 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Training of Speech Enhancement and Self-supervised Model for Noise-robust ASR
Paper and Code
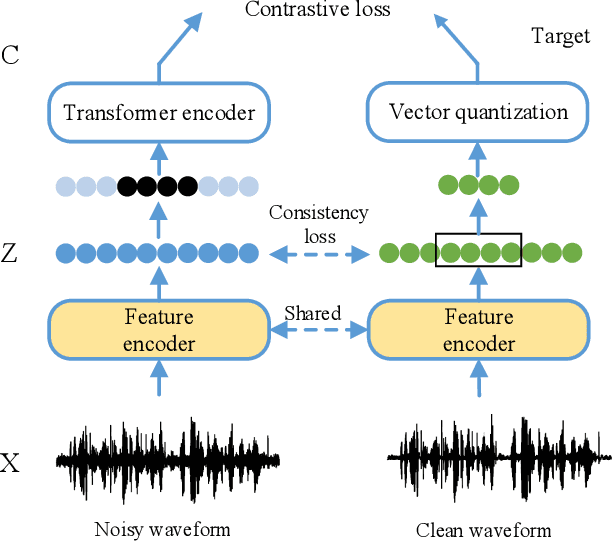
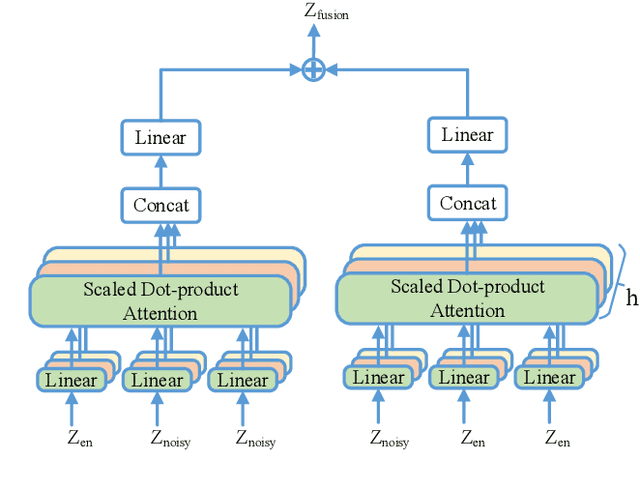
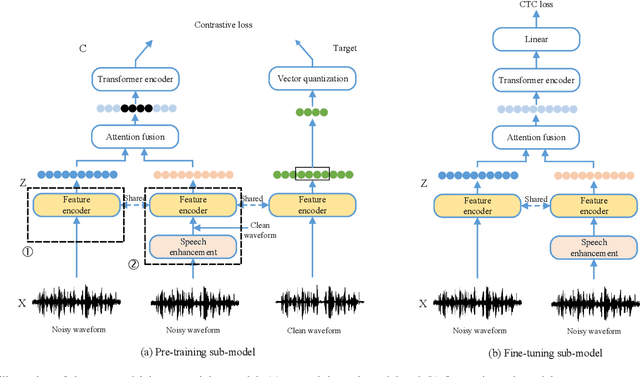
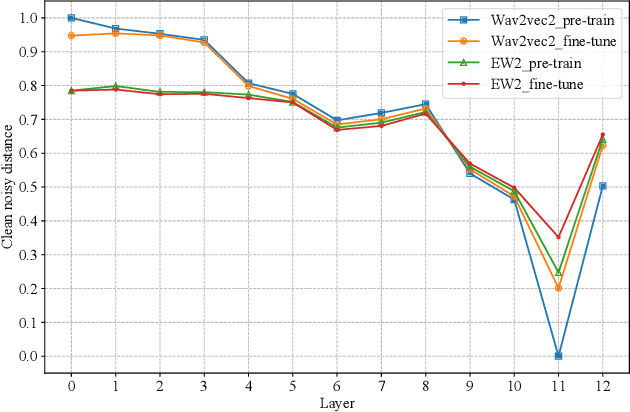
Speech enhancement (SE) is usually required as a front end to improve the speech quality in noisy environments, while the enhanced speech might not be optimal for automatic speech recognition (ASR) systems due to speech distortion. On the other hand, it was shown that self-supervised pre-training enables the utilization of a large amount of unlabeled noisy data, which is rather beneficial for the noise robustness of ASR. However, the potential of the (optimal) integration of SE and self-supervised pre-training still remains unclear. In order to find an appropriate combination and reduce the impact of speech distortion caused by SE, in this paper we therefore propose a joint pre-training approach for the SE module and the self-supervised model. First, in the pre-training phase the original noisy waveform or the waveform obtained by SE is fed into the self-supervised model to learn the contextual representation, where the quantified clean speech acts as the target. Second, we propose a dual-attention fusion method to fuse the features of noisy and enhanced speeches, which can compensate the information loss caused by separately using individual modules. Due to the flexible exploitation of clean/noisy/enhanced branches, the proposed method turns out to be a generalization of some existing noise-robust ASR models, e.g., enhanced wav2vec2.0. Finally, experimental results on both synthetic and real noisy datasets show that the proposed joint training approach can improve the ASR performance under various noisy settings, leading to a stronger noise robustness.