 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Training of Speech Enhancement and Self-supervised Model for Noise-robust ASR
May 26, 2022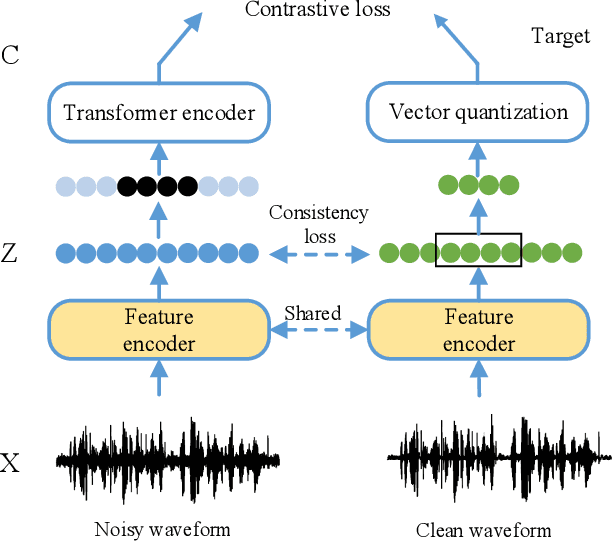
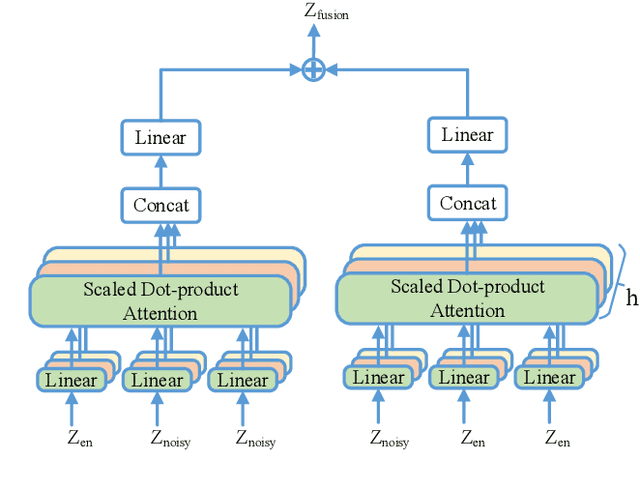
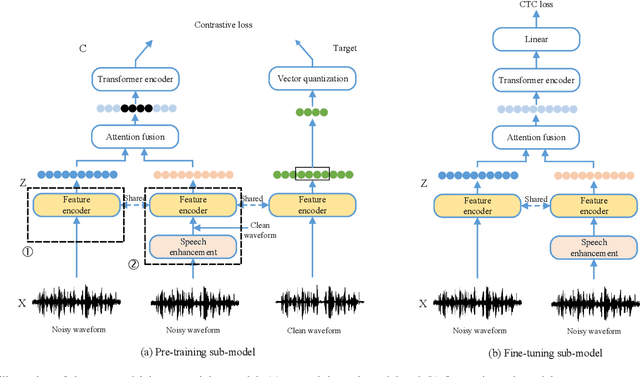
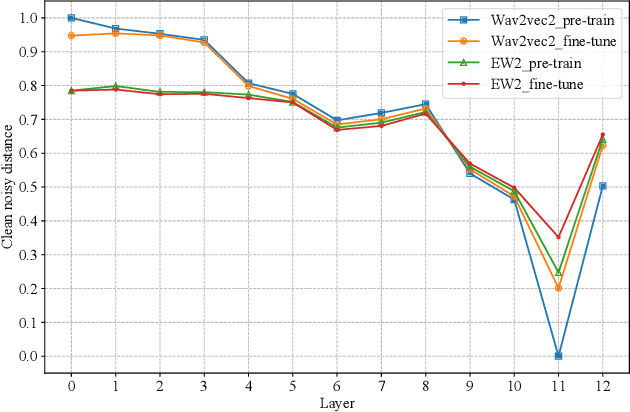
Speech enhancement (SE) is usually required as a front end to improve the speech quality in noisy environments, while the enhanced speech might not be optimal for automatic speech recognition (ASR) systems due to speech distortion. On the other hand, it was shown that self-supervised pre-training enables the utilization of a large amount of unlabeled noisy data, which is rather beneficial for the noise robustness of ASR. However, the potential of the (optimal) integration of SE and self-supervised pre-training still remains unclear. In order to find an appropriate combination and reduce the impact of speech distortion caused by SE, in this paper we therefore propose a joint pre-training approach for the SE module and the self-supervised model. First, in the pre-training phase the original noisy waveform or the waveform obtained by SE is fed into the self-supervised model to learn the contextual representation, where the quantified clean speech acts as the target. Second, we propose a dual-attention fusion method to fuse the features of noisy and enhanced speeches, which can compensate the information loss caused by separately using individual modules. Due to the flexible exploitation of clean/noisy/enhanced branches, the proposed method turns out to be a generalization of some existing noise-robust ASR models, e.g., enhanced wav2vec2.0. Finally, experimental results on both synthetic and real noisy datasets show that the proposed joint training approach can improve the ASR performance under various noisy settings, leading to a stronger noise robustness.
Learning Contextually Fused Audio-visual Representations for Audio-visual Speech Recognition
Feb 15, 2022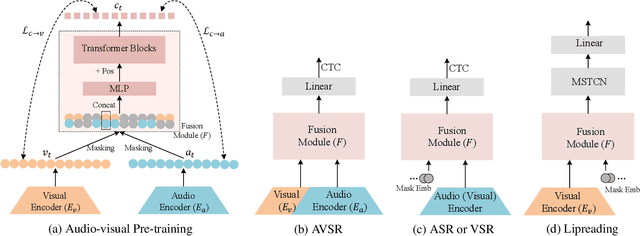
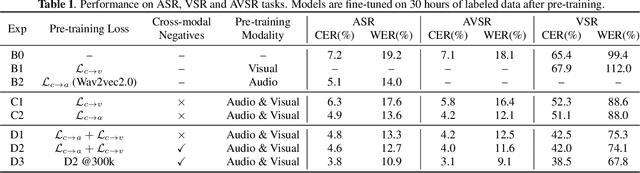

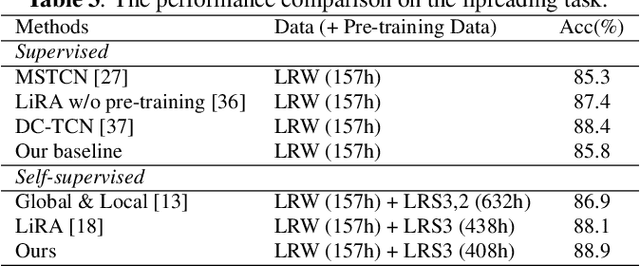
With the advance in self-supervised learning for audio and visual modalities, it has become possible to learn a robust audio-visual speech representation. This would be beneficial for improving the audio-visual speech recognition (AVSR) performance, as the multi-modal inputs contain more fruitful information in principle. In this paper, based on existing self-supervised representation learning methods for audio modality, we therefore propose an audio-visual representation learning approach. The proposed approach explores both the complementarity of audio-visual modalities and long-term context dependency using a transformer-based fusion module and a flexible masking strategy. After pre-training, the model is able to extract fused representations required by AVSR. Without loss of generality, it can be applied to single-modal tasks, e.g. audio/visual speech recognition by simply masking out one modality in the fusion module. The proposed pre-trained model is evaluated on speech recognition and lipreading tasks using one or two modalities, where the superiority is revealed.
A Noise-Robust Self-supervised Pre-training Model Based Speech Representation Learning for Automatic Speech Recognition
Jan 22, 2022


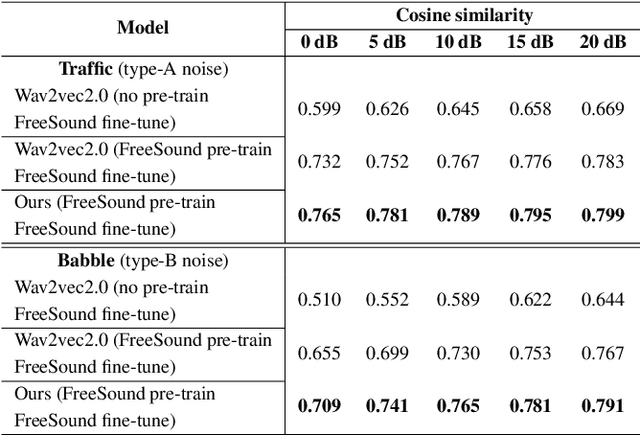
Wav2vec2.0 is a popular self-supervised pre-training framework for learning speech representations in the context of automatic speech recognition (ASR). It was shown that wav2vec2.0 has a good robustness against the domain shift, while the noise robustness is still unclear. In this work, we therefore first analyze the noise robustness of wav2vec2.0 via experiments. We observe that wav2vec2.0 pre-trained on noisy data can obtain good representations and thus improve the ASR performance on the noisy test set, which however brings a performance degradation on the clean test set. To avoid this issue, in this work we propose an enhanced wav2vec2.0 model. Specifically, the noisy speech and the corresponding clean version are fed into the same feature encoder, where the clean speech provides training targets for the model. Experimental results reveal that the proposed method can not only improve the ASR performance on the noisy test set which surpasses the original wav2vec2.0, but also ensure a tiny performance decrease on the clean test set. In addition, the effectiveness of the proposed method is demonstrated under different types of noise conditions.
XLST: Cross-lingual Self-training to Learn Multilingual Representation for Low Resource Speech Recognition
Mar 15, 2021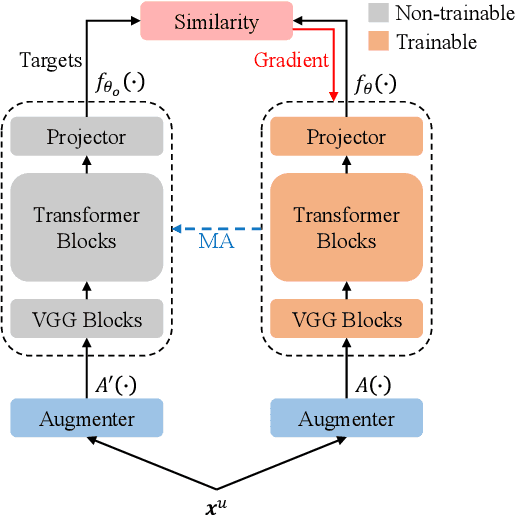
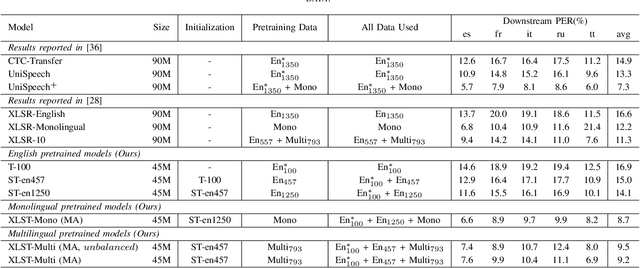
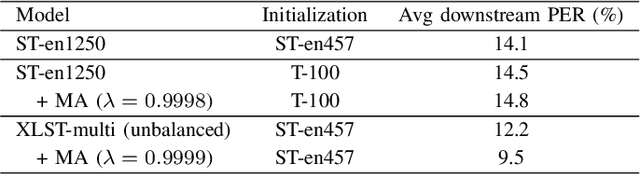

In this paper, we propose a weakly supervised multilingual representation learning framework, called cross-lingual self-training (XLST). XLST is able to utilize a small amount of annotated data from high-resource languages to improve the representation learning on multilingual un-annotated data. Specifically, XLST uses a supervised trained model to produce initial representations and another model to learn from them, by maximizing the similarity between output embeddings of these two models. Furthermore, the moving average mechanism and multi-view data augmentation are employed, which are experimentally shown to be crucial to XLST. Comprehensive experiments have been conducted on the CommonVoice corpus to evaluate the effectiveness of XLST. Results on 5 downstream low-resource ASR tasks shows that our multilingual pretrained model achieves relatively 18.6% PER reduction over the state-of-the-art self-supervised method, with leveraging additional 100 hours of annotated English data.