 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVER: Dynamic Iterative Visual Evidence Reasoning for Multimodal Fake News Detection
Jan 12, 2026Multimodal fake news detection is crucial for mitigating adversarial misinformation. Existing methods, relying on static fusion or LLMs, face computational redundancy and hallucination risks due to weak visual foundations. To address this, we propose DIVER (Dynamic Iterative Visual Evidence Reasoning), a framework grounded in a progressive, evidence-driven reasoning paradigm. DIVER first establishes a strong text-based baseline through language analysis, leveraging intra-modal consistency to filter unreliable or hallucinated claims. Only when textual evidence is insufficient does the framework introduce visual information, where inter-modal alignment verification adaptively determines whether deeper visual inspection is necessary. For samples exhibiting significant cross-modal semantic discrepancies, DIVER selectively invokes fine-grained visual tools (e.g., OCR and dense captioning) to extract task-relevant evidence, which is iteratively aggregated via uncertainty-aware fusion to refine multimodal reasoning. Experiments on Weibo, Weibo21, and GossipCop demonstrate that DIVER outperforms state-of-the-art baselines by an average of 2.72\%, while optimizing inference efficiency with a reduced latency of 4.12 s.
Disentangling Fact from Sentiment: A Dynamic Conflict-Consensus Framework for Multimodal Fake News Detection
Dec 19, 2025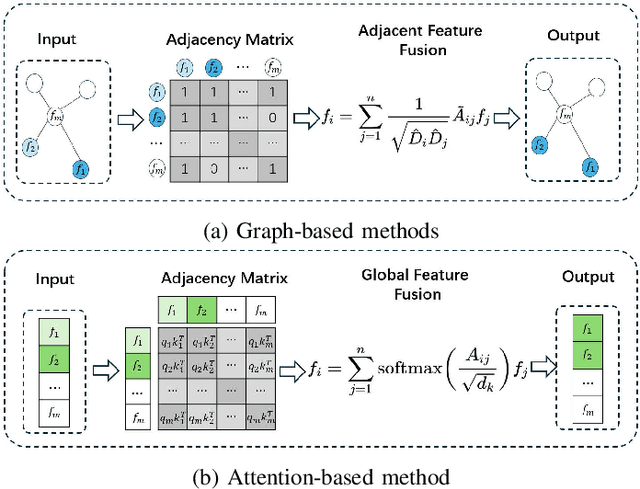
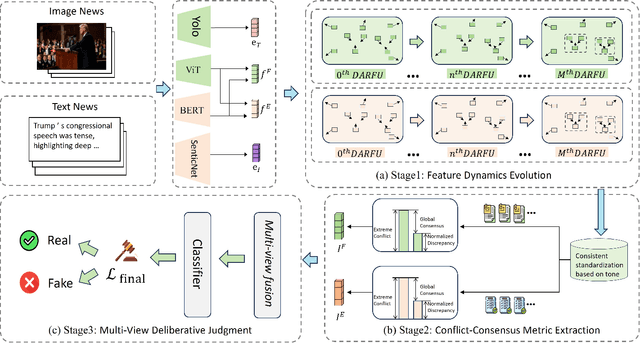
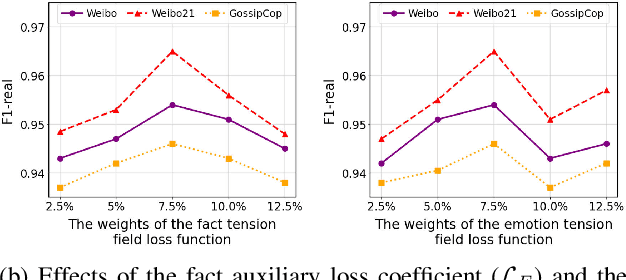
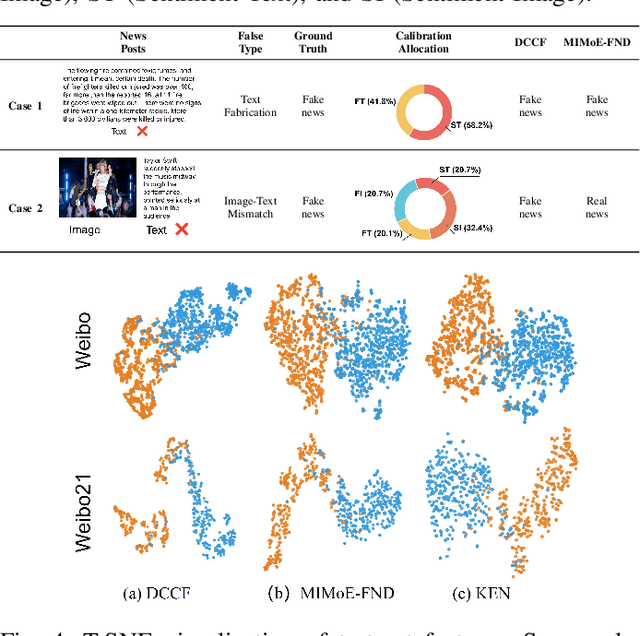
Prevalent multimodal fake news detection relies on consistency-based fusion, yet this paradigm fundamentally misinterprets critical cross-modal discrepancies as noise, leading to over-smoothing, which dilutes critical evidence of fabrication. Mainstream consistency-based fusion inherently minimizes feature discrepancies to align modalities, yet this approach fundamentally fails because it inadvertently smoothes out the subtle cross-modal contradictions that serve as the primary evidence of fabrication. To address this, we propose the Dynamic Conflict-Consensus Framework (DCCF), an inconsistency-seeking paradigm designed to amplify rather than suppress contradictions. First, DCCF decouples inputs into independent Fact and Sentiment spaces to distinguish objective mismatches from emotional dissonance. Second, we employ physics-inspired feature dynamics to iteratively polarize these representations, actively extracting maximally informative conflicts. Finally, a conflict-consensus mechanism standardizes these local discrepancies against the global context for robust deliberative judgment.Extensive experiments conducted on three real world datasets demonstrate that DCCF consistently outperforms state-of-the-art baselines, achieving an average accuracy improvement of 3.52\%.
The USTC-Ximalaya system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 10, 2022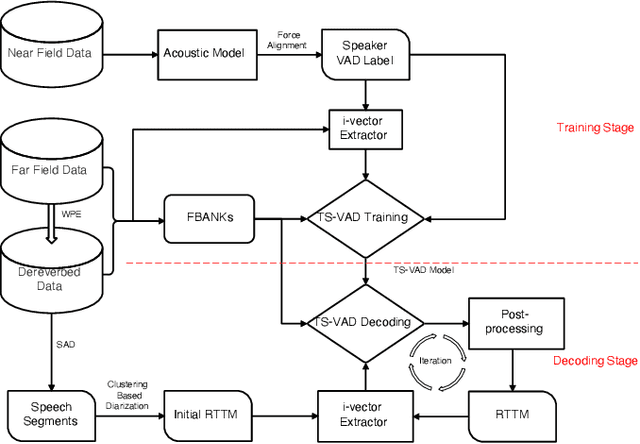
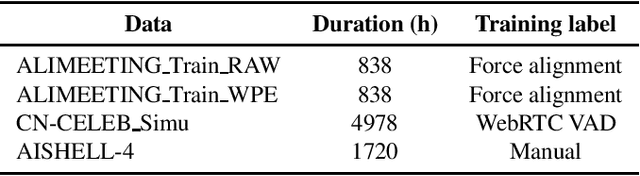
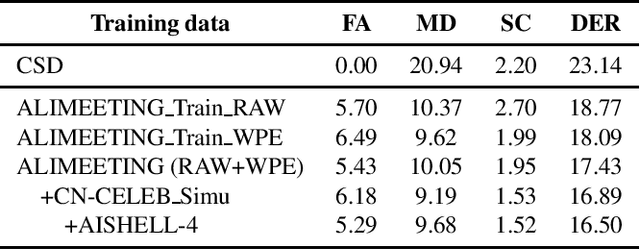
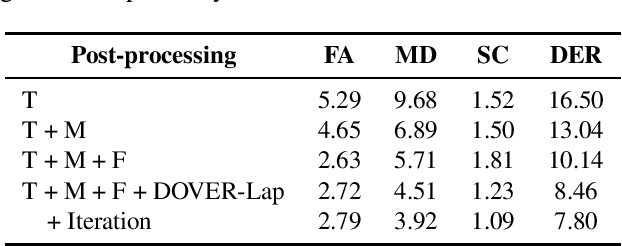
We propose two improvements to target-speaker voice activity detection (TS-VAD), the core component in our proposed speaker diarization system that was submitted to the 2022 Multi-Channel Multi-Party Meeting Transcription (M2MeT) challenge. These techniques are designed to handle multi-speaker conversations in real-world meeting scenarios with high speaker-overlap ratios and under heavy reverberant and noisy condition. First, for data preparation and augmentation in training TS-VAD models, speech data containing both real meetings and simulated indoor conversations are used. Second, in refining results obtained after TS-VAD based decoding, we perform a series of post-processing steps to improve the VAD results needed to reduce diarization error rates (DERs). Tested on the ALIMEETING corpus, the newly released Mandarin meeting dataset used in M2MeT, we demonstrate that our proposed system can decrease the DER by up to 66.55/60.59% relatively when compared with classical clustering based diarization on the Eval/Test set.
Adaptive Bayesian Linear Regression for Automated Machine Learning
Apr 18, 2019
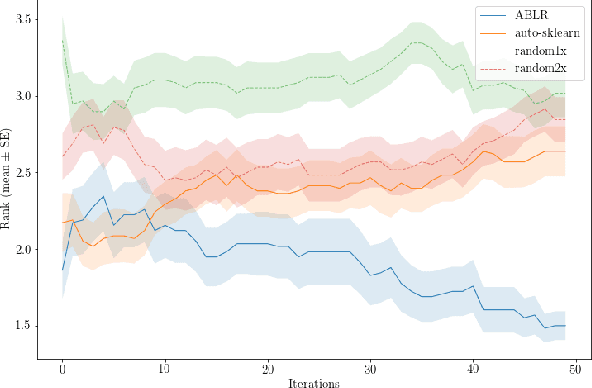
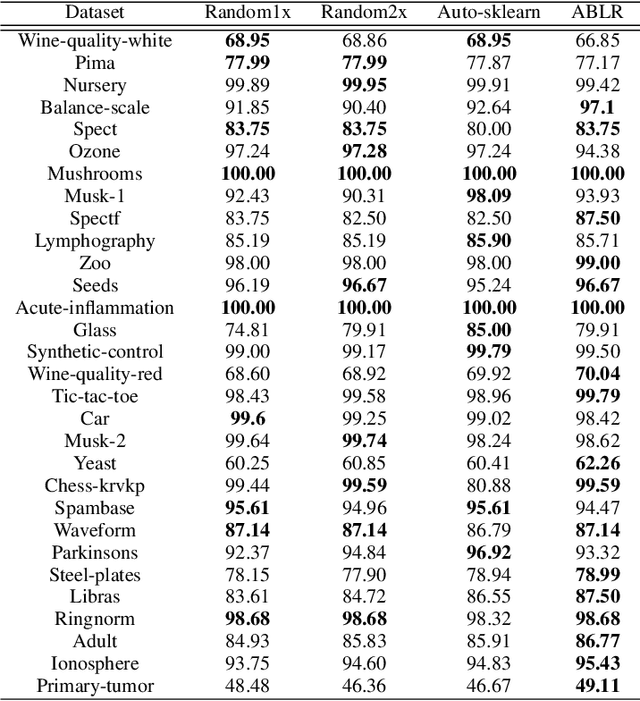
To solve a machine learning problem, one typically needs to perform data preprocessing, modeling, and hyperparameter tuning, which is known as model selection and hyperparameter optimization.The goal of automated machine learning (AutoML) is to design methods that can automatically perform model selection and hyperparameter optimization without human interventions for a given dataset. In this paper, we propose a meta-learning method that can search for a high-performance machine learning pipeline from the predefined set of candidate pipelines for supervised classification datasets in an efficient way by leveraging meta-data collected from previous experiments. More specifically, our method combines an adaptive Bayesian regression model with a neural network basis function and the acquisition function from Bayesian optimization. The adaptive Bayesian regression model is able to capture knowledge from previous meta-data and thus make predictions of the performances of machine learning pipelines on a new dataset. The acquisition function is then used to guide the search of possible pipelines based on the predictions.The experiments demonstrate that our approach can quickly identify high-performance pipelines for a range of test datasets and outperforms the baseline methods.