 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Multi-Functional LAWNs with ISAC: Opportunities, Challenges, and the Road Ahead
Aug 24, 2025



Integrated sensing and communication (ISAC) has been envisioned as a foundational technology for future low-altitude wireless networks (LAWNs), enabling real-time environmental perception and data exchange across aerial-ground systems. In this article, we first explore the roles of ISAC in LAWNs from both node-level and network-level perspectives. We highlight the performance gains achieved through hierarchical integration and cooperation, wherein key design trade-offs are demonstrated. Apart from physical-layer enhancements, emerging LAWN applications demand broader functionalities. To this end, we propose a multi-functional LAWN framework that extends ISAC with capabilities in control, computation, wireless power transfer, and large language model (LLM)-based intelligence. We further provide a representative case study to present the benefits of ISAC-enabled LAWNs and the promising research directions are finally outlined.
Deep Learning-based OTFS Channel Estimation and Symbol Detection with Plug and Play Framework
Mar 14, 2025



Orthogonal Time Frequency Space (OTFS) modulation has recently attracted significant interest due to its potential for enabling reliable communication in high-mobility environments. One of the challenges for OTFS receivers is the fractional Doppler that occurs in practical systems, resulting in decreased channel sparsity, and then inaccurate channel estimation and high-complexity equalization. In this paper, we propose a novel unsupervised deep learning (DL)-based OTFS channel estimation and symbol detection scheme, capable of handling different channel conditions, even in the presence of fractional Doppler. In particular, we design a unified plug-and-play (PnP) framework, which can jointly exploit the flexibility of optimization-based methods and utilize the powerful data-driven capability of DL. A lightweight Unet is integrated into the framework as a powerful implicit channel prior for channel estimation, leading to better exploitation of the channel sparsity and the characteristic of the noise simultaneously. Furthermore, to mitigate the channel estimation errors, we realize the PnP framework with a fully connected (FC) network for symbol detection at different noise levels, thereby enhancing robustness. Finally, numerical results demonstrate the effectiveness and robustness of the algorithm.
14 Examples of How LLMs Can Transform Materials Science and Chemistry: A Reflection on a Large Language Model Hackathon
Jun 13, 2023



Chemistry and materials science are complex. Recently, there have been great successes in addressing this complexity using data-driven or computational techniques. Yet, the necessity of input structured in very specific forms and the fact that there is an ever-growing number of tools creates usability and accessibility challenges. Coupled with the reality that much data in these disciplines is unstructured, the effectiveness of these tools is limited. Motivated by recent works that indicated that large language models (LLMs) might help address some of these issues, we organized a hackathon event on the applications of LLMs in chemistry, materials science, and beyond. This article chronicles the projects built as part of this hackathon. Participants employed LLMs for various applications, including predicting properties of molecules and materials, designing novel interfaces for tools, extracting knowledge from unstructured data, and developing new educational applications. The diverse topics and the fact that working prototypes could be generated in less than two days highlight that LLMs will profoundly impact the future of our fields. The rich collection of ideas and projects also indicates that the applications of LLMs are not limited to materials science and chemistry but offer potential benefits to a wide range of scientific disciplines.
The USTC-Ximalaya system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 10, 2022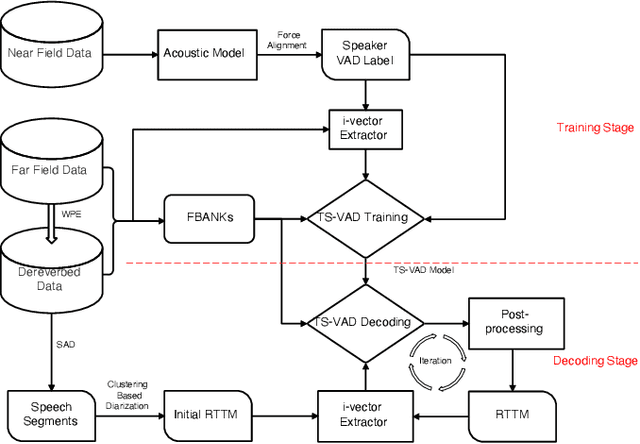
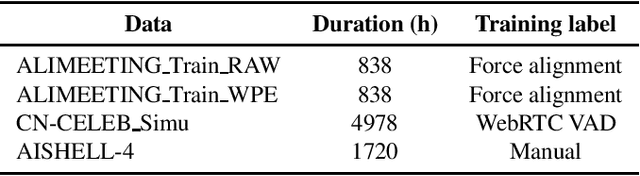
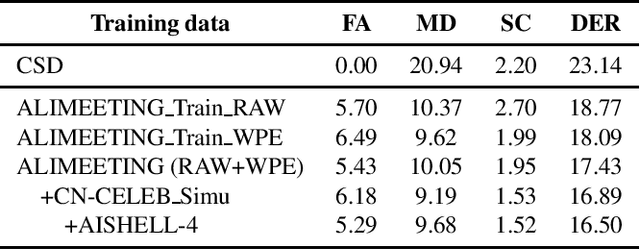
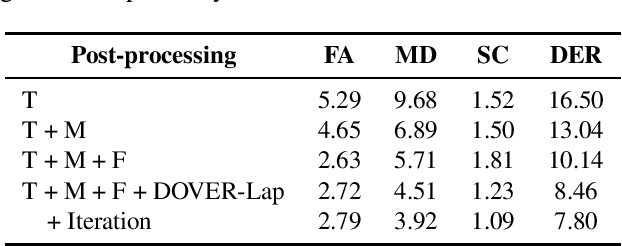
We propose two improvements to target-speaker voice activity detection (TS-VAD), the core component in our proposed speaker diarization system that was submitted to the 2022 Multi-Channel Multi-Party Meeting Transcription (M2MeT) challenge. These techniques are designed to handle multi-speaker conversations in real-world meeting scenarios with high speaker-overlap ratios and under heavy reverberant and noisy condition. First, for data preparation and augmentation in training TS-VAD models, speech data containing both real meetings and simulated indoor conversations are used. Second, in refining results obtained after TS-VAD based decoding, we perform a series of post-processing steps to improve the VAD results needed to reduce diarization error rates (DERs). Tested on the ALIMEETING corpus, the newly released Mandarin meeting dataset used in M2MeT, we demonstrate that our proposed system can decrease the DER by up to 66.55/60.59% relatively when compared with classical clustering based diarization on the Eval/Test set.
Lookup subnet based Spatial Graph Convolutional neural Network
Feb 04, 2021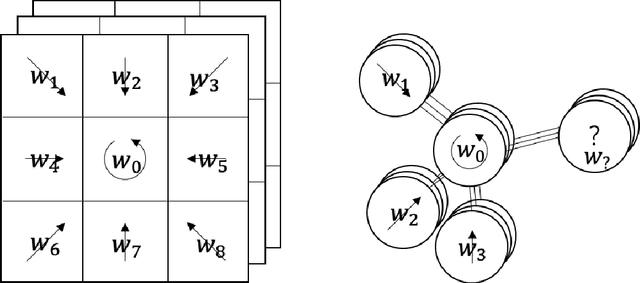

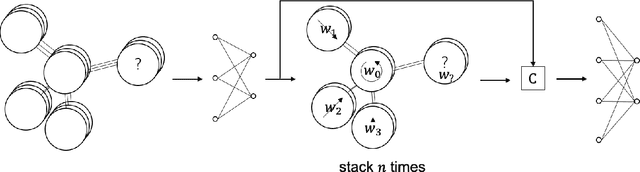

Convolutional Neural Networks(CNNs) has achieved remarkable performance breakthrough in Euclidean structure data. Recently, aggregation-transformation based Graph Neural networks(GNNs) gradually produce a powerful performance on non-Euclidean data. In this paper, we propose a cross-correlation based graph convolution method allowing to naturally generalize CNNs to non-Euclidean domains and inherit the excellent natures of CNNs, such as local filters, parameter sharing, flexible receptive field, etc. Meanwhile, it leverages dynamically generated convolution kernel and cross-correlation operators to address the shortcomings of prior methods based on aggregation-transformation or their approximations. Our method has achieved or matched popular state-of-the-art results across three established graph benchmarks: the Cora, Citeseer, and Pubmed citation network datasets.