 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARS: Dysarthria-Aware Rhythm-Style Synthesis for ASR Enhancement
Mar 02, 2026Dysarthric speech exhibits abnormal prosody and significant speaker variability, presenting persistent challenges for automatic speech recognition (ASR). While text-to-speech (TTS)-based data augmentation has shown potential, existing methods often fail to accurately model the pathological rhythm and acoustic style of dysarthric speech. To address this, we propose DARS, a dysarthria-aware rhythm-style synthesis framework based on the Matcha-TTS architecture. DARS incorporates a multi-stage rhythm predictor optimized by contrastive preferences between normal and dysarthric speech, along with a dysarthric-style conditional flow matching mechanism, jointly enhancing temporal rhythm reconstruction and pathological acoustic style simulation. Experiments on the TORGO dataset demonstrate that DARS achieves a Mean Cepstral Distortion (MCD) of 4.29, closely approximating real dysarthric speech. Adapting a Whisper-based ASR system with synthetic dysarthric speech from DARS achieves a 54.22% relative reduction in word error rate (WER) compared to state-of-the-art methods, demonstrating the framework's effectiveness in enhancing recognition performance.
* Submitted to 2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC)
End-to-End Simultaneous Dysarthric Speech Reconstruction with Frame-Level Adaptor and Multiple Wait-k Knowledge Distillation
Mar 02, 2026Dysarthric speech reconstruction (DSR) typically employs a cascaded system that combines automatic speech recognition (ASR) and sentence-level text-to-speech (TTS) to convert dysarthric speech into normally-prosodied speech. However, dysarthric individuals often speak more slowly, leading to excessively long response times in such systems, rendering them impractical in long-speech scenarios. Cascaded DSR systems based on streaming ASR and incremental TTS can help reduce latency. However, patients with differing dysarthria severity exhibit substantial pronunciation variability for the same text, resulting in poor robustness of ASR and limiting the intelligibility of reconstructed speech. In addition, incremental TTS suffers from poor prosodic feature prediction due to a limited receptive field. In this study, we propose an end-to-end simultaneous DSR system with two key innovations: 1) A frame-level adaptor module is introduced to bridge ASR and TTS. By employing explicit-implicit semantic information fusion and joint module training, it enhances the error tolerance of TTS to ASR outputs. 2) A multiple wait-k autoregressive TTS module is designed to mitigate prosodic degradation via multi-view knowledge distillation. Our system has an average response time of 1.03 seconds on Tesla A100, with an average real-time factor (RTF) of 0.71. On the UASpeech dataset, it attains a mean opinion score (MOS) of 4.67 and demonstrates a 54.25% relative reduction in word error rate (WER) compared to the state-of-the-art. Our demo is available at: https://wflrz123.github.io/
* Submitted to 2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC)
The USTC-NERCSLIP Systems for The ICMC-ASR Challenge
Jul 02, 2024


This report describes the submitted system to the In-Car Multi-Channel Automatic Speech Recognition (ICMC-ASR) challenge, which considers the ASR task with multi-speaker overlapping and Mandarin accent dynamics in the ICMC case. We implement the front-end speaker diarization using the self-supervised learning representation based multi-speaker embedding and beamforming using the speaker position, respectively. For ASR, we employ an iterative pseudo-label generation method based on fusion model to obtain text labels of unsupervised data. To mitigate the impact of accent, an Accent-ASR framework is proposed, which captures pronunciation-related accent features at a fine-grained level and linguistic information at a coarse-grained level. On the ICMC-ASR eval set, the proposed system achieves a CER of 13.16% on track 1 and a cpCER of 21.48% on track 2, which significantly outperforms the official baseline system and obtains the first rank on both tracks.
The USTC-NERCSLIP Systems for the CHiME-7 DASR Challenge
Aug 28, 2023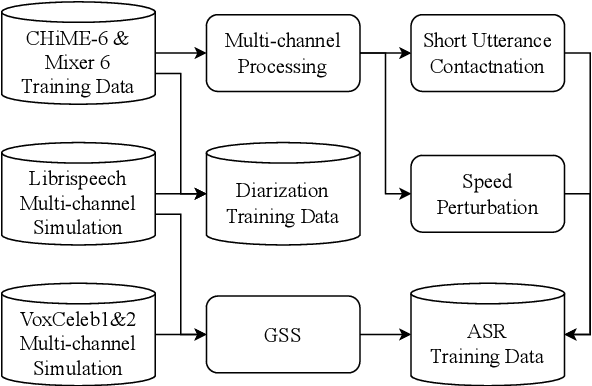
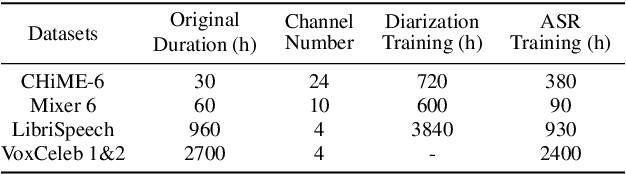
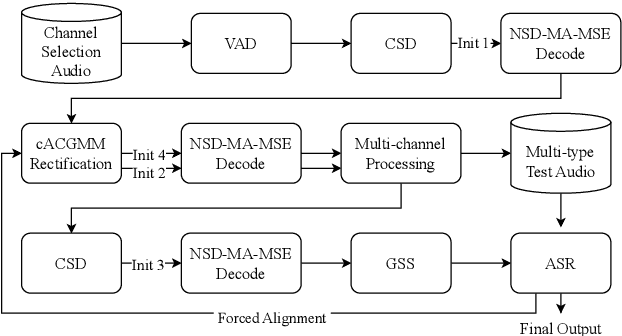
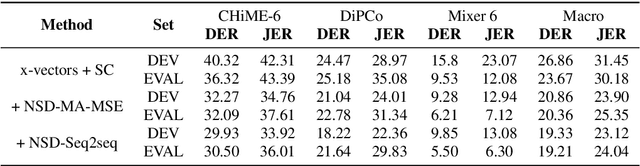
This technical report details our submission system to the CHiME-7 DASR Challenge, which focuses on speaker diarization and speech recognition under complex multi-speaker settings. Additionally, it also evaluates the efficiency of systems in handling diverse array devices. To address these issues, we implemented an end-to-end speaker diarization system and introduced a rectification strategy based on multi-channel spatial information. This approach significantly diminished the word error rates (WER). In terms of recognition, we utilized publicly available pre-trained models as the foundational models to train our end-to-end speech recognition models. Our system attained a macro-averaged diarization-attributed WER (DA-WER) of 22.4\% on the CHiME-7 development set, which signifies a relative improvement of 52.5\% over the official baseline system.
Semi-supervised multi-channel speaker diarization with cross-channel attention
Jul 17, 2023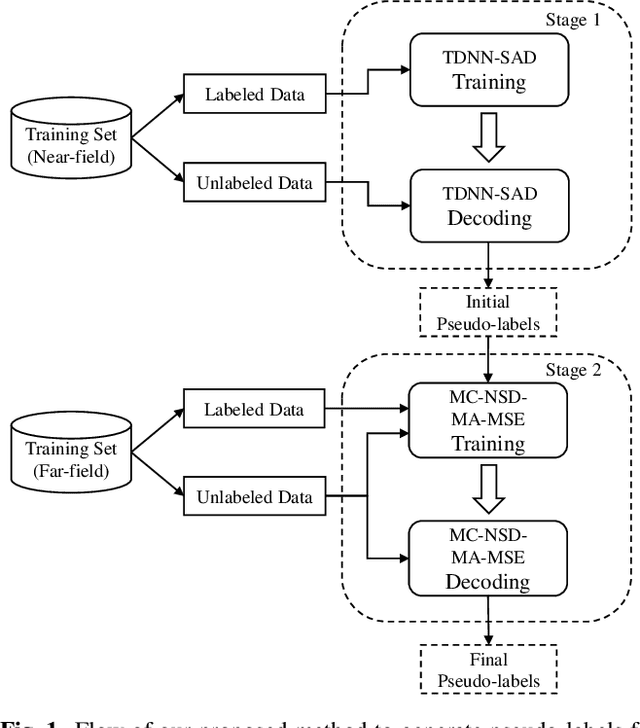
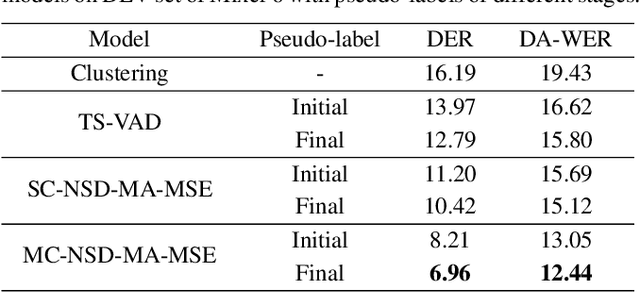

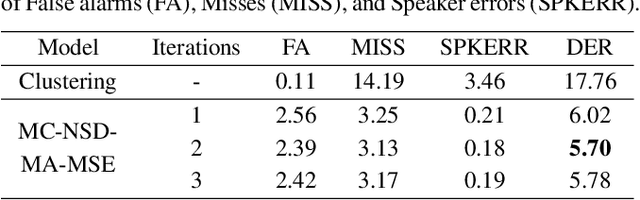
Most neural speaker diarization systems rely on sufficient manual training data labels, which are hard to collect under real-world scenarios. This paper proposes a semi-supervised speaker diarization system to utilize large-scale multi-channel training data by generating pseudo-labels for unlabeled data. Furthermore, we introduce cross-channel attention into the Neural Speaker Diarization Using Memory-Aware Multi-Speaker Embedding (NSD-MA-MSE) to learn channel contextual information of speaker embeddings better. Experimental results on the CHiME-7 Mixer6 dataset which only contains partial speakers' labels of the training set, show that our system achieved 57.01% relative DER reduction compared to the clustering-based model on the development set. We further conducted experiments on the CHiME-6 dataset to simulate the scenario of missing partial training set labels. When using 80% and 50% labeled training data, our system performs comparably to the results obtained using 100% labeled data for training.
Reducing the gap between streaming and non-streaming Transducer-based ASR by adaptive two-stage knowledge distillation
Jun 27, 2023Transducer is one of the mainstream frameworks for streaming speech recognition. There is a performance gap between the streaming and non-streaming transducer models due to limited context. To reduce this gap, an effective way is to ensure that their hidden and output distributions are consistent, which can be achieved by hierarchical knowledge distillation. However, it is difficult to ensure the distribution consistency simultaneously because the learning of the output distribution depends on the hidden one. In this paper, we propose an adaptive two-stage knowledge distillation method consisting of hidden layer learning and output layer learning. In the former stage, we learn hidden representation with full context by applying mean square error loss function. In the latter stage, we design a power transformation based adaptive smoothness method to learn stable output distribution. It achieved 19\% relative reduction in word error rate, and a faster response for the first token compared with the original streaming model in LibriSpeech corpus.