 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe USTC-Ximalaya system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 10, 2022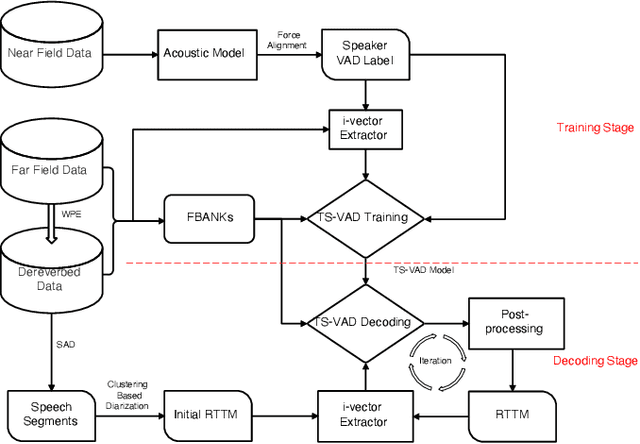
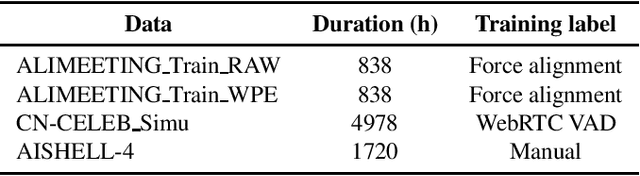
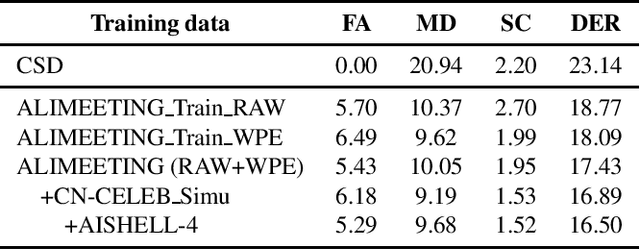
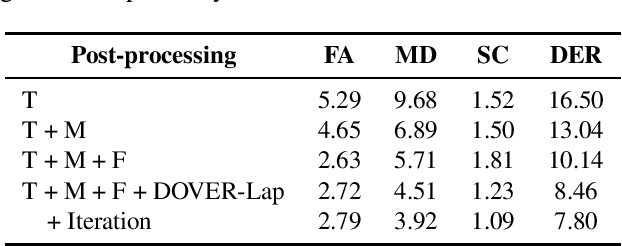
We propose two improvements to target-speaker voice activity detection (TS-VAD), the core component in our proposed speaker diarization system that was submitted to the 2022 Multi-Channel Multi-Party Meeting Transcription (M2MeT) challenge. These techniques are designed to handle multi-speaker conversations in real-world meeting scenarios with high speaker-overlap ratios and under heavy reverberant and noisy condition. First, for data preparation and augmentation in training TS-VAD models, speech data containing both real meetings and simulated indoor conversations are used. Second, in refining results obtained after TS-VAD based decoding, we perform a series of post-processing steps to improve the VAD results needed to reduce diarization error rates (DERs). Tested on the ALIMEETING corpus, the newly released Mandarin meeting dataset used in M2MeT, we demonstrate that our proposed system can decrease the DER by up to 66.55/60.59% relatively when compared with classical clustering based diarization on the Eval/Test set.