 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget-speaker Voice Activity Detection with Improved I-Vector Estimation for Unknown Number of Speaker
Paper and Code
Aug 07, 2021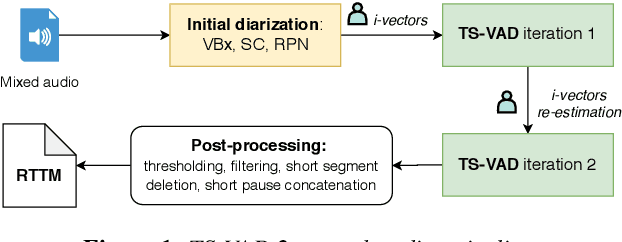
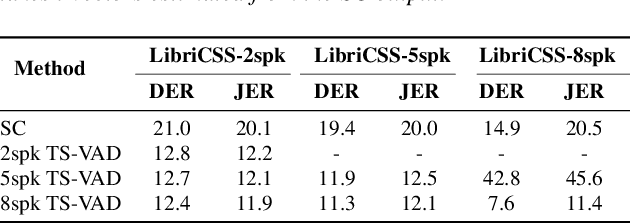
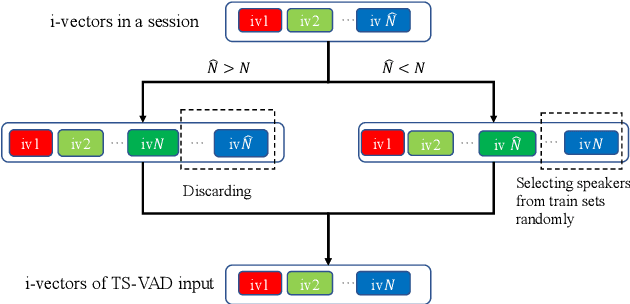
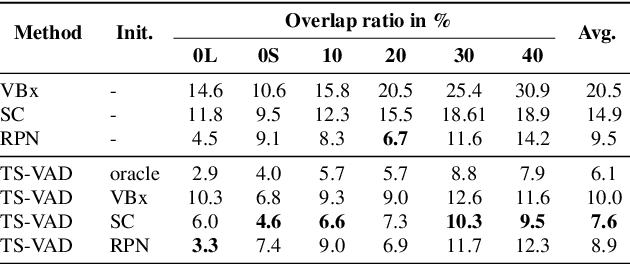
Target-speaker voice activity detection (TS-VAD) has recently shown promising results for speaker diarization on highly overlapped speech. However, the original model requires a fixed (and known) number of speakers, which limits its application to real conversations. In this paper, we extend TS-VAD to speaker diarization with unknown numbers of speakers. This is achieved by two steps: first, an initial diarization system is applied for speaker number estimation, followed by TS-VAD network output masking according to this estimate. We further investigate different diarization methods, including clustering-based and region proposal networks, for estimating the initial i-vectors. Since these systems have complementary strengths, we propose a fusion-based method to combine frame-level decisions from the systems for an improved initialization. We demonstrate through experiments on variants of the LibriCSS meeting corpus that our proposed approach can improve the DER by up to 50\% relative across varying numbers of speakers. This improvement also results in better downstream ASR performance approaching that using oracle segments.