 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Audio-Visual Information Fusion with Multi-label Joint Decoding for MER 2023
Sep 11, 2023



In this paper, we propose a novel framework for recognizing both discrete and dimensional emotions. In our framework, deep features extracted from foundation models are used as robust acoustic and visual representations of raw video. Three different structures based on attention-guided feature gathering (AFG) are designed for deep feature fusion. Then, we introduce a joint decoding structure for emotion classification and valence regression in the decoding stage. A multi-task loss based on uncertainty is also designed to optimize the whole process. Finally, by combining three different structures on the posterior probability level, we obtain the final predictions of discrete and dimensional emotions. When tested on the dataset of multimodal emotion recognition challenge (MER 2023), the proposed framework yields consistent improvements in both emotion classification and valence regression. Our final system achieves state-of-the-art performance and ranks third on the leaderboard on MER-MULTI sub-challenge.
* 5 pages, 4 figures
The USTC-NERCSLIP Systems for the CHiME-7 DASR Challenge
Aug 28, 2023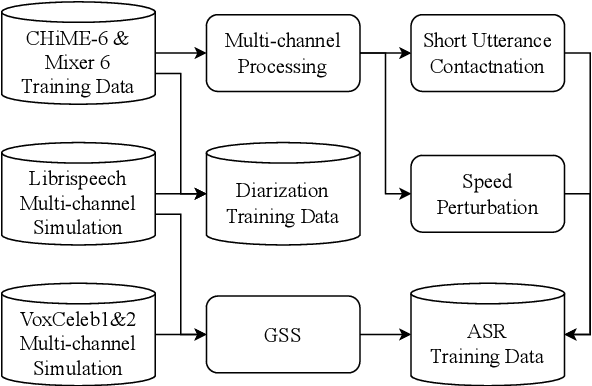
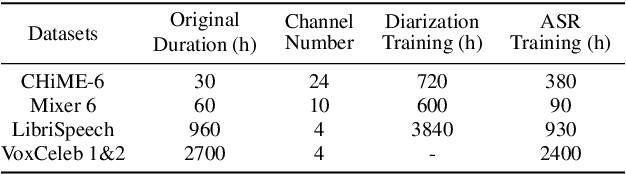
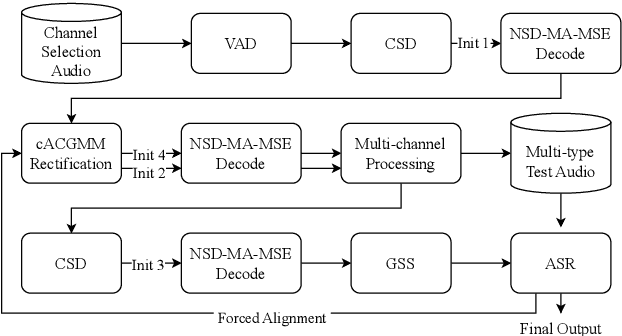
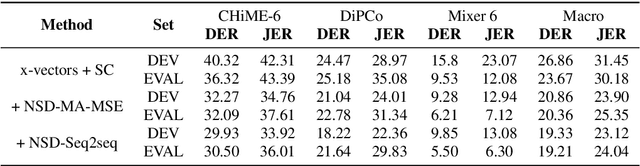
This technical report details our submission system to the CHiME-7 DASR Challenge, which focuses on speaker diarization and speech recognition under complex multi-speaker settings. Additionally, it also evaluates the efficiency of systems in handling diverse array devices. To address these issues, we implemented an end-to-end speaker diarization system and introduced a rectification strategy based on multi-channel spatial information. This approach significantly diminished the word error rates (WER). In terms of recognition, we utilized publicly available pre-trained models as the foundational models to train our end-to-end speech recognition models. Our system attained a macro-averaged diarization-attributed WER (DA-WER) of 22.4\% on the CHiME-7 development set, which signifies a relative improvement of 52.5\% over the official baseline system.
A Study of Designing Compact Audio-Visual Wake Word Spotting System Based on Iterative Fine-Tuning in Neural Network Pruning
Feb 17, 2022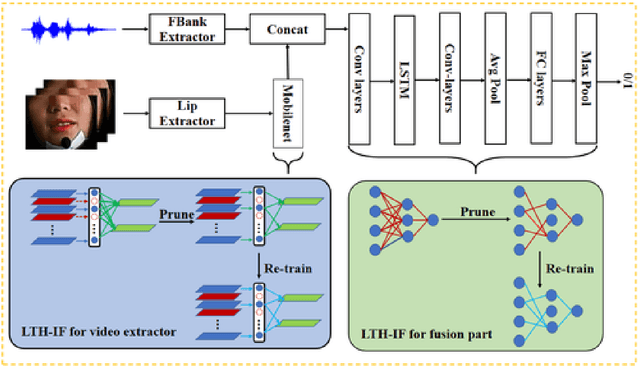
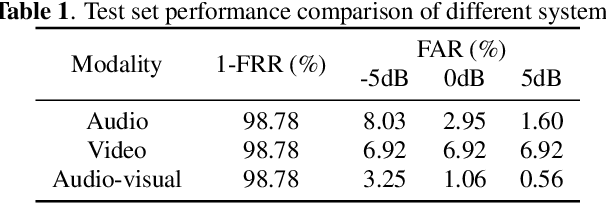
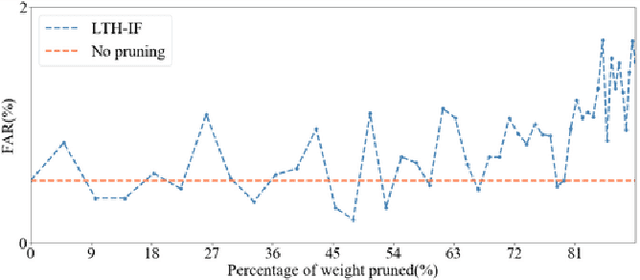
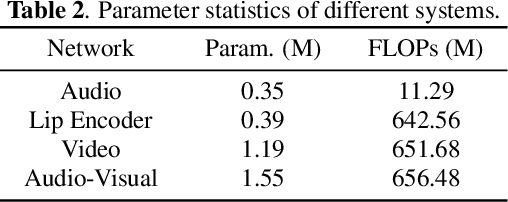
Audio-only-based wake word spotting (WWS) is challenging under noisy conditions due to environmental interference in signal transmission. In this paper, we investigate on designing a compact audio-visual WWS system by utilizing visual information to alleviate the degradation. Specifically, in order to use visual information, we first encode the detected lips to fixed-size vectors with MobileNet and concatenate them with acoustic features followed by the fusion network for WWS. However, the audio-visual model based on neural networks requires a large footprint and a high computational complexity. To meet the application requirements, we introduce a neural network pruning strategy via the lottery ticket hypothesis in an iterative fine-tuning manner (LTH-IF), to the single-modal and multi-modal models, respectively. Tested on our in-house corpus for audio-visual WWS in a home TV scene, the proposed audio-visual system achieves significant performance improvements over the single-modality (audio-only or video-only) system under different noisy conditions. Moreover, LTH-IF pruning can largely reduce the network parameters and computations with no degradation of WWS performance, leading to a potential product solution for the TV wake-up scenario.
Information Fusion in Attention Networks Using Adaptive and Multi-level Factorized Bilinear Pooling for Audio-visual Emotion Recognition
Nov 17, 2021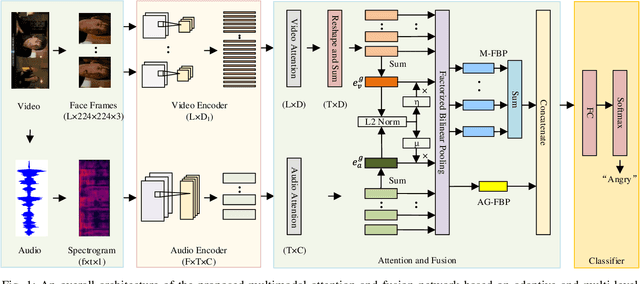
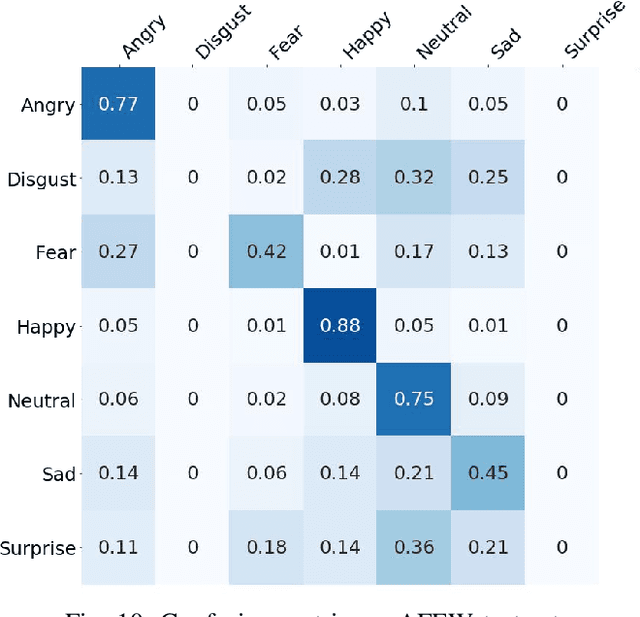
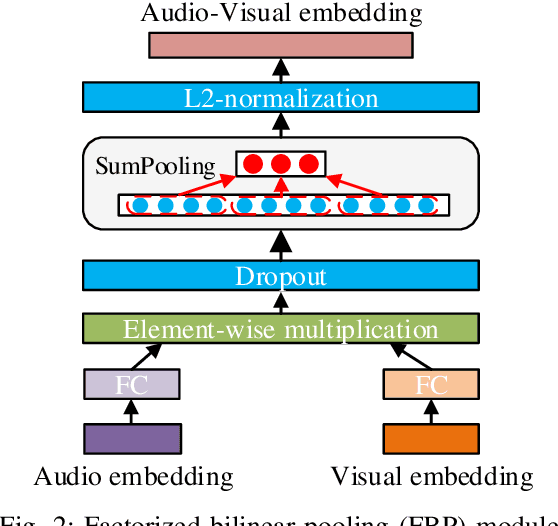

Multimodal emotion recognition is a challenging task in emotion computing as it is quite difficult to extract discriminative features to identify the subtle differences in human emotions with abstract concept and multiple expressions. Moreover, how to fully utilize both audio and visual information is still an open problem. In this paper, we propose a novel multimodal fusion attention network for audio-visual emotion recognition based on adaptive and multi-level factorized bilinear pooling (FBP). First, for the audio stream, a fully convolutional network (FCN) equipped with 1-D attention mechanism and local response normalization is designed for speech emotion recognition. Next, a global FBP (G-FBP) approach is presented to perform audio-visual information fusion by integrating selfattention based video stream with the proposed audio stream. To improve G-FBP, an adaptive strategy (AG-FBP) to dynamically calculate the fusion weight of two modalities is devised based on the emotion-related representation vectors from the attention mechanism of respective modalities. Finally, to fully utilize the local emotion information, adaptive and multi-level FBP (AMFBP) is introduced by combining both global-trunk and intratrunk data in one recording on top of AG-FBP. Tested on the IEMOCAP corpus for speech emotion recognition with only audio stream, the new FCN method outperforms the state-ofthe-art results with an accuracy of 71.40%. Moreover, validated on the AFEW database of EmotiW2019 sub-challenge and the IEMOCAP corpus for audio-visual emotion recognition, the proposed AM-FBP approach achieves the best accuracy of 63.09% and 75.49% respectively on the test set.
Exploring Emotion Features and Fusion Strategies for Audio-Video Emotion Recognition
Dec 27, 2020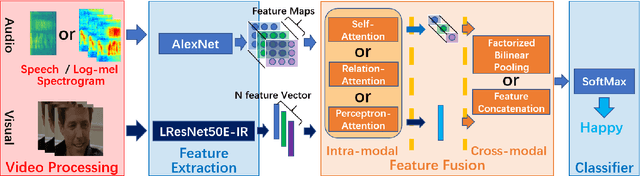
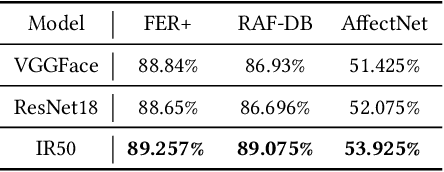
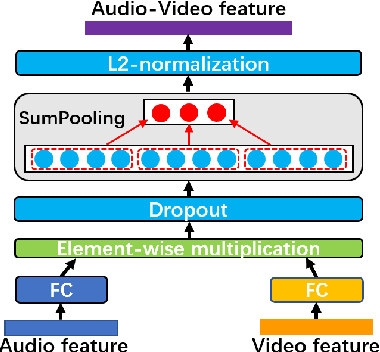
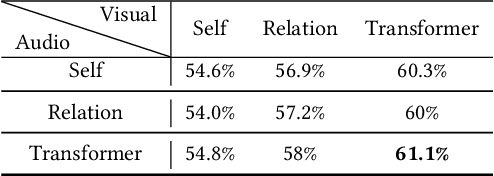
The audio-video based emotion recognition aims to classify a given video into basic emotions. In this paper, we describe our approaches in EmotiW 2019, which mainly explores emotion features and feature fusion strategies for audio and visual modality. For emotion features, we explore audio feature with both speech-spectrogram and Log Mel-spectrogram and evaluate several facial features with different CNN models and different emotion pretrained strategies. For fusion strategies, we explore intra-modal and cross-modal fusion methods, such as designing attention mechanisms to highlights important emotion feature, exploring feature concatenation and factorized bilinear pooling (FBP) for cross-modal feature fusion. With careful evaluation, we obtain 65.5% on the AFEW validation set and 62.48% on the test set and rank third in the challenge.