 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamingClaw Technical Report
Mar 23, 2026Applications such as embodied intelligence rely on a real-time perception-decision-action closed loop, posing stringent challenges for streaming video understanding. However, current agents suffer from fragmented capabilities, such as supporting only offline video understanding, lacking long-term multimodal memory mechanisms, or struggling to achieve real-time reasoning and proactive interaction under streaming inputs. These shortcomings have become a key bottleneck for preventing them from sustaining perception, making real-time decisions, and executing actions in real-world environments. To alleviate these issues, we propose StreamingClaw, a unified agent framework for streaming video understanding and embodied intelligence. It is also an OpenClaw-compatible framework that supports real-time, multimodal streaming interaction. StreamingClaw integrates five core capabilities: (1) It supports real-time streaming reasoning. (2) It supports reasoning about future events and proactive interaction under the online evolution of interaction objectives. (3) It supports multimodal long-term storage, hierarchical evolution, and efficient retrieval of shared memory across multiple agents. (4) It supports a closed-loop of perception-decision-action. In addition to conventional tools and skills, it also provides streaming tools and action-centric skills tailored for real-world physical environments. (5) It is compatible with the OpenClaw framework, allowing it to fully leverage the resources and support of the open-source community. With these designs, StreamingClaw integrates online real-time reasoning, multimodal long-term memory, and proactive interaction within a unified framework. Moreover, by translating decisions into executable actions, it enables direct control of the physical world, supporting practical deployment of embodied interaction.
Exploring Speaker Diarization with Mixture of Experts
Jun 17, 2025In this paper, we propose a novel neural speaker diarization system using memory-aware multi-speaker embedding with sequence-to-sequence architecture (NSD-MS2S), which integrates a memory-aware multi-speaker embedding module with a sequence-to-sequence architecture. The system leverages a memory module to enhance speaker embeddings and employs a Seq2Seq framework to efficiently map acoustic features to speaker labels. Additionally, we explore the application of mixture of experts in speaker diarization, and introduce a Shared and Soft Mixture of Experts (SS-MoE) module to further mitigate model bias and enhance performance. Incorporating SS-MoE leads to the extended model NSD-MS2S-SSMoE. Experiments on multiple complex acoustic datasets, including CHiME-6, DiPCo, Mixer 6 and DIHARD-III evaluation sets, demonstrate meaningful improvements in robustness and generalization. The proposed methods achieve state-of-the-art results, showcasing their effectiveness in challenging real-world scenarios.
Neural Speaker Diarization Using Memory-Aware Multi-Speaker Embedding with Sequence-to-Sequence Architecture
Sep 17, 2023



We propose a novel neural speaker diarization system using memory-aware multi-speaker embedding with sequence-to-sequence architecture (NSD-MS2S), which integrates the strengths of memory-aware multi-speaker embedding (MA-MSE) and sequence-to-sequence (Seq2Seq) architecture, leading to improvement in both efficiency and performance. Next, we further decrease the memory occupation of decoding by incorporating input features fusion and then employ a multi-head attention mechanism to capture features at different levels. NSD-MS2S achieved a macro diarization error rate (DER) of 15.9% on the CHiME-7 EVAL set, which signifies a relative improvement of 49% over the official baseline system, and is the key technique for us to achieve the best performance for the main track of CHiME-7 DASR Challenge. Additionally, we introduce a deep interactive module (DIM) in MA-MSE module to better retrieve a cleaner and more discriminative multi-speaker embedding, enabling the current model to outperform the system we used in the CHiME-7 DASR Challenge. Our code will be available at https://github.com/liyunlongaaa/NSD-MS2S.
The USTC-NERCSLIP Systems for the CHiME-7 DASR Challenge
Aug 28, 2023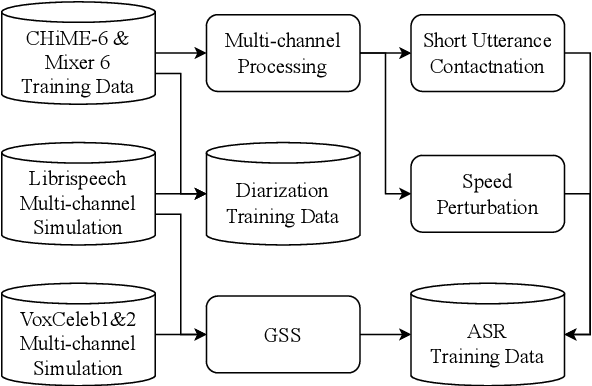
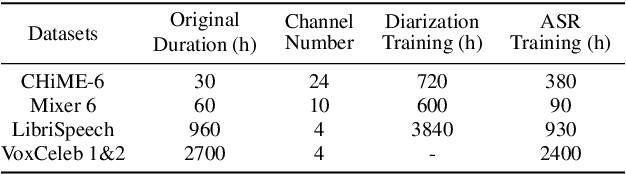
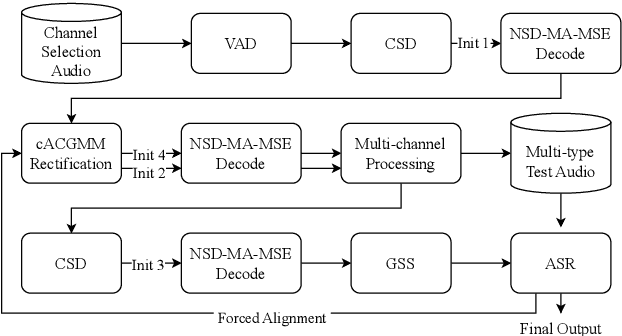
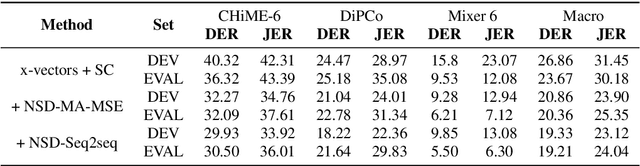
This technical report details our submission system to the CHiME-7 DASR Challenge, which focuses on speaker diarization and speech recognition under complex multi-speaker settings. Additionally, it also evaluates the efficiency of systems in handling diverse array devices. To address these issues, we implemented an end-to-end speaker diarization system and introduced a rectification strategy based on multi-channel spatial information. This approach significantly diminished the word error rates (WER). In terms of recognition, we utilized publicly available pre-trained models as the foundational models to train our end-to-end speech recognition models. Our system attained a macro-averaged diarization-attributed WER (DA-WER) of 22.4\% on the CHiME-7 development set, which signifies a relative improvement of 52.5\% over the official baseline system.
Semi-supervised multi-channel speaker diarization with cross-channel attention
Jul 17, 2023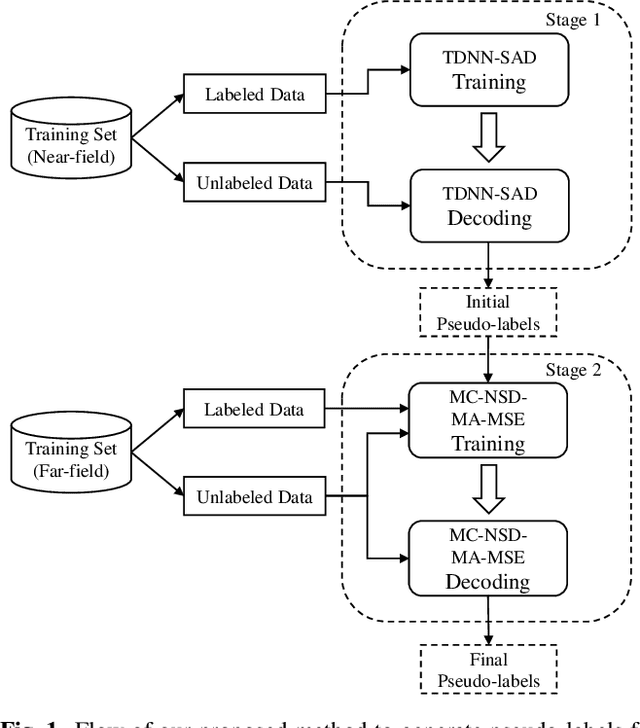
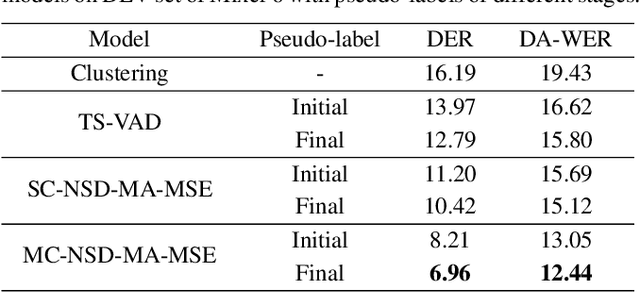

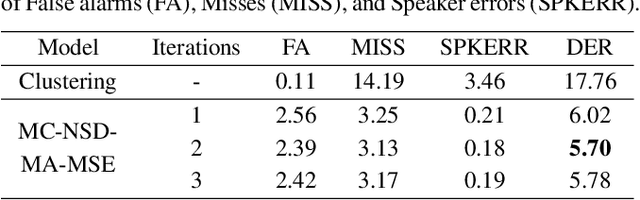
Most neural speaker diarization systems rely on sufficient manual training data labels, which are hard to collect under real-world scenarios. This paper proposes a semi-supervised speaker diarization system to utilize large-scale multi-channel training data by generating pseudo-labels for unlabeled data. Furthermore, we introduce cross-channel attention into the Neural Speaker Diarization Using Memory-Aware Multi-Speaker Embedding (NSD-MA-MSE) to learn channel contextual information of speaker embeddings better. Experimental results on the CHiME-7 Mixer6 dataset which only contains partial speakers' labels of the training set, show that our system achieved 57.01% relative DER reduction compared to the clustering-based model on the development set. We further conducted experiments on the CHiME-6 dataset to simulate the scenario of missing partial training set labels. When using 80% and 50% labeled training data, our system performs comparably to the results obtained using 100% labeled data for training.
The USTC-Ximalaya system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 10, 2022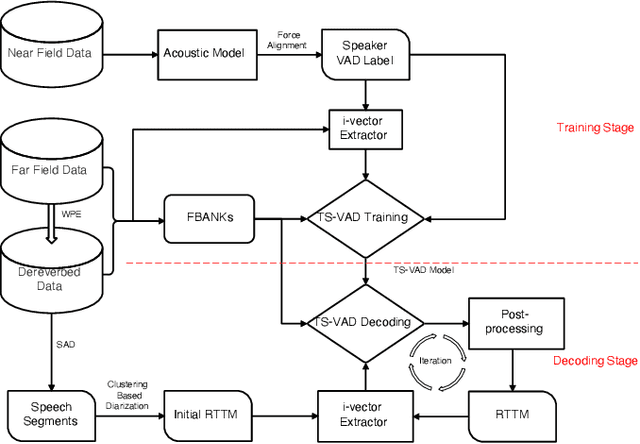
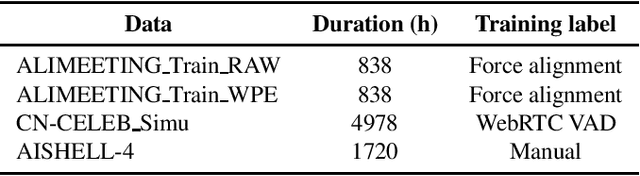
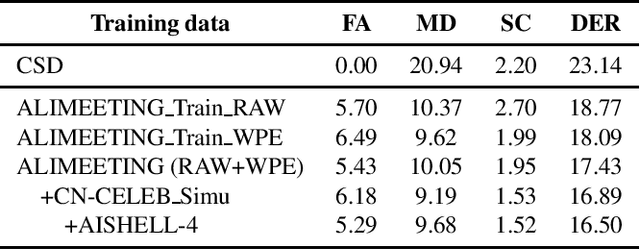
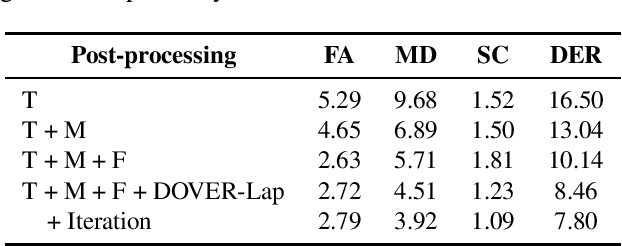
We propose two improvements to target-speaker voice activity detection (TS-VAD), the core component in our proposed speaker diarization system that was submitted to the 2022 Multi-Channel Multi-Party Meeting Transcription (M2MeT) challenge. These techniques are designed to handle multi-speaker conversations in real-world meeting scenarios with high speaker-overlap ratios and under heavy reverberant and noisy condition. First, for data preparation and augmentation in training TS-VAD models, speech data containing both real meetings and simulated indoor conversations are used. Second, in refining results obtained after TS-VAD based decoding, we perform a series of post-processing steps to improve the VAD results needed to reduce diarization error rates (DERs). Tested on the ALIMEETING corpus, the newly released Mandarin meeting dataset used in M2MeT, we demonstrate that our proposed system can decrease the DER by up to 66.55/60.59% relatively when compared with classical clustering based diarization on the Eval/Test set.
Target-speaker Voice Activity Detection with Improved I-Vector Estimation for Unknown Number of Speaker
Aug 07, 2021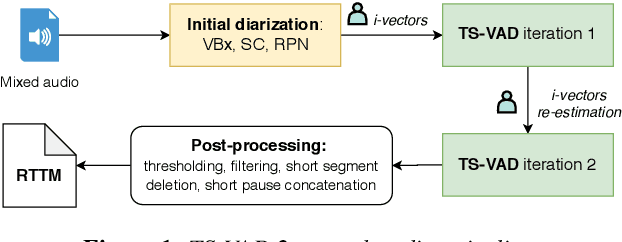
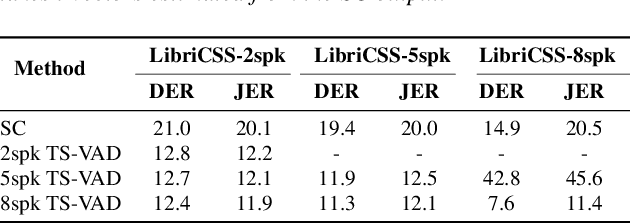
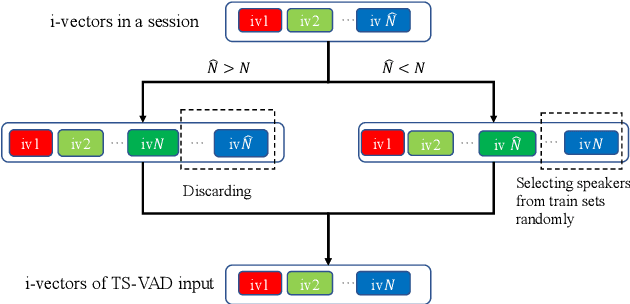
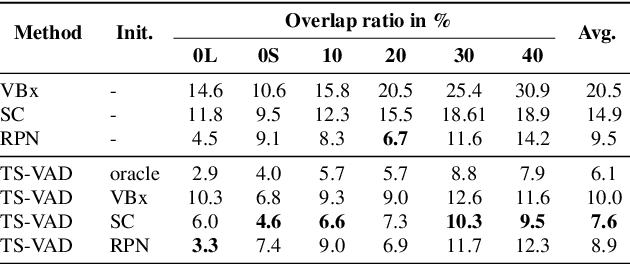
Target-speaker voice activity detection (TS-VAD) has recently shown promising results for speaker diarization on highly overlapped speech. However, the original model requires a fixed (and known) number of speakers, which limits its application to real conversations. In this paper, we extend TS-VAD to speaker diarization with unknown numbers of speakers. This is achieved by two steps: first, an initial diarization system is applied for speaker number estimation, followed by TS-VAD network output masking according to this estimate. We further investigate different diarization methods, including clustering-based and region proposal networks, for estimating the initial i-vectors. Since these systems have complementary strengths, we propose a fusion-based method to combine frame-level decisions from the systems for an improved initialization. We demonstrate through experiments on variants of the LibriCSS meeting corpus that our proposed approach can improve the DER by up to 50\% relative across varying numbers of speakers. This improvement also results in better downstream ASR performance approaching that using oracle segments.
USTC-NELSLIP System Description for DIHARD-III Challenge
Mar 19, 2021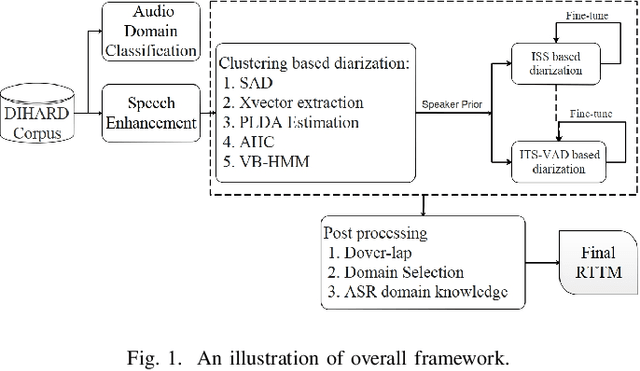
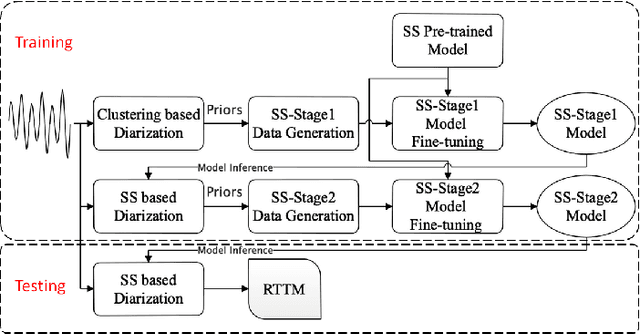
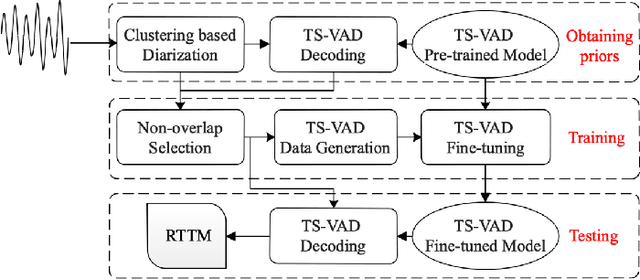
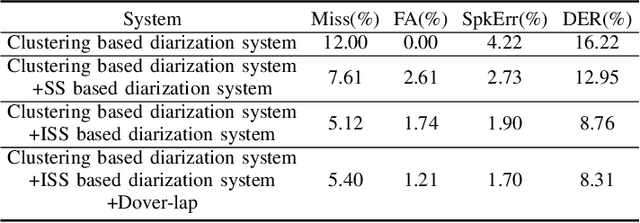
This system description describes our submission system to the Third DIHARD Speech Diarization Challenge. Besides the traditional clustering based system, the innovation of our system lies in the combination of various front-end techniques to solve the diarization problem, including speech separation and target-speaker based voice activity detection (TS-VAD), combined with iterative data purification. We also adopted audio domain classification to design domain-dependent processing. Finally, we performed post processing to do system fusion and selection. Our best system achieved DERs of 11.30% in track 1 and 16.78% in track 2 on evaluation set, respectively.