences the vehicle planning for safe driving. However, current methods that rely on the practically collected data in real driving scenes cannot depict and cover all kinds of scene condition in real traffic world. To this end, we formulate a deep virtual to real distillation framework by introducing the synthetic data that can be generated conveniently, and borrow the abundant information of pedestrian movement in synthetic videos for the pedestrian crossing prediction in real data with a simple and lightweight implementation. In order to verify this framework, we construct a benchmark with 4667 virtual videos owning about 745k frames (called Virtual-PedCross-4667), and evaluate the proposed method on two challenging datasets collected in real driving situations, i.e., JAAD and PIE datasets. State-of-the-art performance of this framework is demonstrated by exhaustive experiment analysis. The dataset and code can be downloaded from the website \url{http://www.lotvs.net/code_data/}.