 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Contextually Fused Audio-visual Representations for Audio-visual Speech Recognition
Paper and Code
Feb 15, 2022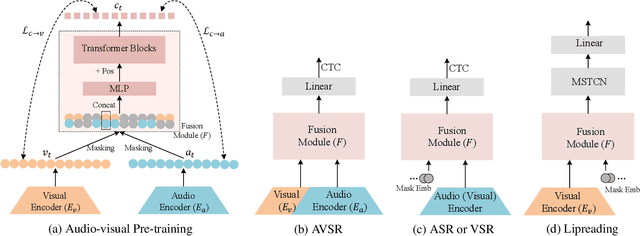
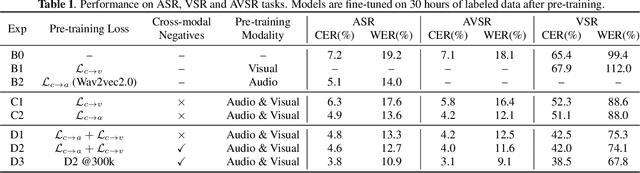

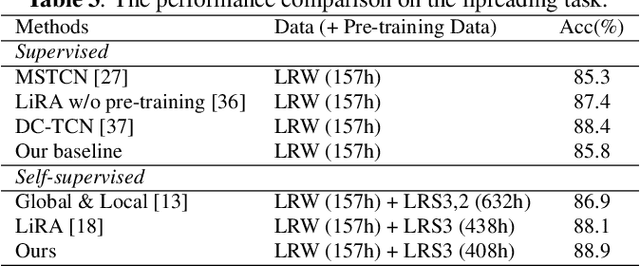
With the advance in self-supervised learning for audio and visual modalities, it has become possible to learn a robust audio-visual speech representation. This would be beneficial for improving the audio-visual speech recognition (AVSR) performance, as the multi-modal inputs contain more fruitful information in principle. In this paper, based on existing self-supervised representation learning methods for audio modality, we therefore propose an audio-visual representation learning approach. The proposed approach explores both the complementarity of audio-visual modalities and long-term context dependency using a transformer-based fusion module and a flexible masking strategy. After pre-training, the model is able to extract fused representations required by AVSR. Without loss of generality, it can be applied to single-modal tasks, e.g. audio/visual speech recognition by simply masking out one modality in the fusion module. The proposed pre-trained model is evaluated on speech recognition and lipreading tasks using one or two modalities, where the superiority is revealed.