 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting the Power of Human-Robot Collaboration: Coupling and Scale Effects in Bricklaying
Dec 10, 2022As an important contributor to GDP growth, the construction industry is suffering from labor shortage due to population ageing, COVID-19 pandemic, and harsh environments. Considering the complexity and dynamics of construction environment, it is still challenging to develop fully automated robots. For a long time in the future, workers and robots will coexist and collaborate with each other to build or maintain a facility efficiently. As an emerging field, human-robot collaboration (HRC) still faces various open problems. To this end, this pioneer research introduces an agent-based modeling approach to investigate the coupling effect and scale effect of HRC in the bricklaying process. With multiple experiments based on simulation, the dynamic and complex nature of HRC is illustrated in two folds: 1) agents in HRC are interdependent due to human factors of workers, features of robots, and their collaboration behaviors; 2) different parameters of HRC are correlated and have significant impacts on construction productivity (CP). Accidentally and interestingly, it is discovered that HRC has a scale effect on CP, which means increasing the number of collaborated human-robot teams will lead to higher CP even if the human-robot ratio keeps unchanged. Overall, it is argued that more investigations in HRC are needed for efficient construction, occupational safety, etc.; and this research can be taken as a stepstone for developing and evaluating new robots, optimizing HRC processes, and even training future industrial workers in the construction industry.
A Complementary Joint Training Approach Using Unpaired Speech and Text for Low-Resource Automatic Speech Recognition
Apr 05, 2022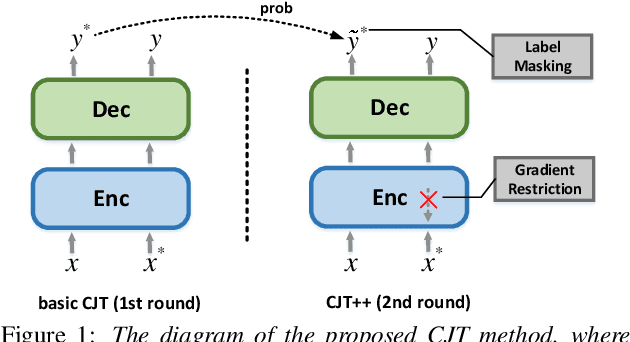
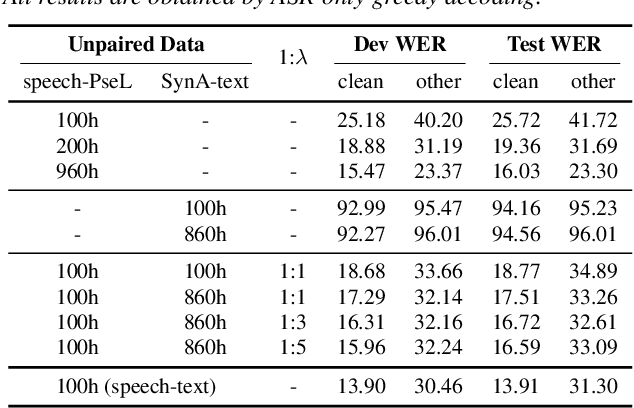
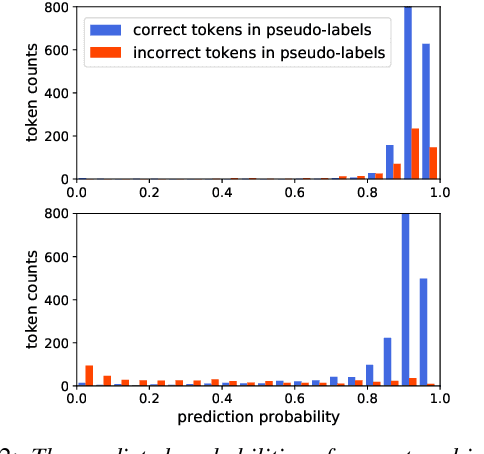
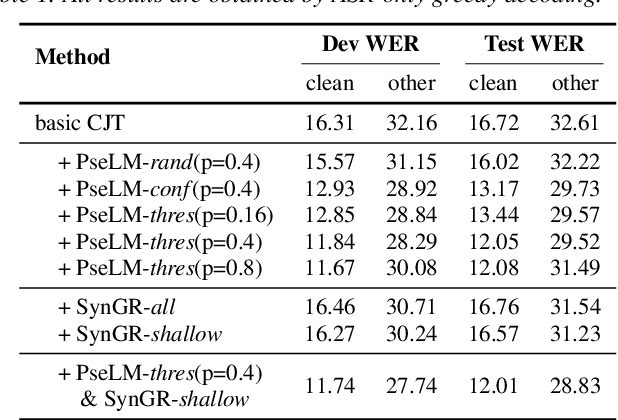
Unpaired data has shown to be beneficial for low-resource automatic speech recognition~(ASR), which can be involved in the design of hybrid models with multi-task training or language model dependent pre-training. In this work, we leverage unpaired data to train a general sequence-to-sequence model. Unpaired speech and text are used in the form of data pairs by generating the corresponding missing parts in prior to model training. Inspired by the complementarity of speech-PseudoLabel pair and SynthesizedAudio-text pair in both acoustic features and linguistic features, we propose a complementary joint training~(CJT) method that trains a model alternatively with two data pairs. Furthermore, label masking for pseudo-labels and gradient restriction for synthesized audio are proposed to further cope with the deviations from real data, termed as CJT++. Experimental results show that compared to speech-only training, the proposed basic CJT achieves great performance improvements on clean/other test sets, and the CJT++ re-training yields further performance enhancements. It is also apparent that the proposed method outperforms the wav2vec2.0 model with the same model size and beam size, particularly in extreme low-resource cases.
Learning Contextually Fused Audio-visual Representations for Audio-visual Speech Recognition
Feb 15, 2022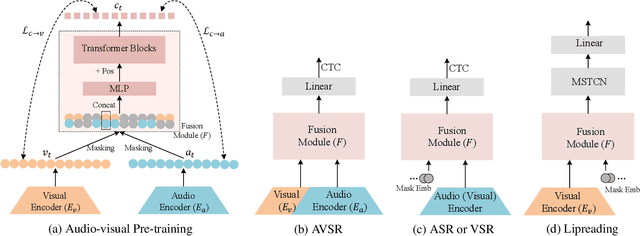
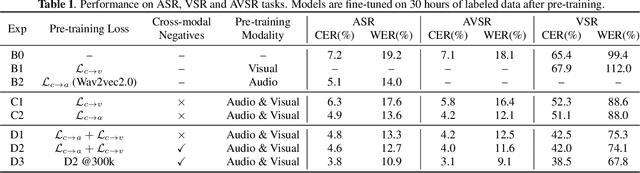

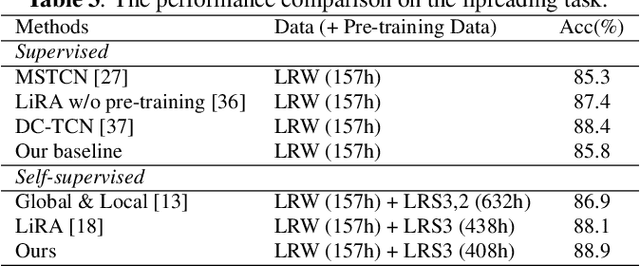
With the advance in self-supervised learning for audio and visual modalities, it has become possible to learn a robust audio-visual speech representation. This would be beneficial for improving the audio-visual speech recognition (AVSR) performance, as the multi-modal inputs contain more fruitful information in principle. In this paper, based on existing self-supervised representation learning methods for audio modality, we therefore propose an audio-visual representation learning approach. The proposed approach explores both the complementarity of audio-visual modalities and long-term context dependency using a transformer-based fusion module and a flexible masking strategy. After pre-training, the model is able to extract fused representations required by AVSR. Without loss of generality, it can be applied to single-modal tasks, e.g. audio/visual speech recognition by simply masking out one modality in the fusion module. The proposed pre-trained model is evaluated on speech recognition and lipreading tasks using one or two modalities, where the superiority is revealed.
A Noise-Robust Self-supervised Pre-training Model Based Speech Representation Learning for Automatic Speech Recognition
Jan 22, 2022


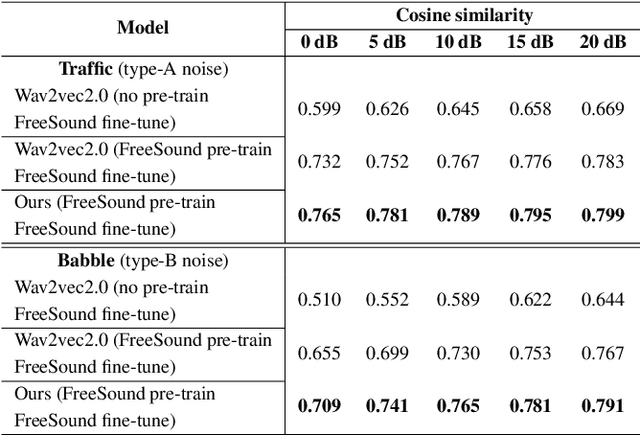
Wav2vec2.0 is a popular self-supervised pre-training framework for learning speech representations in the context of automatic speech recognition (ASR). It was shown that wav2vec2.0 has a good robustness against the domain shift, while the noise robustness is still unclear. In this work, we therefore first analyze the noise robustness of wav2vec2.0 via experiments. We observe that wav2vec2.0 pre-trained on noisy data can obtain good representations and thus improve the ASR performance on the noisy test set, which however brings a performance degradation on the clean test set. To avoid this issue, in this work we propose an enhanced wav2vec2.0 model. Specifically, the noisy speech and the corresponding clean version are fed into the same feature encoder, where the clean speech provides training targets for the model. Experimental results reveal that the proposed method can not only improve the ASR performance on the noisy test set which surpasses the original wav2vec2.0, but also ensure a tiny performance decrease on the clean test set. In addition, the effectiveness of the proposed method is demonstrated under different types of noise conditions.
XLST: Cross-lingual Self-training to Learn Multilingual Representation for Low Resource Speech Recognition
Mar 15, 2021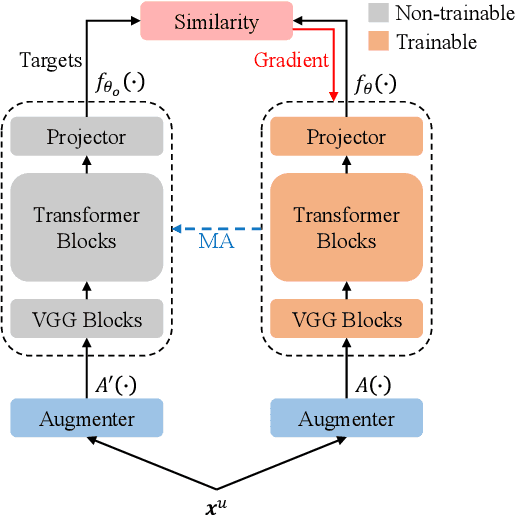
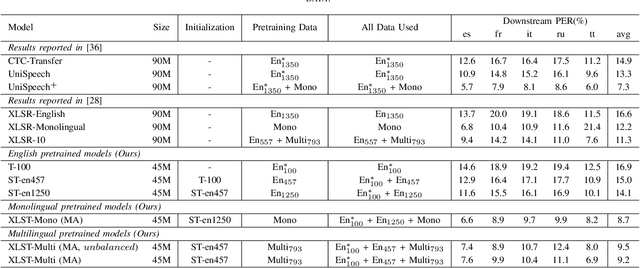
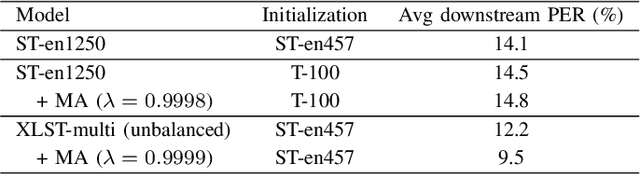

In this paper, we propose a weakly supervised multilingual representation learning framework, called cross-lingual self-training (XLST). XLST is able to utilize a small amount of annotated data from high-resource languages to improve the representation learning on multilingual un-annotated data. Specifically, XLST uses a supervised trained model to produce initial representations and another model to learn from them, by maximizing the similarity between output embeddings of these two models. Furthermore, the moving average mechanism and multi-view data augmentation are employed, which are experimentally shown to be crucial to XLST. Comprehensive experiments have been conducted on the CommonVoice corpus to evaluate the effectiveness of XLST. Results on 5 downstream low-resource ASR tasks shows that our multilingual pretrained model achieves relatively 18.6% PER reduction over the state-of-the-art self-supervised method, with leveraging additional 100 hours of annotated English data.